 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích
Tìm hiểu về kiến trúc của MS SQL Server

Trong các bài trước các bạn đã biết sơ qua về SQL Server, cách cài đặt SQL Server trên máy tính. Trong phần này chúng ta sẽ tìm hiểu về kiến trúc (architecture) của SQL Server.
Chúng ta sẽ phân kiến trúc của SQL Server thành những phần dưới đây để dễ hiểu hơn:
- Kiến trúc chung - General
- Kiến trúc bộ nhớ - Memory
- Kiến trúc file dữ liệu - Data file
- Kiến trúc file nhật ký - Log file
Giờ ta sẽ đi vào chi tiết từng loại kiến trúc SQL Server đã phân loại bên trên nhé.
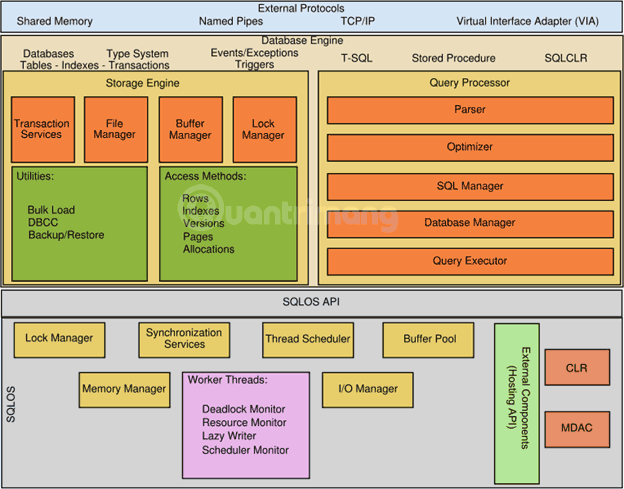
Kiến trúc chung - General
- Client: Nơi khởi tạo yêu cầu.
- Query: Truy vấn SQL là ngôn ngữ bậc cao.
- Logical Units: Keyword, biểu thức, toán tử,...
- N/W Packets: Code liên quan đến mạng.
- Protocols: Trong SQL Server ta có 4 giao thức:
- Shared memory: Dành cho các kết nối cục bộ và mục đích khắc phục sự cố.
- Named pipes: Dành cho những kết nối trong mạng LAN.
- TCP/IP: Dành cho các kết nối với mạng WAN.
- VIA-Virtual Interface Adapter: Yêu cầu phần cứng đặc biệt được thiết lập bởi nhà cung cấp và cũng không được hỗ trợ từ bản SQL 2012.
- Server: Nơi SQL Services được cài đặt và có database.
- Relational Engine: Đây là nơi sự thực hiện (execution) thực sự sẽ được hoàn thành. Nó chứa bộ phân tích Query, tối ưu hóa Query và bộ thực thi Query.
- Query Parser (Command Parser) và Compiler (Translator): 2 thằng này chịu trách nhiệm kiểm tra cú pháp của truy vấn và chuyển đổi truy vấn sang ngôn ngữ của máy.
- Query Optimizer: Nó sẽ chuẩn bị output là Execution Plan bằng cách lấy input là truy vấn, các thống kê và cây Algebrizer.
- Execution Plan: Giống như một bản đồ chỉ đường, chứa thứ tự các bước thực hiện như là một phần của việc thực hiện các truy vấn.
- Query Executor: Đây là nơi truy vấn được thực hiện từng bước một, với sự giúp đỡ của Execution Plan và cũng là nơi Storage Engine sẽ được liên lạc.
- Storage Engine: Chịu trách nhiệm lưu trữ, truy xuất dữ liệu trong hệ thống lưu trữ (ổ đĩa, SAN,...), thao tác dữ liệu, khóa và quản lý các transaction.
- SQL OS: Nằm giữa máy host (Windows OS) và SQL Server. Tất cả các hoạt động được thực hiện trên engine cơ sở dữ liệu được "chăm sóc" bởi SQL OS. SQL OS cung cấp các dịch vụ hệ điều hành khác nhau, chẳng hạn như hoạt động quản lý bộ nhớ với buffer pool, log buffer, phát hiện deadlock (khóa chết) bằng cách sử dụng cấu trúc block và lock.
- Checkpoint: Checkpoint là một tiến trình nội bộ, ghi tất cả các trang đã sửa đổi (gọi là Dirty Page) từ Buffer Cache vào ổ đĩa vật lý. Ngoài ra, nó cũng ghi các bản log từ Log Buffer vào file vật lý. Việc ghi lại các Dirty Page vào ổ đĩa còn được biết đến như là Hardening of dirty pages (cứng hóa các Dirty Page).
- Lazy Writer: Lazy Writer sẽ đẩy các Dirty Page và ổ cứng vì một lý do hoàn toàn khác, đó là giải phóng bộ nhớ trong Buffer Pool. Điều này xảy ra khi SQL Server đang bị thiếu bộ nhớ. Tiến trình này được kiểm soát bởi một tiến trình Internal và không có thiết lập cho nó.
SQL Server liên tục giám sát việc sử dụng bộ nhớ để đánh giá tính khả dụng và mức cạnh tranh tài nguyên, giúp đảm bảo luôn có sẵn một dung lượng trống nhất định. Khi phát hiện bất kỳ sự xung đột tài nguyên nào, nó sẽ kích hoạt Lazy Writer để chuyển một số Dirty Page vào ổ đĩa và giải phóng bộ nhớ. Nó sử dụng thuật toán Least Recently Used (LRU) để quyết định trang nào sẽ được đẩy vào ổ cứng. Nếu Lazy Writer luôn hoạt động, nó có thể tạo ra nút thắt cổ chai với bộ nhớ.
Kiến trúc bộ nhớ - Memory
Sau đây là những tính năng nổi bật của kiến trúc bộ nhớ:
- Một trong những mục tiêu thiết kế cơ bản của tất cả phần mềm cơ sở dữ liệu là giảm thiểu I/O ổ đĩa vì quá trình đọc và ghi đĩa là một trong những hành động sử dụng nhiều tài nguyên nhất.
- Bộ nhớ trong Windows có thể được gọi với Virtual Address Space, được chia sẻ bởi chế độ Kernel (chế độ OS) và User (ứng dụng như SQL Server).
- User address space của SQL Server được chia thành 2 phần: MemToLeave và Buffer Pool.
- Kích thước của MemToLeave (MTL) và Buffer Pool (BPool) được quyết định bởi SQL Server trong quá trình khởi động.
- Buffer Management là một thành phần quan trọng nếu muốn đạt được hiệu suất I/O cao. Nó bao gồm 2 cơ chế: Buffer Manager để truy cập và cập nhật các trang cơ sở dữ liệu và Buffer Pool để cắt giảm I/O file vào database.
- Buffer Pool được chia thành nhiều phần, quan trọng nhất là Buffer Cache và Procedure Cache. Buffer Cache giữ các trang dữ liệu trong bộ nhớ để những dữ liệu thường xuyên truy cập có thể trích xuất từ bộ nhớ cache. Quá trình thay thế sẽ đọc các trang dữ liệu từ ổ đĩa. Đọc dữ liệu từ cache sẽ tối ưu hóa hiệu suất bằng cách giảm thiểu số lượng các thao tác I/O, vốn chậm hơn so với truy xuất dữ liệu từ bộ nhớ.
- Procedure Cache giữ các thủ tục được lưu trữ và các Excecution Plan để tối ưu hóa số lần Excecution Plan được tạo. Bạn có thể tìm thấy thông tin về dung lượng và hoạt động trong Procedure Cache sử dụng lệnh DBCC PROCCACHE.
- Các phần khác của Buffer Pool bao gồm:
- Các cấu trúc dữ liệu mức hệ thống: Chứa dữ liệu mức Instance về cơ sở dữ liệu, khóa.
- Log Cache: Dành riêng cho việc đọc và ghi các trang transaction.
- Connection Context: Mỗi kết nối với Instance có một vùng nhỏ bộ nhớ để ghi trạng thái hiện tại của kết nối. Thông tin này bao gồm thủ tục được lưu trữ và các thông số hàm do người dùng xác định, vị trí con trỏ chuột và nhiều hơn nữa.
- Stack Space: Windows phân bổ stack space cho mỗi luồng được bắt đầu với SQL Server.
Kiến trúc file dữ liệu - Data file
Kiến trúc này có các thành phần sau:
File Group:
Các file cơ sở dữ liệu có thể nhóm lại với nhau thành các nhóm file để phân bổ và quản lý theo mục đích. Một file chỉ có thể là thành viên của một nhóm file. Các file log không thể nhóm vào File Group vì dung lượng file log được quản lý riêng biệt với dung lượng dữ liệu.
Có hai loại File Group trong SQL Server là Primary và User-defined. Primary chứa các file dữ liệu chính và bất kỳ file nào không được gán cụ thể cho File Group khác. Tất cả các trang cho bảng hệ thống được cấp phát trong Primary. User-defined là các nhóm file do người dùng định nghĩa, nó được chỉ định bằng cách sử dụng từ khóa file group trong lệnh tạo cơ sở dữ liệu hoặc xóa cơ sở dữ liệu.
Một File Group trong mỗi cơ sở dữ liệu hoạt động như nhóm file mặc định. Khi SQL Server chỉ định một trang cho bảng hoặc chỉ mục (không nằm trong File Group nào khi tạo) thì trang đó sẽ nằm trong nhóm file mặc định. Để chuyển đổi nhóm file mặc định từ File Group này sang File Group khác, cần có db_owner fixed database role.
Primary là nhóm tệp mặc định. User cần có db_owner fixed database role để sao lưu tập tin và những nhóm file riêng lẻ.
File
Cơ sở dữ liệu có 3 loại file Primary (file dữ liệu chính), Secondary (file dữ liệu phụ) và Log (file nhật ký). Primary là điểm bắt đầu của cơ sở dữ liệu và trỏ đến các file khác trong cơ sở dữ liệu.
Mỗi cơ sở dữ liệu có một Primary. Bạn có thể đặt phần mở rộng cho các file dữ liệu chính là gì cũng được, nhưng khuyến nghị là nên để .mdf. File dữ liệu phụ là file khác file dữ liệu chính. Một cơ sở dữ liệu có thể có nhiều hoặc chỉ có một file dữ liệu phụ. Phần mở rộng cho file dữ liệu phụ nên đặt là .ndf.
Các file log giữ tất cả thông tin được sử dụng để phục hồi cơ sở dữ liệu. Cơ sở dữ liệu phải có ít nhất một file log. Chúng ta có thể có nhiều file log cho một cơ sở dữ liệu. Phần mở rộng nên đặt là .ldf.
Vị trí của tất cả các file trong cơ sở dữ liệu được ghi lại trong cả cơ sở dữ liệu tổng thể và file Primary của cơ sở dữ liệu. Trong hầu hết trường hợp, công cụ cơ sở dữ liệu sử dụng vị trí file từ cơ sở dữ liệu tổng thể.
File có 2 tên là Logical và Physical. Logical được sử dụng để tham chiếu đến file trong tất cả các lệnh T-SQL. Tên Physical là OS_file_name, nó phải tuân theo quy tắc của hệ điều hành. File dữ liệu và file log có thể được đặt trên hệ thống file FAT hoặc NTFS, nhưng không thể đặt trên các hệ thống file nén. Có thể có tối đa 32.767 file trong một cơ sở dữ liệu.
Extent
Extent là một đơn vị cơ bản trong đó không gian được phân bổ cho mỗi bảng, chỉ mục. Mỗi Extent là 8 trang liền kề hoặc 64KB. SQL Server có 2 loại Extent là Uniform và Mixed. Uniform được tạo thành từ một object duy nhất, Mixed được tạo thành từ tối đa 8 object.
Page
Page (trang) là đơn vị cơ bản trong lưu trữ dữ liệu của SQL Server. Kích thước của một trang là 8KB. Bắt đầu mỗi trang là 96byte tiêu đề, được sử dụng để lưu trữ thông tin hệ thống như loại trang, số lượng không gian trống trên trang và ID của đối tượng sở hữu trang. Có 9 loại trang dữ liệu trong SQL Server:
- Data: Các hàng dữ liệu với tất cả dữ liệu từ text, ntext và ảnh.
- Index: Các mục chỉ mục.
- Tex\Image: Dữ liệu text, ntext và ảnh.
- GAM: Thông tin về extent được chỉ định.
- SGAM: Thông tin về extent được cấp phát ở mức hệ thống.
- Page Free Space (PFS): Thông tin về không gian trống hiện có trên các trang.
- Index Allocation Map (IAM): Thông tin về extent được sử dụng bởi bảng hoặc chỉ mục.
- Bulk Changed Map (BCM): Thông tin về extent được sử đổi bởi hoạt động hàng loạt kể từ lệnh ghi sao lưu cuối cùng.
- Differential Changed Map (DCM): Thông tin về extent đã thay đổi kể từ lệnh sao lưu cơ sở dữ liệu cuối cùng.
Kiến trúc file nhật ký - Log file
Các log transaction trên SQL Server hoạt động hợp lý khi nó là chuỗi các bản ghi log. Mỗi bản ghi log được xác định bởi Log Sequence Number (LSN), chứa ID của transaction mà nó thuộc về.
Log ghi lại những sửa đổi dữ liệu hoặc các hoạt động được thực hiện hay lấy hình ảnh trước và sau khi dữ liệu bị chỉnh sửa. Hình ảnh trước là bản sao của dữ liệu trước khi thao tác được thực hiện, hình ảnh sau là bản sao của dữ liệu sau khi thao tác đã được thực hiện.
Các bước để phục hồi một hoạt động phụ thuộc vào loại bản ghi log.
- Thao tác logic được log.
- Để đi tới thao tác logic ở trước, thao tác sẽ được thực hiện lại.
- Để quay lại thao tác logic phía sau, thao tác logic đảo ngược sẽ được thực hiện.
- Ảnh trước và sau được log.
- Để đi tới thao tác ở trước, ảnh sau sẽ được áp dụng.
- Để quay lại thao tác phía sau, ảnh trước sẽ được áp dụng.
Các thao tác khác nhau đã được ghi lại trong bản log transaction. Những thao tác sau sẽ có trong đó:
- Bắt đầu và kết thúc mỗi transaction.
- Mọi sửa đổi dữ liệu (chèn, cập nhật, xóa), bao gồm các thay đổi các thủ tục lưu trữ hệ thống hoặc lệnh ngôn ngữ định nghĩa dữ liệu (DDL) đến bảng, bao gồm cả bảng hệ thống.
- Mọi extent và phân bổ, hủy phân bổ trang.
- Tạo hoặc xóa bảng, chỉ mục.
Các thao tác rollback cũng được log lại. Mỗi transaction sẽ giữ một khoảng không gian trong bản log để chắc chắn rằng có đủ không gian log cần thiết cho rollback thực hiện lệnh hoặc thông báo lỗi. Không gian này sẽ được giải phóng khi transaction hoàn tất.
Phần của file log từ bản log đầu tiên (bắt buộc phải có để khôi phục lại toàn bộ cơ sở dữ liệu thành công) đến bản log cuối cùng được gọi là phần hoạt động của log hay log hoạt động. Đây là phần bản log bắt buộc để có thể phục hồi cơ sở dữ liệu đầy đủ. Không có phần nào trong log hoạt động được cắt xén. LSN của bản ghi log đầu tiên được gọi là LSN phục hồi tối thiểu (Min LSN).
SQL Server Database Engine chia mỗi file log Physical thành một số file log ảo. File log ảo không có kích thước cố định và không có số lượng file log ảo cố định cho mỗi file log Physical.
Database Engine chọn dung lượng cho file log ảo một cách tự động khi nó tạo hoặc mở rộng file log. Database Engine cố duy trì số lượng file ảo nhỏ. Kích thước của file log ảo không thể cấu hình hay thiết lập bởi quản trị viên. Duy nhất chỉ có khi file log Physical được xác định kích thước nhỏ và giá trị growth_increment thì file log ảo mới ảnh hưởng đến hiệu suất hệ thống.
Giá trị kích thước là kích thước khởi tạo cho file log và growth_increment là lượng không gian được thêm cho file mỗi khi file yêu cầu thêm không gian mới. Khi file log đạt đến kích thước lớn vì có nhiều sự gia tăng nhỏ, chúng sẽ có nhiều file log ảo. Điều này có thể làm chậm quá trình khởi động database và các hoạt động sao lưu, phục hồi log.
Lời khuyên là bạn nên gán cho file log giá trị kích thước gần với kích thước cuối cùng được yêu cầu và giá trị growth_increment tương đối lớn. SQL Server sử dụng write-ahead log (WAL), đảm bảo rằng không có sự sửa đổi dữ liệu nào được ghi vào ổ đĩa trước khi bản log liên quan được ghi vào ổ đĩa. Điều này giúp duy trì các thuộc tính ACID cho transaction.
Algebrizer trong SQL
Mình muốn nói về Algebrizer một chút: Algebrizer là một tiến trình trong quá trình thực hiện truy vấn. Nó bắt đầu làm việc sau Parser. Khi Query Parser tìm thấy một truy vấn đúng cú pháp, nó sẽ chuyển đến cho Algebrizer và công việc của Algebrizer bắt đầu:. Algebrizer chịu trách nhiệm xác minh các object và tên cột (mà bạn đã cung cấp trong truy vấn hoặc đang được tham chiếu bởi truy vấn). Ví dụ, nếu tên cột bị viết sai trong truy vấn, Algebrizer phải có trách nhiệm xác nhận điều đó và tạo ra lỗi. Algebrizer cũng xác định tất cả các loại dữ liệu đang được xử lý trong một truy vấn nhất định. Algebrizer xác minh xem GROUP BY và những cột đã gộp có được đặt đúng nơi hay không. Ví dụ, nếu bạn viết truy vấn sau và chỉ nhấn Ctrl + F5 để phân tích cú pháp thì không xuất hiện lỗi. Nhưng nếu nhấn F5 để chạy truy vấn thì Algebrizer sẽ làm việc và trả về lỗi.
USE AdventureWorksGOSELECT MakeFlag,SUM(ListPrice)FROM Production.ProductGROUP BYProductNumber
Checkpoint trong SQL Server
Trong SQL Server 2012 có 4 loại checkpoint:
- Automatic: Loại này là checkpoint phổ biến nhất, chạy dưới dạng một tiến trình nền để chắc chắn SQL Server Database có thể được phục hồi trong khoảng thời gian được xác định bởi Recovery Interval trong Server Configuration Option.
- Indirect: Loại checkpoint này mới có trên SQL Server 2012. Nó cũng là tiến trình chạy nền nhưng chỉ dành cho một số user cụ thể xác định thời gian phục hồi cho database cụ thể trong tùy chọn cấu hình. Khi Target_Recovery_Time cho database cụ thể được chọn, nó sẽ ghi đè lên Recovery Interval được chỉ định cho máy chủ, tránh Automatic checkpoint trên database đó.
- Manual: Checkpoint này chạy giống như bất kỳ lệnh SQL nào khác, khi bạn tạo lệnh checkpoint, nó sẽ chạy để hoàn thành. Checkpoint này chỉ chạy trên database hiện tại. Bạn có thể xác định Checkpoint_Duration trong tùy chọn để chỉ ra khoảng thời gian bạn muốn checkpoint được hoàn thành.
- Internal: Khi là một user, bạn không thể kiểm soát loại checkpoint này trong những hành động cụ thể như:
- Ngắt khởi động một hành động checkpoint trên tất cả các database trừ khi việc shutdown bị lỗi, không bình thường (dùng lệnh Shutdown with nowith).
- Khi mô hình phục hồi bị thay đổi từ Full\Bulk-logged sang Simple.
- Trong khi đang sao lưu cơ sở dữ liệu.
- Nếu database đang ở trong kiểu phục hồi Simple, quá trình checkpoint sẽ tự động thực hiện hoặc khi bản log đã đầy 70%, hoặc dựa trên tùy chọn Recovery Interval của Server.
- Lệnh ALTER DATABASE để thêm hoặc xóa file log/dữ liệu cũng khởi tạo một checkpoint.
- Checkpoint cũng diễn ra khi mô hình phục hồi của database là Bulk-logged và hoạt động ghi tối thiểu được thực hiện.
Đây có lẽ là phần "khoai" nhất trong SQL Server, nhưng thiết nghĩ nắm được kiến trúc của nó sẽ giúp cho việc hiểu mọi thứ được vận hành ra sao, nếu có lỗi phát sinh thì nó nằm ở phần nào,... từ đó giúp cho quá trình làm việc với cơ sở dữ liệu cũng dễ dàng hơn.
Trong phần tới, chúng ta sẽ tìm hiểu về Management Studio và đi dần vào những lệnh cơ bản của SQL Server.
Bài trước: Hướng dẫn cài đặt MS SQL Server
Bài tiếp: Quản lý MS SQL Server bằng Management Studio
Bạn đừng bỏ qua chuyên mục SQL trên Quantrimang.com nhé!
Bạn nên đọc







Theo Nghị định 147/2024/ND-CP, bạn cần xác thực tài khoản trước khi sử dụng tính năng này. Chúng tôi sẽ gửi mã xác thực qua SMS hoặc Zalo tới số điện thoại mà bạn nhập dưới đây:
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học