 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Sử dụng Llama 2 LLM mã nguồn mở để xây dựng chatbot tùy biến với Python không quá khó. Dưới đây là hướng dẫn chi tiết.

Llama 2 là mô hình ngôn ngữ lớn mã nguồn mở (LLM) do Meta phát triển. Mô hình mã nguồn mở này được đánh giá tốt hơn một số mô hình mã nguồn đóng như GPT-3.5 và PaLM 2. Nó bao gồm 3 kích thước mô hình văn bản tổng hợp được huấn luyện và tinh chỉnh trước, cụ thể là model tham số 7 tỷ, 13 tỷ và 70 tỷ.
Bạn sẽ khám phá khả năng đàm thoại của Llama 2 bằng cách xây dựng một chatbot bằng Streamlit và Llama 2.
Đặc điểm nổi bật của Llama 2
So với Llama 1, Llama 2 có những đặc điểm nổi bật sau:
- Kích thước mô hình lớn hơn: Mô hình lớn hơn, lên tới 70 tỷ tham số. Điều này cho phép nó tìm hiểu các mô hình phức tạp hơn giữa từ và câu.
- Cải thiện khả năng trò chuyện: Học tăng cường từ phản hồi của người dùng (RLHF) cải thiện khả năng ứng dụng đàm thoại. Điều này cho phép mô hình tạo nội dung giống như con người, ngay cả trong tương tác phức tạp.
- Suy luận nhanh hơn: Nó giới thiệu một phương thức mới, gọi là chú ý tới truy vấn theo nhóm để tăng tốc độ suy luận. Điều này cho bạn khả năng xây dựng nhiều ứng dụng hữu ích hơn, như chatbot và trợ lý ảo.
- Hiệu quả hơn: Nó dùng nhiều bộ nhớ và tài nguyên tính toán hơn phiên bản trước.
Giấy phép mã nguồn mở và phi thương mại: Nó là mã nguồn mở. Các nhà nghiên cứu và lập trình viên có thể sử dụng, chỉnh sửa thoải mái Llama 2.
Llama 2 vượt trội về mọi mặt so với bản cũ. Những đặc điểm này khiến nó trở thành một công cụ mạnh mẽ cho nhiều ứng dụng, như chatbot, trợ lý ảo và khả năng hiểu ngôn ngữ tự nhiên.
Thiết lập môi trường Streamlit cho phát triển chatbot
Để bắt đầu xây dựng ứng dụng, bạn phải thiết lập một môi trường phát triển để tách biệt dự án của bạn khỏi các dự án đang tồn tại trên máy.
Đầu tiên, bắt đầu bằng cách tạo một môi trường ảo bằng thư viện Pipenv như sau:
pipenv shellTiếp theo, cài đặt các thư viện cần thiết để xây dựng chatbot.
pipenv install streamlit replicateStreamlit: Nó là một framework app web mã nguồn mở, render nhanh chóng các ứng dụng khoa học dữ liệu và học máy.
Replicate: Nó là một nền tảng đám mây, cấp quyền truy cập tới các mô hình học máy mã nguồn mở lớn cho bạn triển khai dự án.
Tải token API Llama2 từ Replicate
Để lấy khóa token Replicate, đầu tiên, bạn phải đăng ký tài khoản trên Replicate bằng tài khoản GitHub.
Sau khi đã truy cập bảng điều khiển, điều hướng tới nút Explore và tìm chat Llama 2 để thấy model llama-2–70b-chat.
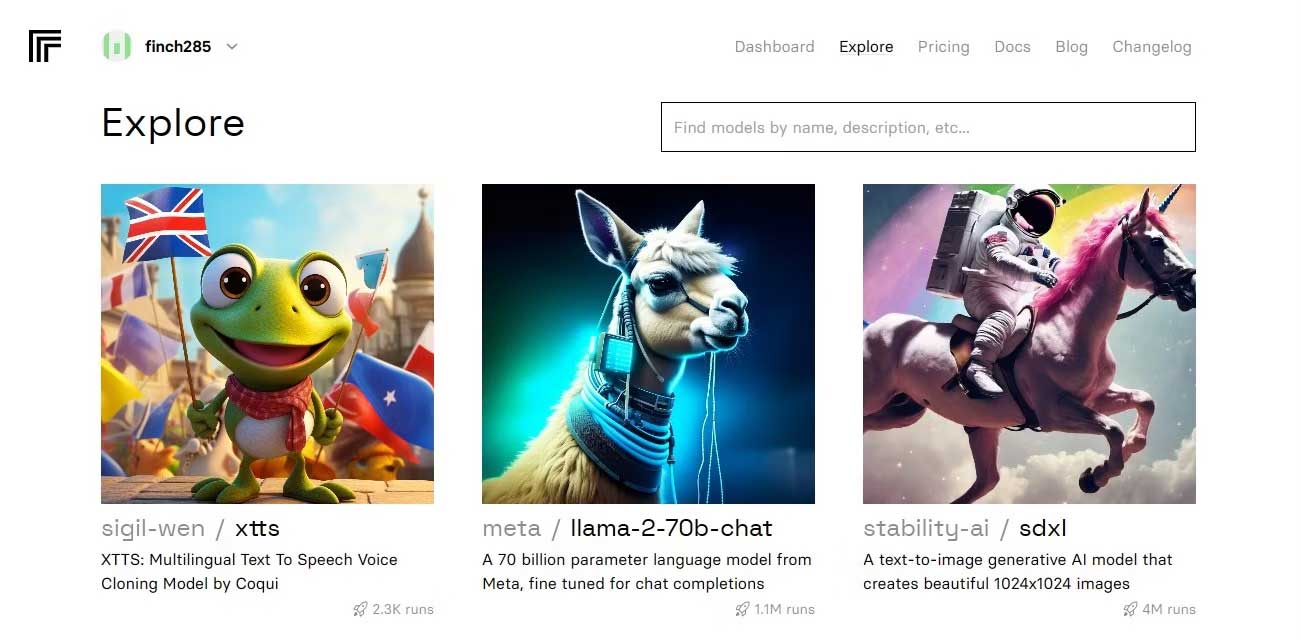
Click model llama-2–70b-chat để xem endpoint Llama 2 API. Click nút API trên thanh điều hướng của model llama-2–70b-chat. Ở bên phải của trang, click nút Python. Điều này sẽ cung cấp cho bạn quyền truy cập tới token API cho các ứng dụng Python.
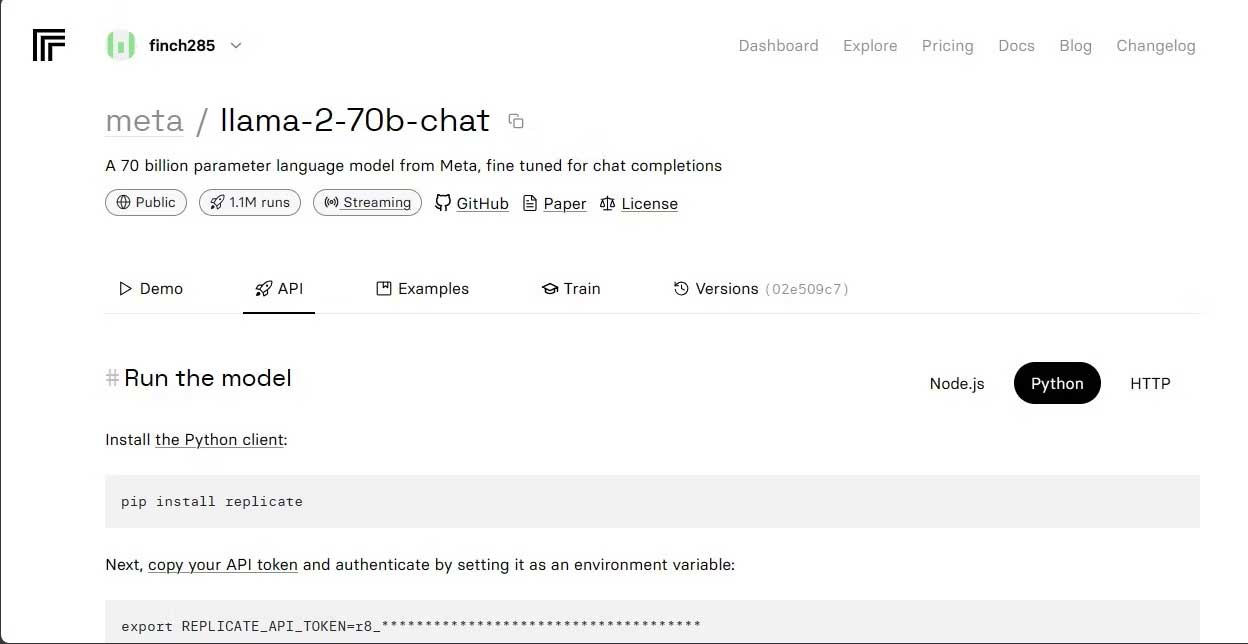
Sao chép REPLICATE_API_TOKEN và lưu trữ nó an toàn để sử dụng trong tương lai.
Xây dựng chatbot
Đầu tiên, tạo file Python tên llama_chatbot.py và tệp env (.env). Bạn sẽ viết code trong llama_chatbot.py và chứa khóa bí mật, token API trong file .env.
Trên file llama_chatbot.py, nhập thư viện như sau:
import streamlit as st
import os
import replicateTiếp theo, đặt biến toàn cục của model llama-2–70b-chat.
# Biến toàn cục
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default='')
# Xác định các endpoint model làm biến độc lập
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default='')
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default='')
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default='')Trên file .env, thêm token Replicate và các endpoint model ở định dạng sau:
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'Dán token Replicate và lưu file .env.
Thiết kế luồng hội thoại của chatbot
Tạo lời nhắc trước để khởi động model Llama 2 phụ thuộc vào nhiệm vụ bạn muốn thực hiện. Trong trường hợp này, ví dụ muốn model hoạt động như một trợ lý.
# Đặt Pre-propmt
PRE_PROMPT = "You are a helpful assistant. You do not respond as " \
"'User' or pretend to be 'User'." \
" You only respond once as Assistant."Thiết lập cấu hình trang cho chatbot như sau:
# Đặt cấu hình trang ban đầu
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)Viết một hàm khởi tạo và thiết lập biến trạng thái phiên.
# Hằng số
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
# Biến trạng thái phiên
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPT
def setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choose a LLaMA2 model:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)Hàm này đặt biến cơ bản như chat_dialogue, pre_prompt, llm, top_p, max_seq_len, và temperature trong trạng thái phiên. Nó cũng xử lý lựa chọn của model Llama 2 dựa trên lựa chọn của người dùng.
Viết một chức năng hiện nội dung sidebar của app Streamlit.
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperature:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sequence Length:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt before the chat starts. Edit here if desired:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPTHàm này hiện biến header và cài đặt của chatbot Llama 2 để điều chỉnh.
Viết hàm render lịch sử trò chuyện trong vùng nội dung chính của app Streamlit.
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])Hàm này lặp qua chat_dialogue đã lưu ở trạng thái phiên, hiện từng thông báo với vai trò tương ứng (người dùng hoặc trợ lý).
Xử lý đầu vào của người dùng bằng hàm bên dưới.
def handle_user_input():
user_input = st.chat_input(
"Type your question here to talk to LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)Hàm này hiện user với một trường đầu vào, nơi họ có thể nhập thông báo và câu hỏi. Thông báo được thêm vào chat_dialogue trong phiên trạng thái với vai trò user khi người dùng gửi thông báo.
Viết một hàm tạo phản hồi từ model Llama 2 và hiện chúng trong khu vực chat.
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})Hàm này tạo một chuỗi lịch sử trò chuyện, bao gồm cả thông báo người dùng và trợ lý trước khi gọi hàm debounce_replicate_run để lấy phản hồi của trợ lý. Nó liên tục chỉnh sửa phản hồi trong UI để cung cấp trải nghiệm tại thời gian thực.
Hàm chính này chịu trách nhiệm render toàn bộ app Streamlit.
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()Nó gọi tất cả các hàm được xác định trước để thiết lập trạng thái phiên, render sidebar, lịch sử chat, xử lý đầu vào người dùng và tạo phản hồi từ trợ lý ảo theo thứ tự logic.
Viết hàm gọi render_app và khởi động ứng dụng khi triển khai tập lệnh.
def main():
render_app()
if __name__ == "__main__":
main()Giờ ứng dụng đã sẵn sàng được triển khai.
Xử lý truy vấn API
Tạo file utils.py trong thư mục dự án và thêm hàm bên dưới:
import replicate
import time
# Initialize debounce variables
last_call_time = 0
debounce_interval = 2 # Set the debounce interval (in seconds)
def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)
current_time = time.time()
elapsed_time = current_time - last_call_time
if elapsed_time < debounce_interval:
print("Debouncing")
return "Hello! Your requests are too fast. Please wait a few" \
" seconds before sending another request."
last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return outputHàm này thực hiện một cơ chế gỡ lỗi để ngăn các truy vấn API thường xuyên và quá mức từ đầu vào của người dùng.
Tiếp theo, nhập hàm phản hồi gỡ lỗi vào file llama_chatbot.py như sau:
from utils import debounce_replicate_runGiờ chạy ứng dụng này:
streamlit run llama_chatbot.pyKết quả mong đợi:
Kết quả hiện một hội thoại giữa mẫu và một con người.
Ứng dụng thực tế của chatbot Streamlit và Llama 2
Một số ví dụ thực tế của ứng dụng Llama 2 bao gồm:
- Chatbot
- Trợ lý ảo
- Biên dịch ngôn ngữ
- Tóm tắt văn bản
- Nghiên cứu
Trên đây là cách xây dựng chatbot bằng Streamlit và Llama 2. Chúc các bạn thành công!







 Lập trình
Lập trình
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học