 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Meta phát hành Llama 2 vào mùa hè năm 2023. Phiên bản mới của Llama được tinh chỉnh với số lượng token nhiều hơn 40% so với mô hình Llama ban đầu, tăng gấp đôi độ dài ngữ cảnh và vượt trội đáng kể so với các mô hình nguồn mở khác hiện có. Cách nhanh chóng và dễ dàng nhất để truy cập Llama 2 là thông qua API qua nền tảng trực tuyến. Tuy nhiên, nếu bạn muốn có trải nghiệm tốt nhất thì cài đặt và tải Llama 2 trực tiếp trên máy tính là hiệu quả nhất.
Với ý nghĩ đó, Quantrimang.com đã tạo hướng dẫn từng bước về cách sử dụng Text-Generation-WebUI để tải Llama 2 LLM cục bộ trên máy tính của bạn.
Tại sao lại cài đặt Llama 2 cục bộ?
Có nhiều lý do khiến mọi người chọn chạy trực tiếp Llama 2. Một số người làm điều đó vì lo ngại về quyền riêng tư, một số để tùy chỉnh và một số khác vì khả năng ngoại tuyến. Nếu bạn đang nghiên cứu, tinh chỉnh hoặc tích hợp Llama 2 cho dự án của mình thì việc truy cập Llama 2 qua API có thể không dành cho bạn. Mục đích của việc chạy LLM cục bộ trên PC là giảm sự phụ thuộc vào các công cụ AI của bên thứ ba và sử dụng AI mọi lúc, mọi nơi mà không lo rò rỉ dữ liệu nhạy cảm cho các công ty và tổ chức khác.
Như đã nói, hãy bắt đầu với hướng dẫn từng bước để cài đặt Llama 2 cục bộ.
Cách tải và cài đặt Llama 2 cục bộ
Bước 1: Cài đặt Visual Studio 2019 Build Tool
Để đơn giản hóa mọi thứ, chúng ta sẽ sử dụng trình cài đặt bằng một cú nhấp chuột cho Text-Generation-WebUI (chương trình được sử dụng để tải Llama 2 bằng GUI). Tuy nhiên, để trình cài đặt này hoạt động, bạn cần tải xuống Visual Studio 2019 Build Tool và cài đặt các tài nguyên cần thiết.
Tải Visual Studio 2019 (Miễn phí)
- Hãy tiếp tục và tải xuống phiên bản cộng đồng của phần mềm.
- Bây giờ, hãy cài đặt Visual Studio 2019, sau đó mở phần mềm lên. Sau khi mở, hãy đánh dấu vào ô Desktop development with C++ và nhấn Install.
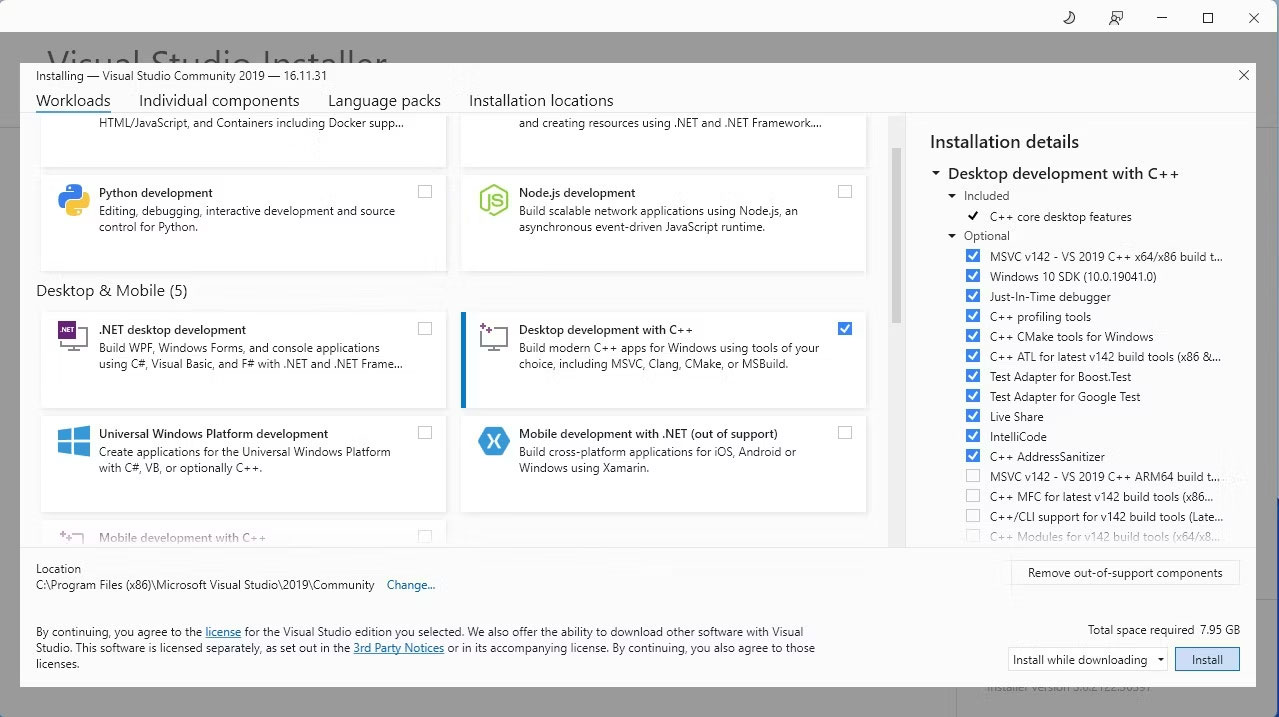
Bây giờ, bạn đã cài đặt bản Desktop development with C++, đã đến lúc tải xuống trình cài đặt một cú nhấp chuột Text-Generation-WebUI.
Bước 2: Cài đặt Text-Generation-WebUI
Trình cài đặt một cú nhấp chuột Text-Generation-WebUI là một script tự động tạo các thư mục cần thiết và thiết lập môi trường Conda cũng như tất cả những yêu cầu cần thiết để chạy mô hình AI.
Để cài đặt script, hãy tải xuống trình cài đặt bằng một cú nhấp chuột bằng cách nhấp vào Code > Download ZIP.
Tải trình cài đặt Text-Generation-WebUI (Miễn phí)
1. Sau khi tải xuống, hãy giải nén file ZIP vào vị trí ưa thích của bạn, sau đó mở thư mục đã giải nén.
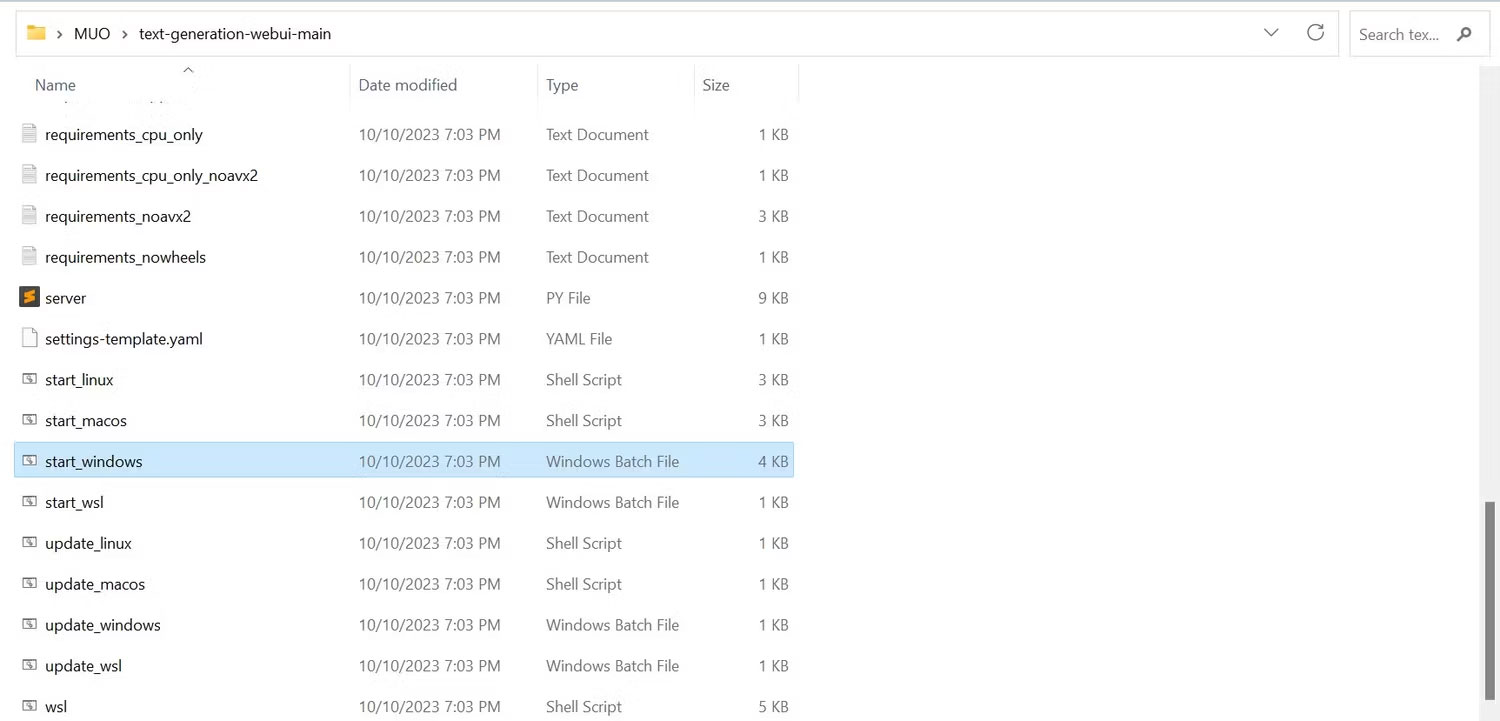
2. Trong thư mục, cuộn xuống và tìm chương trình khởi động thích hợp cho hệ điều hành của bạn. Chạy chương trình bằng cách nhấp đúp vào script thích hợp.
- Nếu bạn đang dùng Windows, hãy chọn file batch start_windows
- Đối với MacOS, chọn script shell start_macos
- Đối với Linux, script shell start_linux.
3. Phần mềm diệt virus của bạn có thể tạo cảnh báo; điều này ổn. Lời nhắc chỉ là một thông báo giả về phần mềm diệt virus khi chạy một file batch hoặc script. Bấm vào Run anyway.
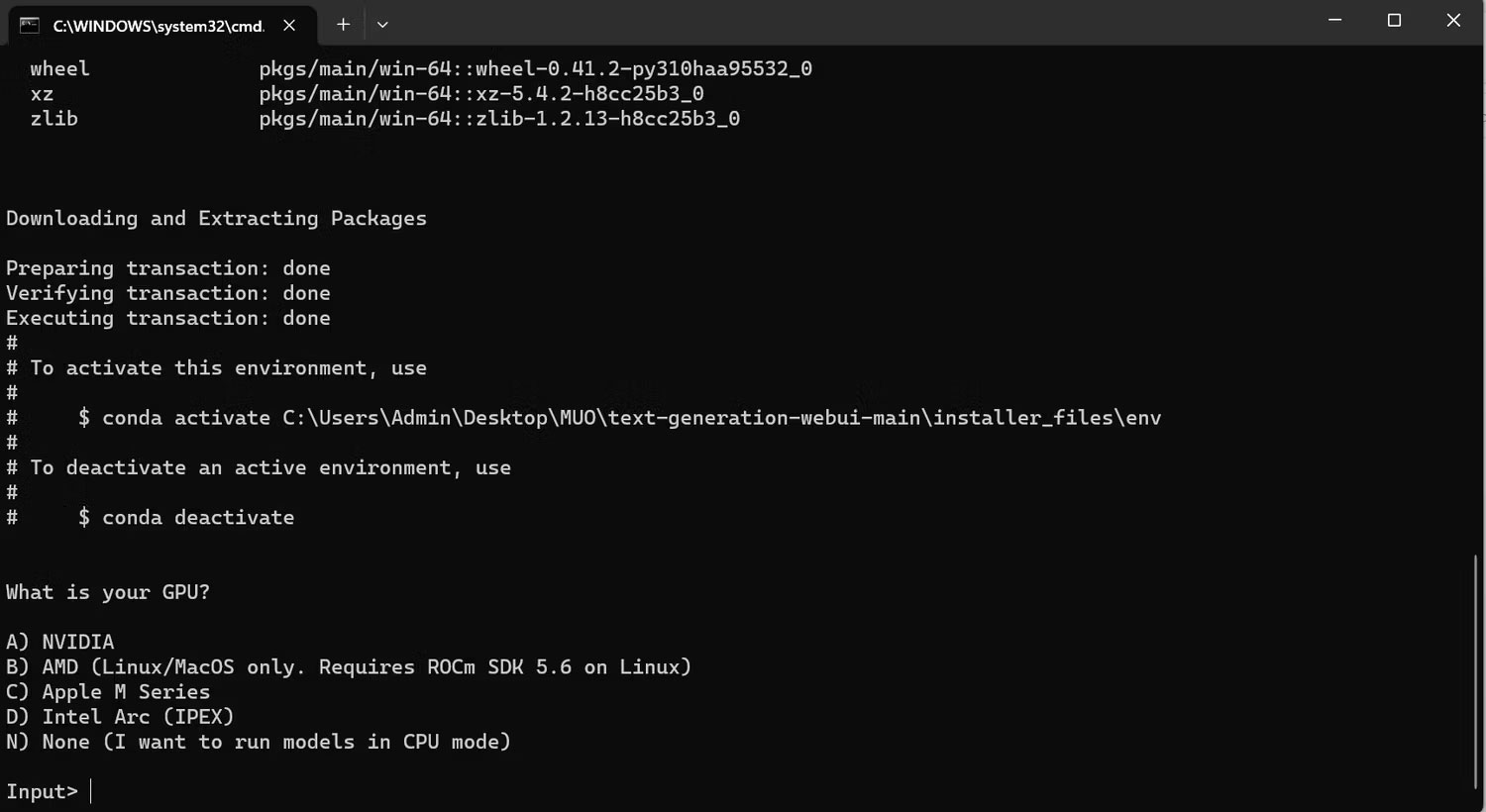
4. Một terminal sẽ mở ra và bắt đầu thiết lập. Ngay từ đầu, quá trình thiết lập sẽ tạm dừng và hỏi bạn đang sử dụng GPU nào. Chọn loại GPU thích hợp được cài đặt trên máy tính của bạn và nhấn Enter. Đối với những máy không có card đồ họa chuyên dụng, hãy chọn None (I want to run models in CPU mode). Hãy nhớ rằng chạy trên chế độ CPU chậm hơn nhiều so với chạy mô hình có GPU chuyên dụng.
5. Sau khi thiết lập hoàn tất, bây giờ bạn có thể khởi chạy Text-Generation-WebUI cục bộ. Bạn có thể làm như vậy bằng cách mở trình duyệt web ưa thích của mình và nhập địa chỉ IP được cung cấp trên URL.
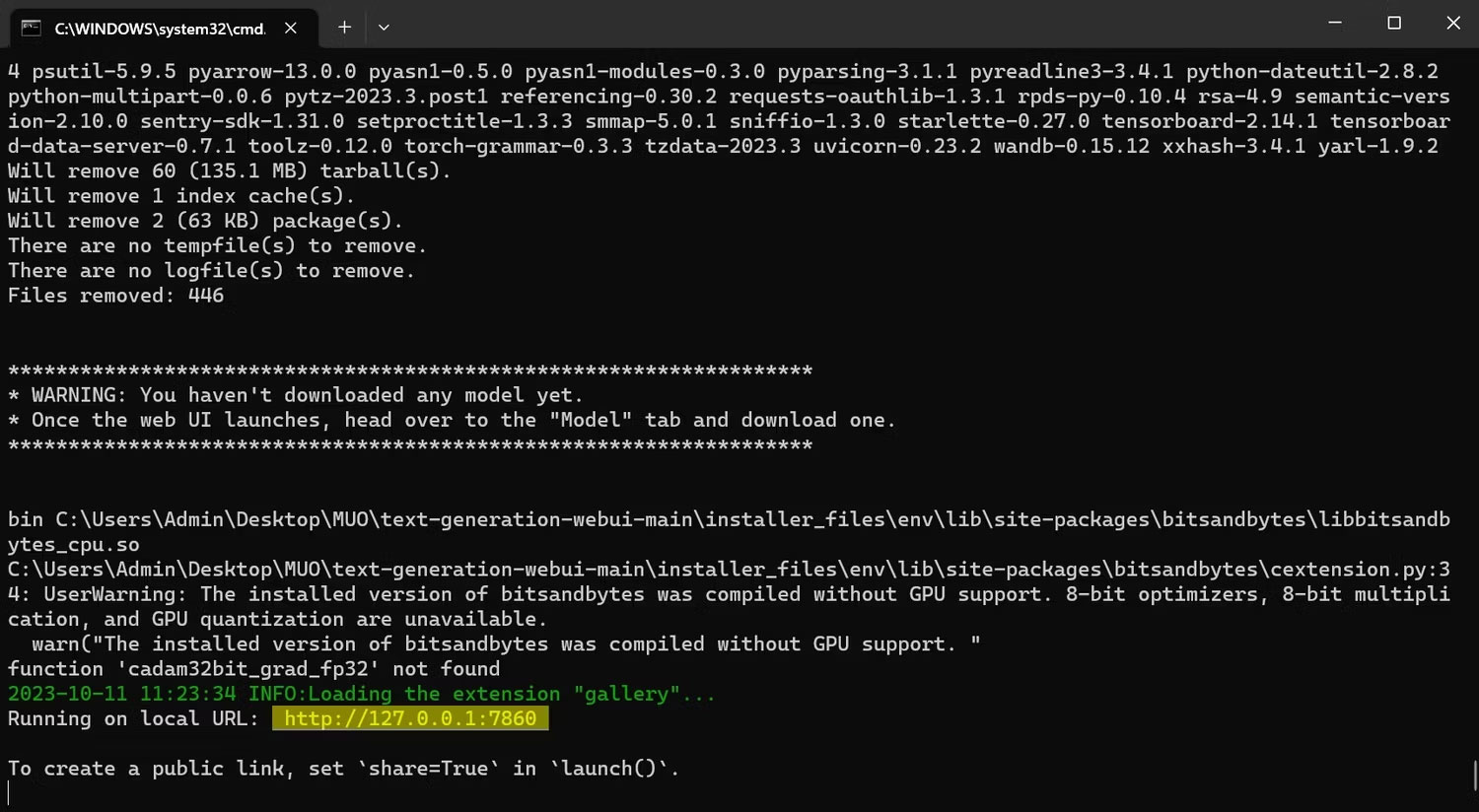
6. WebUI hiện đã sẵn sàng để sử dụng.
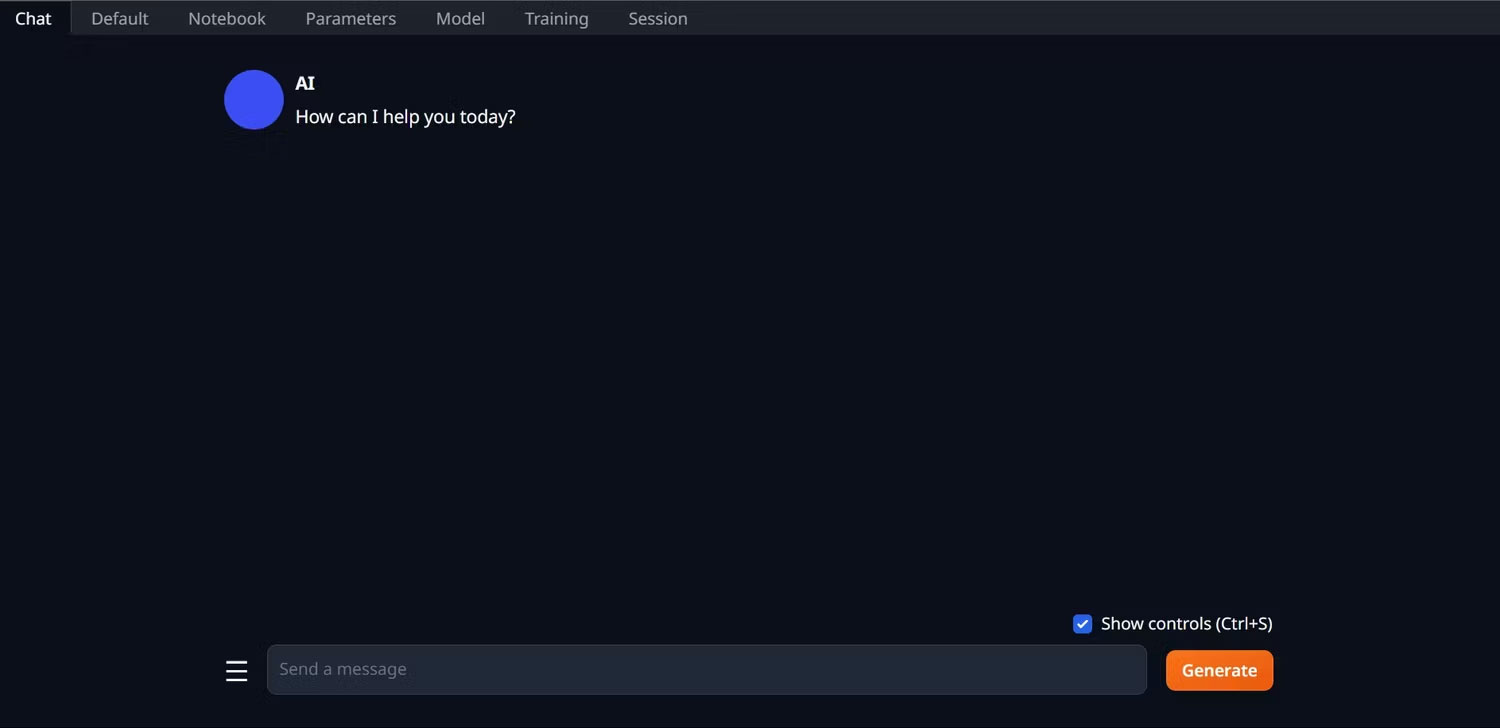
7. Tuy nhiên, chương trình chỉ là một model loader. Hãy tải xuống Llama 2 để model loader khởi chạy.
Bước 3: Tải xuống mô hình Llama 2
Có khá nhiều điều cần cân nhắc khi quyết định bạn cần phiên bản Llama 2 nào. Chúng bao gồm các tham số, lượng tử hóa, tối ưu hóa phần cứng, kích thước và cách sử dụng. Tất cả thông tin này sẽ được ghi rõ trong tên của model.
- Tham số: Số lượng tham số được sử dụng để huấn luyện mô hình. Các thông số lớn hơn tạo ra các mô hình có khả năng cao hơn nhưng phải trả giá bằng hiệu năng.
- Cách sử dụng: Có thể là tiêu chuẩn hoặc trò chuyện. Mô hình trò chuyện được tối ưu hóa để sử dụng làm chatbot như ChatGPT, trong khi tiêu chuẩn là mô hình mặc định.
- Tối ưu hóa phần cứng: Đề cập đến phần cứng nào chạy mô hình tốt nhất. GPTQ có nghĩa là mô hình được tối ưu hóa để chạy trên GPU chuyên dụng, trong khi GGML được tối ưu hóa để chạy trên CPU.
- Lượng tử hóa: Biểu thị độ chính xác của trọng số và kích hoạt trong mô hình. Để suy luận, độ chính xác q4 là tối ưu.
- Kích thước: Đề cập đến kích thước của mô hình cụ thể.
Lưu ý rằng một số model có thể được sắp xếp khác nhau và thậm chí có thể không hiển thị cùng loại thông tin. Tuy nhiên, kiểu quy ước đặt tên này khá phổ biến trong thư viện HuggingFace Model, vì vậy nó vẫn đáng để tìm hiểu.

Trong ví dụ này, mô hình có thể được xác định là mô hình Llama 2 cỡ trung bình được đào tạo trên 13 tỷ tham số được tối ưu hóa cho hoạt động suy luận trò chuyện bằng CPU chuyên dụng.
Đối với những người chạy trên GPU chuyên dụng, hãy chọn model GPTQ, trong khi đối với những người sử dụng CPU, hãy chọn GGML. Nếu bạn muốn trò chuyện với mô hình giống như với ChatGPT, hãy chọn chat, nhưng nếu bạn muốn thử nghiệm mô hình với đầy đủ khả năng của nó, hãy sử dụng mô hình standard. Đối với các thông số, hãy biết rằng việc sử dụng các mô hình lớn hơn sẽ mang lại kết quả tốt hơn nhưng lại phải trả giá bằng hiệu suất. Bài viết khuyên bạn nên bắt đầu với mô hình 7B. Đối với lượng tử hóa, hãy sử dụng q4 vì nó chỉ dành cho suy luận.
Tải GGML (Miễn phí) Tải GPTQ (Miễn phí)
Bây giờ, bạn đã biết mình cần phiên bản Llama 2 nào, hãy tiếp tục và tải xuống mô hình bạn muốn.
Ví dụ đang chạy ứng dụng này trên ultrabook nên sẽ sử dụng mô hình GGML được tinh chỉnh để trò chuyện, llama-2-7b-chat-ggmlv3.q4_K_S.bin.
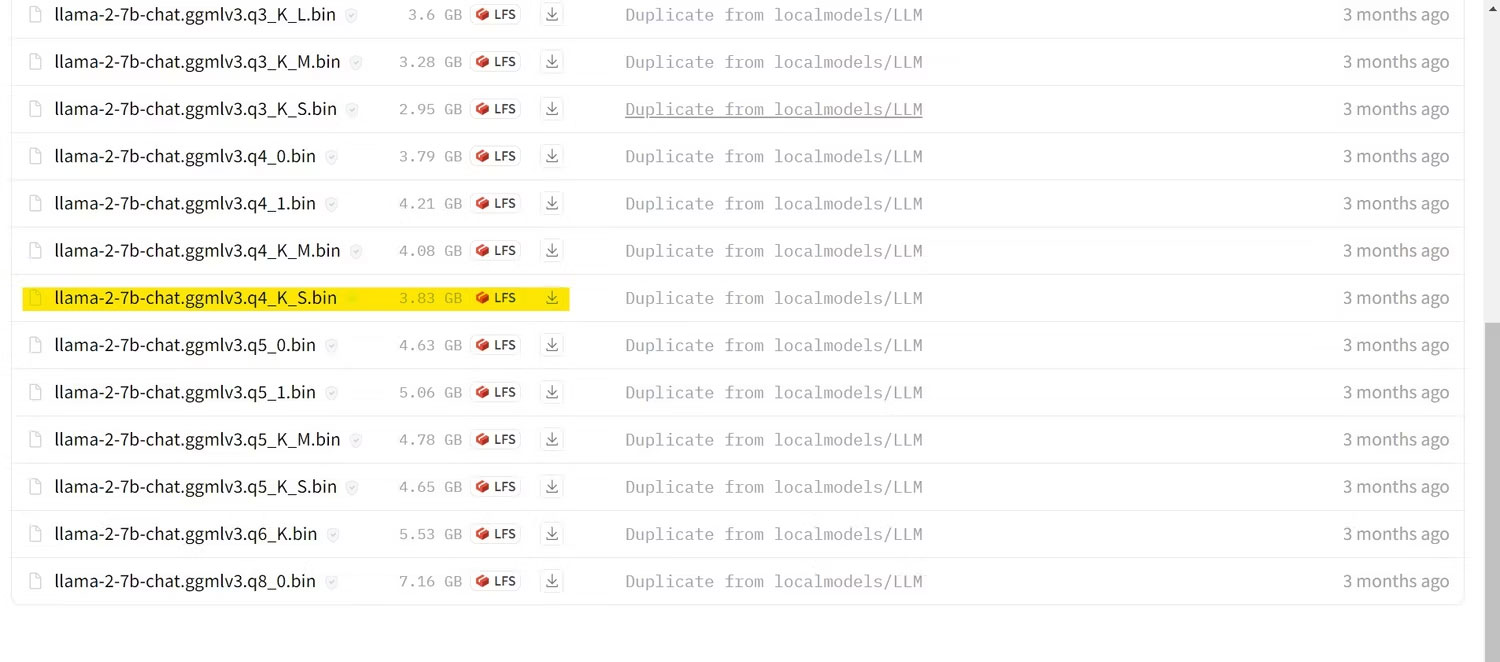
Sau khi quá trình tải xuống hoàn tất, hãy đặt mô hình vào text-generation-webui-main > models.

Bây giờ, bạn đã tải xuống mô hình của mình và đặt vào thư mục models, đã đến lúc cấu hình model loader.
Bước 4: Cấu hình Text-Generation-WebUI
Bây giờ, hãy bắt đầu giai đoạn cấu hình.
1. Một lần nữa, hãy mở Text-Generation-WebUI bằng cách chạy file start_(your OS) (xem các bước trước đó ở trên).
2. Trên các tab nằm phía trên GUI, nhấp vào Model. Nhấp vào nút refresh ở menu drop-down mô hình và chọn mô hình của bạn.
3. Bây giờ, hãy nhấp vào menu drop-down của model loader và chọn AutoGPTQ cho những người sử dụng mô hình GTPQ và ctransformers cho những người sử dụng mô hình GGML. Cuối cùng, nhấp vào Load để load mô hình của bạn.
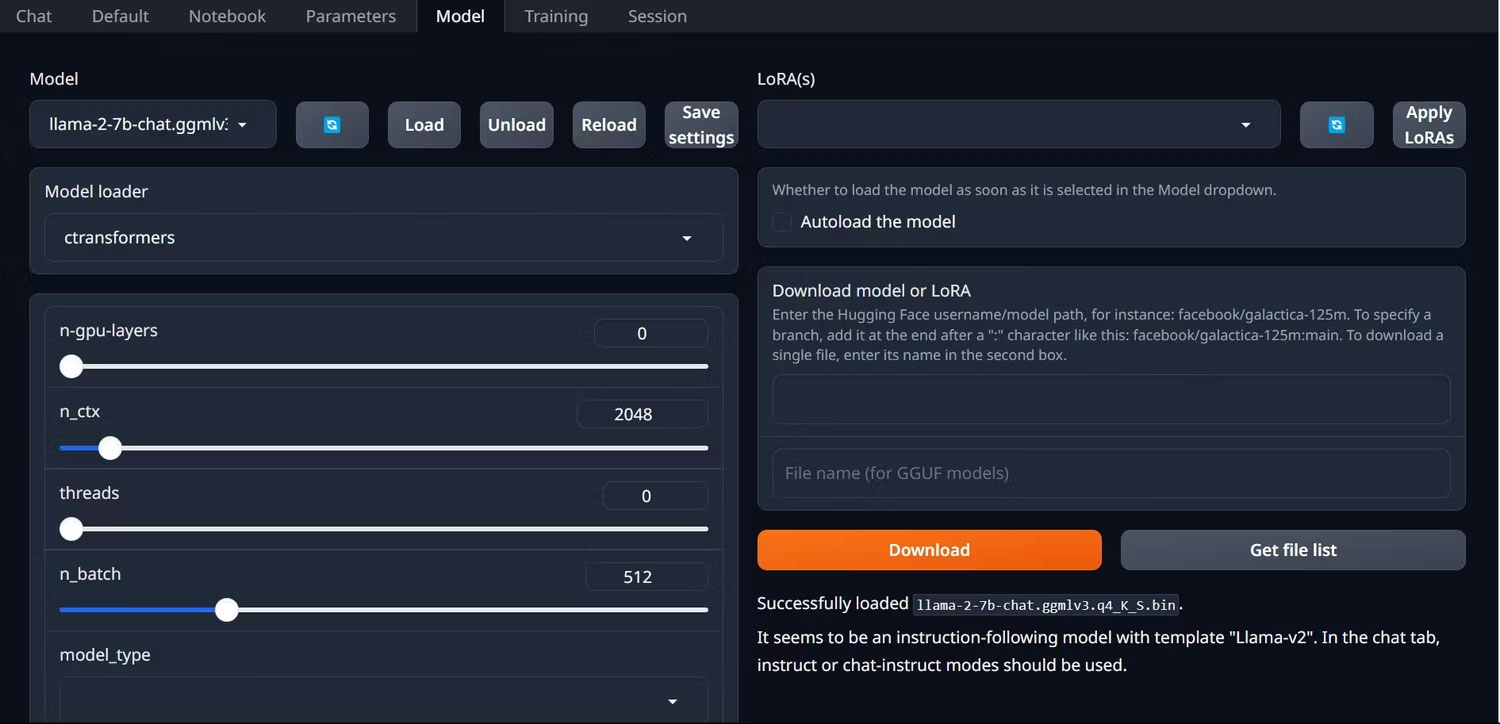
4. Để sử dụng mô hình, hãy mở tab Chat và bắt đầu thử nghiệm mô hình.
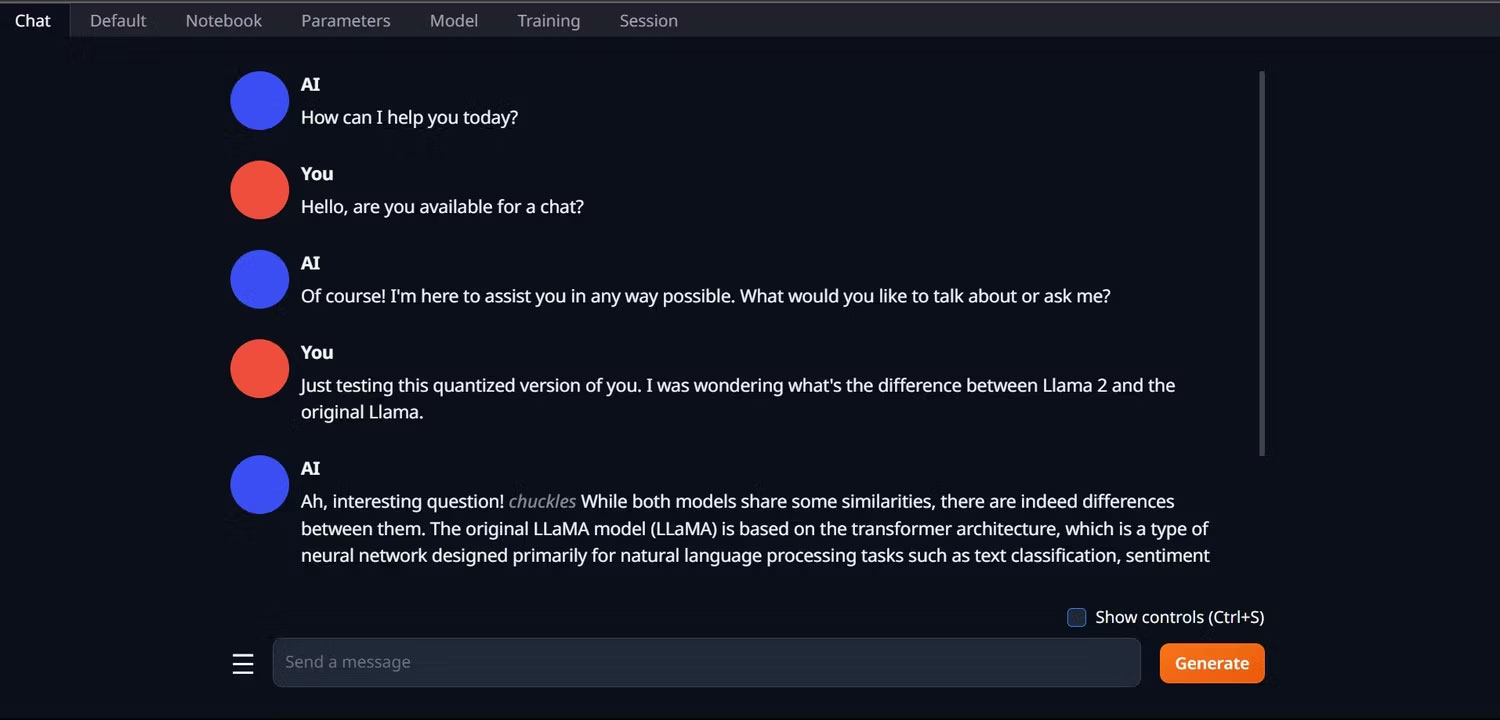
Xin chúc mừng, bạn đã load thành công Llama2 trên máy tính cục bộ của mình!








 Ứng dụng
Ứng dụng
 Thương mại Điện tử
Thương mại Điện tử
 Nhạc, phim, truyện online
Nhạc, phim, truyện online
 Phần mềm học tập
Phần mềm học tập
 Hướng dẫn AI
Hướng dẫn AI
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học