 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích
-
Công thức tính Diện tích hình vuông, tính Chu vi hình vuông
 Diện tích hình vuông bằng bình phương chiều dài cạnh hình vuông. Diện tích hình vuông là độ lớn của bề mặt hình, là phần mặt phẳng ta có thể nhìn thấy của hình vuông.
Diện tích hình vuông bằng bình phương chiều dài cạnh hình vuông. Diện tích hình vuông là độ lớn của bề mặt hình, là phần mặt phẳng ta có thể nhìn thấy của hình vuông. -
Công thức tính chiều cao hình thang: thường, vuông, cân
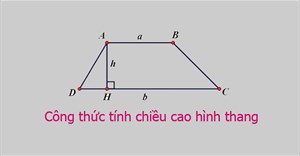 Chiều cao của hình thang là khoảng cách từ đỉnh vuông góc đến cạnh đáy lớn nhất. Với hình thang vuông thì chiều cao của hình thang chính là một cạnh bên của hình thang.
Chiều cao của hình thang là khoảng cách từ đỉnh vuông góc đến cạnh đáy lớn nhất. Với hình thang vuông thì chiều cao của hình thang chính là một cạnh bên của hình thang.


-
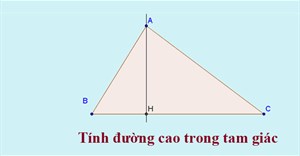
Công thức tính đường cao trong tam giác thường, cân, đều, vuông
 Đường cao trong tam giác là một đường thẳng có tính chất quan trọng và liên quan rất nhiều đến các bài toán hình học phẳng. Vậy đường cao là gì, cách tính đường cao trong tam giác như thế nào?
Đường cao trong tam giác là một đường thẳng có tính chất quan trọng và liên quan rất nhiều đến các bài toán hình học phẳng. Vậy đường cao là gì, cách tính đường cao trong tam giác như thế nào? -
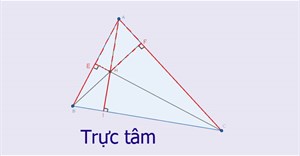
Trực tâm là gì? Xác định trực tâm trong tam giác
Trực tâm của tam giác là giao điểm của 3 đường cao, nghĩa là giao điểm của các đường thẳng từ mỗi đỉnh của tam giác đến cạnh đối diện của nó tạo thành một góc vuông. Tam giác có duy nhất một trực tâm. -
Số thập phân là gì? Các phép tính với số thập phân
Trong bài viết này, chúng ta cùng tìm hiểu số thập phân là số gì, cách đọc số thập phân, cách viết số thập phân và các phép cộng trừ nhân chia số thập phân như thế nào nhé.

-
Cách giải phương trình bậc 2
Phương trình bậc 2 là phương trình có dạng ax2+bx+c=0 (a≠0) (1). Giải phương trình bậc 2 là đi tìm các giá trị của x sao cho khi thay x vào phương trình (1) thì thỏa mãn ax2+bx+c=0. -
Căn bậc 2, cách tính căn bậc 2
Căn bậc 2 là một kiến thức quan trọng trong toán học. Mời các bạn theo dõi bài viết dưới đây để biết căn bậc 2 là gì, cách tính căn bậc 2 của một số như thế nào? -
Công thức tính vận tốc, quãng đường, thời gian chính xác
Vậy vận tốc là gì? Công thức tính vận tốc, cách tính quãng đường và thời gian chính xác là như nào? Bài viết dưới đây sẽ giúp bạn hiểu rõ hơn về đại lượng này, từ đó áp dụng trong công việc, cuộc sống nhé. -
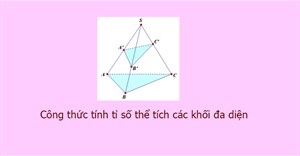
Công thức tính tỉ số thể tích các khối đa diện
Bài viết dưới đây sẽ giới thiệu với các bạn công thức tính nhanh tỉ số thể tích khối đa diện gồm công thức tính tỉ số thể tích khối chóp tam giác, công thức tính nhanh tỉ số thể tích khối chóp có đáy là hình bình hành, hai khối chóp chung chiều cao, hai khối đa diện đồng dạng tỉ số k, mời các bạn tham khảo. -
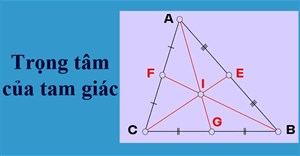
Trọng tâm là gì? Công thức tính trọng tâm của tam giác
Bài viết dưới đây, Quantrimang.com xin giới thiệu với các bạn các kiến thức liên quan tới trọng tâm tam giác, công thức tính trọng tâm tam giác, công thức tính tọa độ trọng tam giác, mời các bạn tham khảo.



-
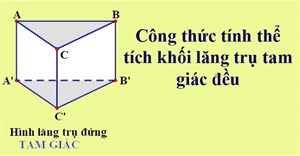
Công thức tính thể tích khối lăng trụ đứng, hình lăng trụ
Công thức tính thể tích hình lăng trụ đứng: Thể tích hình lăng trụ đứng bằng tích của diện tích đáy nhân với chiều cao. -
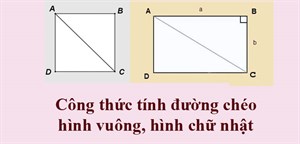
Công thức tính đường chéo hình vuông, đường chéo hình chữ nhật
Để tính đường chéo hình vuông, hình chữ nhật các bạn chỉ cần áp dụng định lý Pytago cho tam giác vuông. -
Công thức tính chu vi hình tam giác
Chu vi hình tam giác là kiến thức Toán học căn bản đã được đưa vào chương trình Toán học lớp 2. Chu vi hình tam giác được tính theo từng kiểu hình tam giác khác nhau. -
Công thức tính diện tích hình lập phương, thể tích khối lập phương
Nếu bạn đang thắc mắc các công thức về hình lập phương như diện tích, thể tích thì có thể tham khảo các công thức mà Quantrimang sẽ tổng hợp ở bài viết này. -
Số hữu tỉ là gì? Số vô tỉ là gì?
Số hữu tỉ, số vô tỉ là hai tập hợp số quan trọng được sử dụng nhiều trong toán học. Mời các bạn cùng tìm hiểu về định nghĩa, tính chất, các dạng toán của số hữu tỉ, số vô tỉ trong bài viết dưới đây.



-
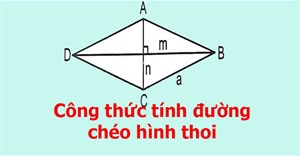
Công thức tính đường chéo hình thoi
Cách tính đường chéo hình thoi như thế nào? Mời các bạn tìm cách tính và và các ví dụ dưới đây để nắm được công thức tính đường chéo hình thoi nhé. -
Cách tính mét khối (m³) gỗ, nước, bê tông...
Cách tính mét khối (m3) sẽ giúp các bạn có thể tính toán và ước lượng được mét khối gỗ, đất, bê tông, sàn nhà, hình chữ nhật, hình trụ tròn, nước… từng hạng mục trong quá trình xây dựng và sản xuất. -
Các công thức đạo hàm và đạo hàm lượng giác đầy đủ nhất
Dưới đây là bảng công thức đạo hàm, đạo hàm lượng giác, các hàm lượng giác và công thức đạo hàm cao cấp đầy đủ nhất giúp các bạn dễ dàng ôn lại những kiến thức toán học về đạo hàm đã được học một cách nhanh nhất để giải bài tập nhanh hơn, hiệu quả hơn. -
Công thức tính thể tích khối trụ và ví dụ minh họa
Muốn tính thể tích của hình trụ, ta lấy chiều cao nhân với bình phương độ dài bán kính hình tròn mặt đáy hình trụ và số pi.



 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học