 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Vào đầu tháng 4 năm 2025, Meta đã ra mắt Llama 4, loạt mô hình AI mới nhất được thiết kế để đưa công ty lên một tầm cao mới. Mỗi mô hình Llama 4 mới đều có những cải tiến đáng kể so với các mô hình tiền nhiệm và đây là những tính năng mới nổi bật để thử.
3. Kiến trúc Mixture of Experts (MoE)
Một trong những tính năng nổi bật nhất của các mô hình Llama 4 là kiến trúc MoE mới, lần đầu tiên có trong loạt Llama, sử dụng một cách tiếp cận khác với những mô hình trước đó. Theo kiến trúc mới, chỉ một phần nhỏ các tham số của mô hình được kích hoạt cho mỗi token, không giống như trong các mô hình transformer dày đặc truyền thống như Llama 3 trở xuống, trong đó tất cả mọi tham số đều được kích hoạt cho từng tác vụ.
Ví dụ, Llama 4 Maverick chỉ sử dụng 17 tỷ tham số đang hoạt động trong số 400 tỷ, với 128 chuyên gia được định tuyến và một chuyên gia được chia sẻ. Llama 4 Scout, phiên bản nhỏ nhất trong series, có tổng cộng 109 tỷ tham số, chỉ kích hoạt 17 tỷ với 16 chuyên gia.
Phiên bản lớn nhất trong bộ ba, Llama 4 Behemoth, sử dụng 288 tỷ tham số đang hoạt động (với 16 chuyên gia) trong tổng số gần hai nghìn tỷ tham số. Nhờ kiến trúc mới này, chỉ có hai chuyên gia được giao cho mỗi nhiệm vụ.
Nhờ sự thay đổi về kiến trúc, các mô hình trong series Llama 4 có hiệu quả tính toán hơn trong quá trình đào tạo và suy luận. Chỉ kích hoạt một phần nhỏ các tham số cũng giúp giảm chi phí phục vụ và độ trễ. Nhờ kiến trúc MoE, Meta tuyên bố rằng Llama có thể chạy trên một GPU Nvidia H100 duy nhất, một kỳ tích ấn tượng khi xét đến số lượng tham số. Mặc dù không có số liệu cụ thể, nhưng người ta cho rằng mỗi truy vấn đến ChatGPT đều sử dụng nhiều GPU Nvidia, điều này tạo ra chi phí chung lớn hơn trong hầu hết mọi số liệu có thể đo lường được.
2. Khả năng xử lý đa phương thức gốc
Một bản cập nhật quan trọng khác cho các mô hình AI Llama 4 là khả năng xử lý đa phương thức gốc, nghĩa là bộ ba này có thể hiểu đồng thời văn bản và hình ảnh.
Điều này là nhờ sự kết hợp được thực hiện trong giai đoạn đào tạo ban đầu, trong đó các token văn bản và thị giác được tích hợp vào một kiến trúc thống nhất. Các mô hình được đào tạo bằng cách sử dụng một lượng lớn dữ liệu văn bản, hình ảnh và video không có nhãn.
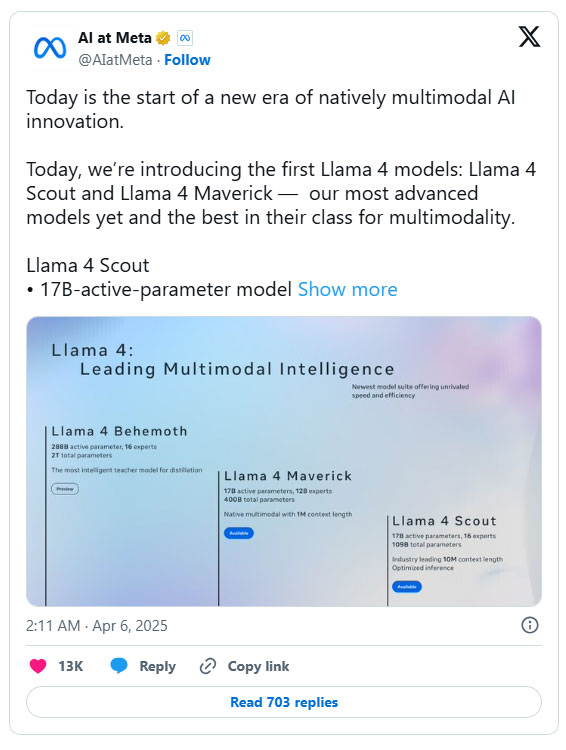
Không gì tuyệt vời hơn thế này. Nếu bạn còn nhớ, bản nâng cấp Llama 3.2 của Meta, được phát hành vào tháng 9 năm 2024, đã giới thiệu một số mô hình mới (tổng cộng là 10 mô hình), bao gồm 5 mô hình thị giác đa phương thức và 5 mô hình văn bản. Với thế hệ này, công ty không cần phải phát hành các mô hình văn bản và thị giác riêng biệt nhờ khả năng xử lý đa phương thức gốc.
Ngoài ra, Llama 4 sử dụng bộ mã hóa thị giác được cải tiến, cho phép các mô hình xử lý những tác vụ suy luận thị giác phức tạp và đầu vào nhiều hình ảnh, giúp chúng có khả năng xử lý các ứng dụng yêu cầu hiểu biết nâng cao về văn bản và hình ảnh. Xử lý đa phương thức cũng cho phép sử dụng các mô hình LLama 4 trên nhiều ứng dụng khác nhau.
1. Cửa sổ ngữ cảnh hàng đầu trong ngành
Các mô hình AI của Llama 4 tự hào có cửa sổ ngữ cảnh chưa từng có lên tới 10 triệu token. Mặc dù Llama 4 Behemoth vẫn đang trong quá trình đào tạo khi xuất bản, Llama 4 Scout đã thiết lập một chuẩn mực mới trong ngành với khả năng hỗ trợ lên tới 10 triệu token theo độ dài ngữ cảnh, cho phép bạn nhập văn bản dài hơn 5 triệu từ.
Độ dài ngữ cảnh mở rộng này là sự gia tăng đáng kể so với 8 nghìn token của Llama 3 khi lần đầu tiên ra mắt và thậm chí là sự mở rộng tiếp theo lên 128 nghìn sau khi nâng cấp Llama 3.2. Và không chỉ độ dài ngữ cảnh 10 triệu của Llama 4 Scout mới là điều thú vị; ngay cả Llama 4 Maverick, với độ dài ngữ cảnh một triệu, cũng là một kỳ tích ấn tượng.
Llama 3.2 hiện là một trong những chatbot AI tốt nhất cho các cuộc trò chuyện mở rộng. Tuy nhiên, cửa sổ ngữ cảnh mở rộng của Llama 4 đưa Llama lên vị trí dẫn đầu, vượt qua cửa sổ ngữ cảnh 2 triệu token hàng đầu trước đây của Gemini, Claude 3.7 Sonnet là 200K và GPT-4.5 là 128K.
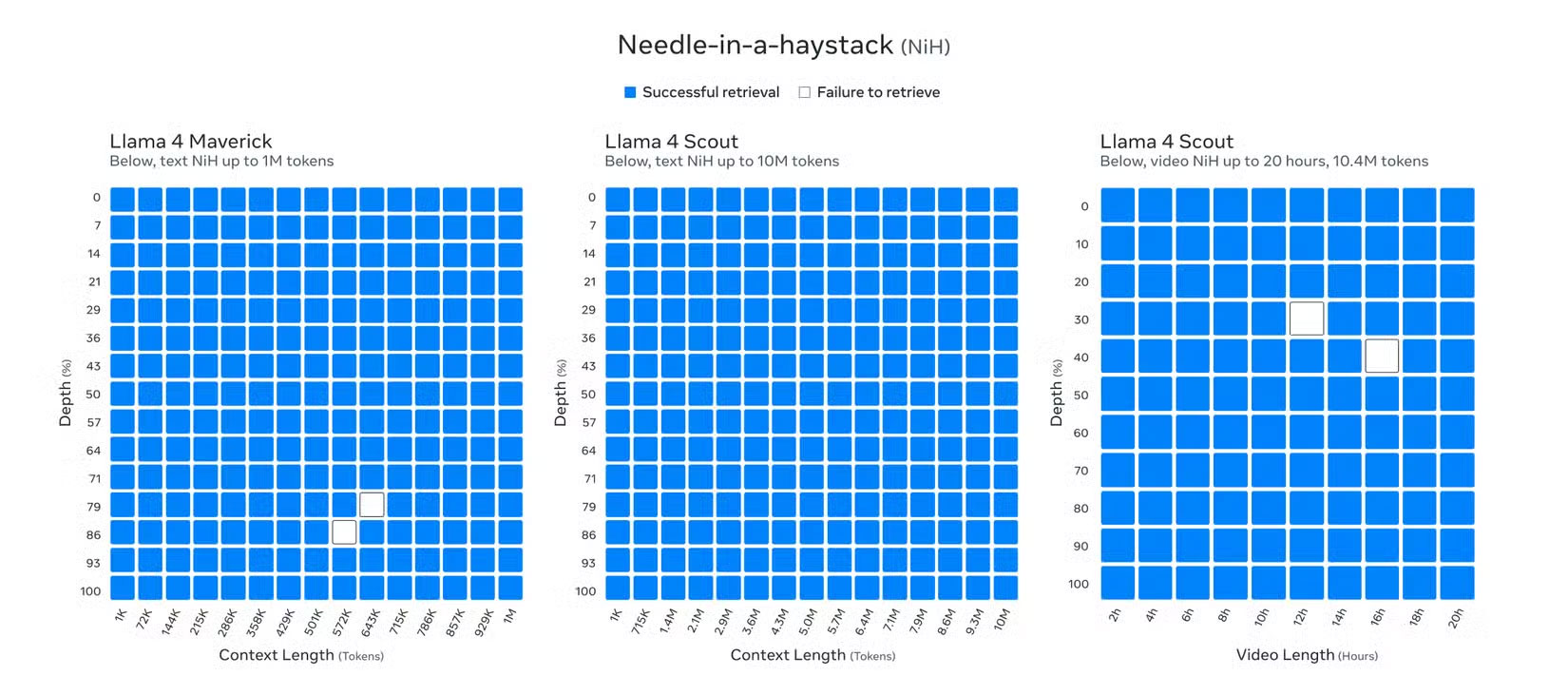
Với cửa sổ ngữ cảnh lớn, dòng Llama 4 có thể xử lý các tác vụ yêu cầu đầu vào với lượng thông tin khổng lồ. Cửa sổ lớn đó hữu ích trong những tác vụ như phân tích dài và nhiều tài liệu, phân tích chi tiết các cơ sở code lớn và lập luận trên những tập dữ liệu lớn.
Nó cũng cho phép Llama 4 thực hiện các cuộc trò chuyện mở rộng, không giống như những mô hình Llama trước đây và các mô hình từ những công ty AI khác. Nếu một trong những lý do khiến Gemini 2.5 Pro trở thành mô hình lý luận tốt nhất là cửa sổ ngữ cảnh lớn của nó, bạn có thể tưởng tượng được cửa sổ ngữ cảnh 5x hoặc 10x mạnh mẽ như thế nào.
Các mô hình Llama 3 series của Meta đã là một trong những LLM tốt nhất trên thị trường. Nhưng với việc phát hành loạt Llama 4, Meta đang tiến xa hơn một bước bằng cách không chỉ tập trung vào hiệu suất suy luận được cải thiện (nhờ cửa sổ ngữ cảnh hàng đầu trong ngành mới) mà còn đảm bảo các mô hình hiệu quả nhất có thể bằng cách sử dụng kiến trúc MoE mới trong cả quá trình đào tạo và suy luận.
Khả năng xử lý đa phương thức gốc, kiến trúc MoE hiệu quả và cửa sổ ngữ cảnh lớn của Llama 4 định vị nó như một mô hình AI có trọng lượng mở, hiệu suất cao, linh hoạt, có thể cạnh tranh hoặc vượt qua các mô hình hàng đầu về suy luận, mã hóa và nhiều tác vụ khác.






 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học