 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Aggregation Pipeline là cách được khuyến nghị để chạy các truy vấn phức tạp trong MongoDB. Nếu bạn đang sử dụng MapReduce của MongoDB, tốt nhất bạn nên chuyển sang Aggregation Pipeline để tính toán hiệu quả hơn.

Aggregation Pipeline trong MongoDB là gì?
Aggregation Pipeline là một quá trình đa giai đoạn chạy những truy vấn nâng cao trong MongoDB. Nó xử lý dữ liệu qua các giai đoạn khác nhau gọi là pipeline. Bạn có thể dùng kết quả được tạo từ một cấp độ làm mẫu hoạt động
Ví dụ: bạn có thể chuyển kết quả của thao tác đối sánh sang giai đoạn khác để sắp xếp theo thứ tự đó cho đến khi nhận được kết quả mong muốn.
Mỗi giai đoạn của một Aggregation Pipeline bao gồm một toán tử MongoDB và tạo một hoặc nhiều tài liệu được chuyển đổi. Tùy thuộc vào truy vấn của bạn, một cấp độ có thể xuất hiện nhiều lần trong quy trình. Ví dụ: bạn có thể cần sử dụng các giai đoạn toán tử $count hoặc $sort nhiều lần trong quy trình tổng hợp.

Các giai đoạn của Aggregation Pipeline
Aggregation Pipeline chuyển dữ liệu qua nhiều giai đoạn trong một truy vấn. Bạn có thể tìm thấy chi tiết về một số giai đoạn trọng tài liệu ở MongoDB.
Dưới đây là một số giai đoạn phổ biến nhất.
Giai đoạn $match
Giai đoạn này giúp bạn xác định các điều kiện lọc cụ thể trước khi bắt đầu các giai đoạn tổng hợp khác. Bạn có thể sử dụng nó để chọn dữ liệu phù hợp mà bạn muốn đưa vào quy trình tổng hợp.
Giai đoạn $group
Giai đoạn nhóm phân tách dữ liệu theo các nhóm khác nhau dựa trên tiêu chí cụ thể bằng cặp khóa-giá trị. Mỗi nhóm đại diện một khóa trong tài liệu đầu ra.
Ví dụ, xét dữ liệu mẫu sales sau:
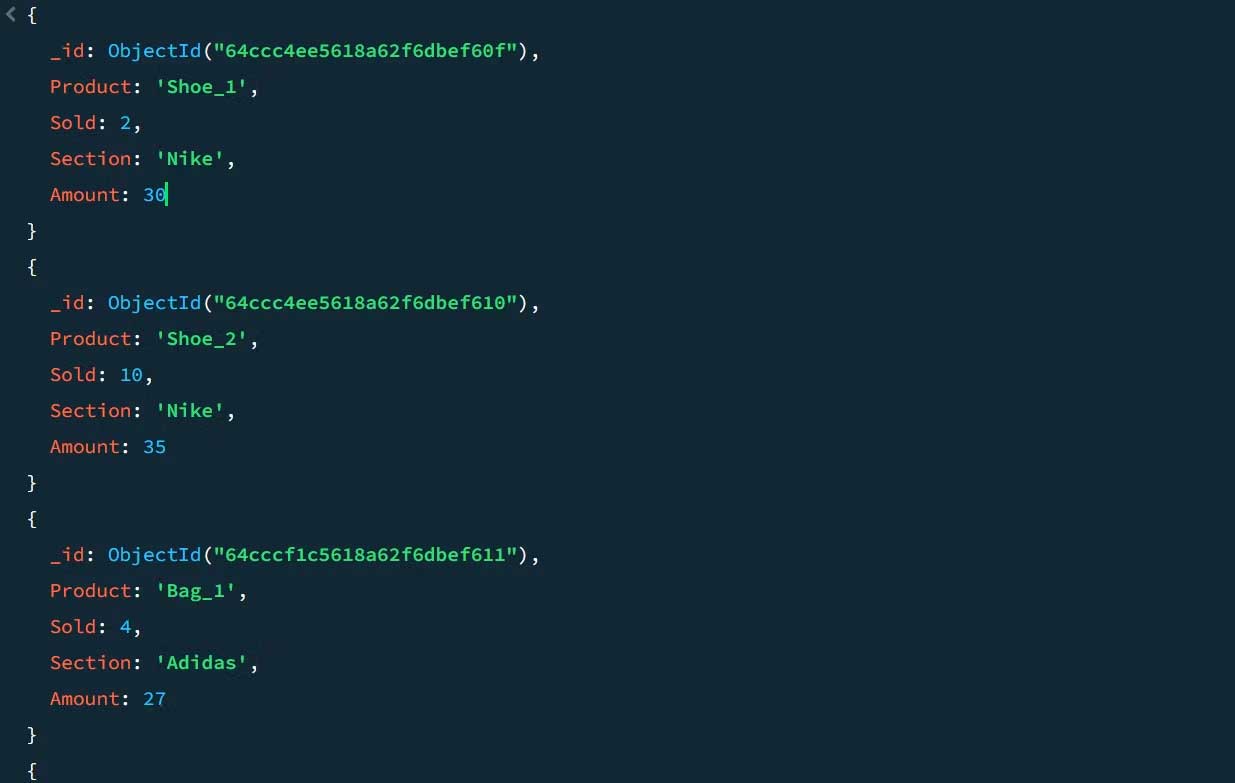
Dùng aggregation pipeline, bạn có thể tính toán tổng doanh số bán hàng và doanh số bán hàng cao nhất cho từng nhóm sản phẩm:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
Cặp _id: $Section nhóm tài liệu đầu ra dựa trên các phần. Bằng cách chỉ định các trường top_sale_count và top_sale, MongoDB tạo các khóa mới dựa trên hoạt động được xác định bởi trình tổng hợp; đây có thể là $sum, $min, $max hoặc $avg.
Giai đoạn $skip
Bạn có thể sử dụng giai đoạn $skip để bỏ qua một số lượng tài liệu được chỉ định trong đầu ra. Nó thường diễn ra sau giai đoạn nhóm. Ví dụ: nếu bạn mong đợi hai tài liệu đầu ra nhưng bỏ qua một tài liệu thì việc tổng hợp sẽ chỉ xuất ra tài liệu thứ hai.
Để thêm giai đoạn bỏ qua, chèn toán tử $skip vào aggregation pipeline:
...,
{
$skip: 1
},
Giai đoạn $sort
Giai đoạn phân loại cho phép bạn sắp xếp dữ liệu theo thứ tự giảm hoặc tăng dần. Ví dụ, phân loại dữ liệu ở ví dụ truy vấn trước theo thứ tự giảm dần để quyết định xem phần nào có doanh số cao nhất.
Thêm toán tử $sort vào truy vấn trước đó:
...,
{
$sort: {top_sales: -1}
},Giai đoạn $limit
Toán tử giới hạn giúp giảm số lượng tài liệu đầu ra mà bạn muốn Aggregation Pipeline hiển thị. Ví dụ, dùng toán tử $limit để lấy phần có doanh thu cao nhất đã trả về bởi giai đoạn trước đó:
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1}Kết quả chỉ trả về tài liệu đầu tiên, đây là phần có doanh số bán hàng cao nhất vì nó hiện ở phía trên cùng của kết quả được phân loại.
Giai đoạn $project
Giai đoạn $project cho phép bạn định hình tài liệu kết quả như ý muốn. Dùng toán tử $project, bạn có thể chỉ định trường bao gồm trong kết quả và tùy biến tên khóa của nó.
Ví dụ, một kết quả mẫu mà không có giai đoạn $project trông như sau:
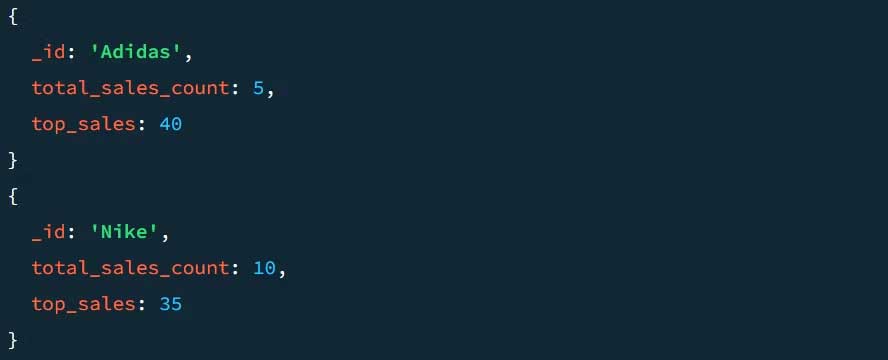
Hãy xem nó trông như thế nào khi kết hợp với giai đoạn $project. Để thêm $project vào pipeline:
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}Vì đã bỏ nhóm dữ liệu dựa trên các phần sản phẩm nên dữ liệu ở trên bao gồm từng phần sản phẩm trong tài liệu đầu ra. Nó cũng đảm bảo rằng số lượng bán hàng tổng hợp và tính năng bán hàng hàng đầu trong đầu ra là TotalSold và TopSale.
Kết quả cuối cùng gọn hơn nhiều so với phiên bản trước:

Cách tạo Aggregation Pipeline trong MongoDB
Mặc dù quy trình tổng hợp bao gồm một số thao tác nhưng các giai đoạn nổi bật trước đó sẽ cung cấp cho bạn ý tưởng về cách áp dụng chúng trong quy trình, bao gồm cả truy vấn cơ bản cho từng thao tác.
Dùng mẫu dữ liệu sales trước đó, hãy tổng hợp một số giai đoạn đã thảo luận ở trên để hiểu rõ hơn về Aggregation Pipeline trong MongoDB:
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
])Kết quả:

Trên đây là cách dùng Aggregation Pipeline trong MongoDB. Hi vọng bài viết hữu ích với các bạn.






 Lập trình
Lập trình
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học