 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Ngăn chặn overfitting và tăng cường độ chính xác của mô hình học máy bằng cách triển khai các phương pháp tăng cường dữ liệu của TensorFlow.
Tăng cường dữ liệu là quá trình áp dụng các phép biến đổi khác nhau cho dữ liệu đào tạo. Nó giúp tăng sự đa dạng của tệp dữ liệu và ngăn overfitting. Hành vi này chủ yếu xảy ra khi bạn có dữ liệu huấn luyện mô hình hạn chế.
Tại đây, bạn sẽ học cách dùng mô đun tăng cường dữ liệu của TensorFlow để đa dạng hóa dataset. Điều này ngăn chặn overfitting bằng cách tạo các điểm dữ liệu mới, hơi khác so với dữ liệu gốc.
Tệp dữ liệu mẫu trong ví dụ ở bài viết
Bạn sẽ dùng dataset mèo và chó từ Kaggle. Tệp dữ liệu này chứa khoảng 3.000 bức ảnh mèo và chó. Chúng được chia theo bộ huấn luyện, kiểm tra và xác thực.

Nhãn 1.0 đại diện cho con chó, còn nhãn 0.0 đại diện cho con mèo.
Cài đặt và nhập TensorFlow
Để làm theo hướng dẫn bên dưới, bạn nên có kiến thức cơ bản về Python và học máy.
Mở Google Colab. Thay đổi kiểu thời gian chạy sang GPU. Sau đó, chạy lệnh ma thuật sau trên ô code đầu tiên để cài TensorFlow vào môi trường của bạn.
!pip install tensorflowNhập TensorFlow và các mô đun, class liên quan.
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropouttensorflow.keras.preprocessing.image sẽ cho phép bạn chạy tăng cường dữ liệu trên dataset.
Tạo các phiên bản của class ImageDataGenerator
Tạo một phiên bản của class ImageDataGenerator cho dữ liệu đào tạo. Bạn sẽ dùng đối tượng này để xử lý trước dữ liệu. Nó sẽ tạo các lô dữ liệu ảnh tăng cường tại thời gian thực trong huấn luyện mô hình.
Trong nhiệm vụ phân loại hình ảnh là mèo hay chó, bạn có thể dùng các kỹ thuật tăng cường dữ liệu lật, chiều rộng & cao ngẫu nhiên, độ sáng ngẫu nhiên và thu phóng. Những kỹ thuật này sẽ tạo dữ liệu mới, chứa các biến thể của dữ liệu gốc, đại diện cho những tình huống ở thế giới thực.
# xác định trình tạo dữ liệu ảnh cho training
train_datagen = ImageDataGenerator(rescale=1./255,
horizontal_flip=True,
width_shift_range=0.2,
height_shift_range=0.2,
brightness_range=[0.2,1.0],
zoom_range=0.2)Tạo phiên bản khác của class ImageDataGenerator cho dữ liệu kiểm tra. Bạn sẽ cần tham số rescale. Nó sẽ bình thường hóa các giá trị pixel của các ảnh kiểm tra để khớp với định dạng đã dùng trong khi đào tạo.
# xác định trình tạo dữ liệu ảnh cho testing
test_datagen = ImageDataGenerator(rescale=1./255)Tạo phiên bản cuối cùng của class ImageDataGenerator cho dữ liệu xác thực. Thay đổi tỉ lệ dữ liệu xác thực giống như dữ liệu đã thử nghiệm.
# xác định trình tạo dữ liệu ảnh để xác thực
validation_datagen = ImageDataGenerator(rescale=1./255)Bạn không cần áp dụng các kỹ thuật tăng cường khác để kiểm tra và xác thực dữ liệu. Đó là do mô hình này dùng dữ liệu kiểm tra & xác thực chỉ cho mục đích đánh giá. Chúng sẽ thể hiện phân phối dữ liệu ban đầu.
Tải dữ liệu
Tạo đối tượng DirectoryIterator từ thư mục đào tạo. Nó sẽ tạo ra hàng loạt ảnh tăng cường. Sau đó, chỉ định thư mục lưu trữ dữ liệu đào tạo. Chỉnh lại kích thước ảnh sang cố định: 64x64 pixel. Chọn số ảnh mà từng nhóm sử dụng. Cuối cùng, chọn kiểu nhãn là binary.
# xác định thư mục training
train_data = train_datagen.flow_from_directory(directory=r'/content/drive/MyDrive/cats_and_dogs_filtered/train',
target_size=(64, 64),
batch_size=32,
class_mode='binary')Tạo đối tượng DirectoryIterator khác từ danh mục kiểm tra. Đặt các tham số thành những giá trị giống dữ liệu đào tạo.
# xác định thư mục testing
test_data = test_datagen.flow_from_directory(directory='/content/drive/MyDrive/cats_and_dogs_filtered/test',
target_size=(64, 64),
batch_size=32,
class_mode='binary')Tạo đối tượng DirectoryIterator cuối cùng từ thư mục xác thực. Các tham số còn lại giống với dữ liệu đào tạo và kiểm tra.
# xác định thư mục xác thực
validation_data = validation_datagen.flow_from_directory(directory='/content/drive/MyDrive/cats_and_dogs_filtered/validation',
target_size=(64, 64),
batch_size=32,
class_mode='binary')Các trình vòng lặp thư mục không làm tăng bộ dữ liệu xác thực và kiểm tra.
Xác định mô hình
Xác định kiến trúc của mạng thần kinh. Dùng Convolutional Neural Network (CNN) hay mạng tích chập. CNN được thiết kế để nhận diện các họa tiết, hoa văn và dặc điểm của ảnh.
model = Sequential()
# convolutional layer with 32 filters of size 3x3
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
# max pooling layer with pool size 2x2
model.add(MaxPooling2D(pool_size=(2, 2)))
# convolutional layer with 64 filters of size 3x3
model.add(Conv2D(64, (3, 3), activation='relu'))
# max pooling layer with pool size 2x2
model.add(MaxPooling2D(pool_size=(2, 2)))
# flatten the output from the convolutional and pooling layers
model.add(Flatten())
# fully connected layer with 128 units and ReLU activation
model.add(Dense(128, activation='relu'))
# randomly drop out 50% of the units to prevent overfitting
model.add(Dropout(0.5))
# output layer with sigmoid activation (binary classification)
model.add(Dense(1, activation='sigmoid'))Biên dịch mô hình bằng cách sử dụng hàm mất cross-entropy. Các vấn đề phân loại nhị phân thường sử dụng nó. Đối với tối ưu hóa, hãy sử dụng trình tối ưu hóa Adam. Nó là một thuật toán tối ưu hóa tốc độ học tập thích ứng. Cuối cùng, đánh giá mô hình về độ chính xác.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])In tổng quan kiến trúc của mô hình. Bạn có thể xem nó trên desktop.
model.summary()Kết quả:
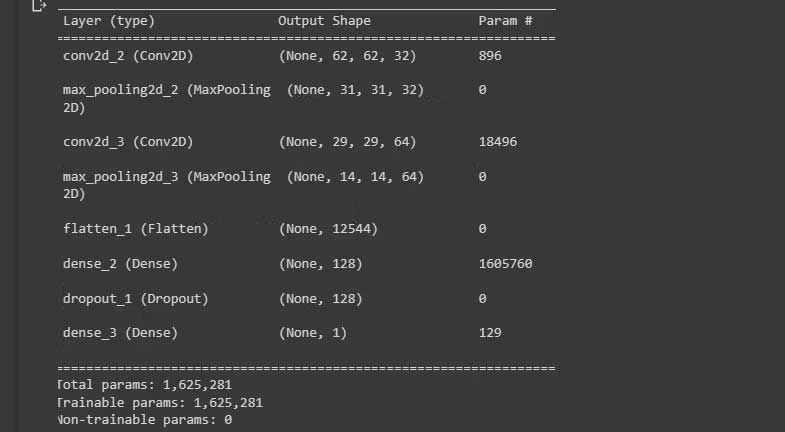
Huấn luyện mô hình
Đào tạo mô hình bằng phương thức fit(). Đặt số bước trên mỗi kỷ nguyên thành số lượng mẫu đào tạo, được chia cho batch_size. Ngoài ra, hãy đặt dữ liệu xác thực và số bước xác thực.
#Huấn luyện mô hình trên dữ liệu đào tạo
history = model.fit(train_data,
steps_per_epoch=train_data.n // train_data.batch_size,
epochs=50,
validation_data=validation_data,
validation_steps=validation_data.n // validation_data.batch_size)Class ImageDataGenerator áp dụng tăng cường dữ liệu cho dữ liệu đào tạo tại thời gian thực. Điều này khiến quá trình huấn luyện mô hình diễn ra chậm hơn.
Đánh giá mô hình
Đánh giá hiệu suất của mô hình trên dữ liệu kiểm tra bằng phương thức evaluate(). Ngoài ra, in tổn thất và độ chính xác của bài test vào console.
test_loss, test_acc = model.evaluate(test_data,
steps=test_data.n // test_data.batch_size)
print(f'Test loss: {test_loss}')
print(f'Test accuracy: {test_acc}')Kết quả:

Mô hình hoạt động khá tốt trên dữ liệu chưa từng thấy.
Khi bạn chạy code không triển khai các kỹ thuật tăng dữ liệu, độ chính xác đào tạo mô hình là 1. Điều đó có nghĩa là nó overfit. Nó cũng hoạt động kém trên dữ liệu chưa từng thấy trước đây. Điều này là do nó học các đặc thù của tập dữ liệu.
Khi nào tăng cường dữ liệu không hữu ích?
- Khi dataset đã đa dạng và phong phú.
- Khi dataset quá nhỏ.
- Khi kiểu tăng cường dữ liệu không còn phù hợp.






 Lập trình
Lập trình
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học