 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Meta đã công bố bộ mô hình Llama 4, bao gồm hai mô hình đã được phát hành – Llama 4 Scout và Llama 4 Maverick – và một mô hình thứ ba vẫn đang trong quá trình huấn luyện: Llama 4 Behemoth.
Các phiên bản Scout và Maverick hiện đã có sẵn, được phát hành công khai theo giấy phép mở trọng số thông thường của Meta – với một lưu ý đáng chú ý: Nếu dịch vụ của bạn vượt quá 700 triệu người dùng hoạt động hàng tháng, bạn cần phải xin giấy phép riêng từ Meta, và Meta có thể cấp hoặc không cấp giấy phép tùy theo quyết định của họ.
Llama Scout hỗ trợ cửa sổ ngữ cảnh 10 triệu token, lớn nhất trong số các mô hình được phát hành công khai. Llama Maverick là một mô hình đa năng và nhắm đến GPT-4o, Gemini 2.0 Flash và DeepSeek-V3. Llama Behemoth, vẫn đang trong quá trình huấn luyện, đóng vai trò là mô hình giảng dạy có dung lượng cao.
Llama 4 là gì?
Llama 4 là dòng mô hình ngôn ngữ quy mô lớn mới của Meta. Phiên bản này bao gồm hai mô hình đã có sẵn - Llama 4 Scout và Llama 4 Maverick - và một mô hình thứ ba, Llama 4 Behemoth, hiện vẫn đang trong quá trình huấn luyện.

Llama 4 giới thiệu những cải tiến đáng kể. Đặc biệt, nó tích hợp kiến trúc Mixture-of-Experts (MoE), nhằm mục đích cải thiện hiệu quả và hiệu suất bằng cách chỉ kích hoạt các thành phần cần thiết cho những nhiệm vụ cụ thể. Thiết kế này thể hiện sự chuyển dịch sang các mô hình AI có khả năng mở rộng và chuyên biệt hơn.
Hãy cùng tìm hiểu thêm chi tiết về từng mô hình.
Llama Scout
Llama 4 Scout là mô hình có trọng số nhẹ hơn trong bộ công cụ mới, nhưng có thể nói là thú vị nhất. Nó chạy trên một GPU H100 duy nhất và hỗ trợ cửa sổ ngữ cảnh 10 triệu token. Điều này làm cho Scout trở thành mô hình có trọng số mở cần nhiều ngữ cảnh nhất được phát hành cho đến nay và có khả năng hữu ích nhất cho các tác vụ như tóm tắt nhiều tài liệu, suy luận code dài và phân tích hoạt động.

Scout có 17 tỷ tham số hoạt động, được tổ chức thông qua 16 expert, với tổng số tham số là 109 tỷ. Nó được huấn luyện trước và sau với cửa sổ ngữ cảnh 256K, nhưng Meta cho biết nó có khả năng khái quát hóa tốt hơn nhiều so với con số đó (tuyên bố này vẫn cần được kiểm chứng). Trên thực tế, điều đó mở ra cánh cửa cho các quy trình làm việc liên quan đến toàn bộ cơ sở code, lịch sử phiên hoặc tài liệu pháp lý - tất cả đều được xử lý trong một lần truyền dữ liệu duy nhất.
Về kiến trúc, Scout được xây dựng bằng cách sử dụng framework MoE của Meta, trong đó chỉ một tập hợp con các tham số được kích hoạt trên mỗi token - trái ngược với các mô hình dày đặc như GPT-4o, nơi tất cả các tham số đều được kích hoạt. Điều đó có nghĩa là nó vừa tiết kiệm tài nguyên tính toán vừa có khả năng mở rộng cao.
Llama Maverick
Llama 4 Maverick là mô hình đa năng nhất trong dòng sản phẩm - một mô hình đa phương thức quy mô đầy đủ được xây dựng để hoạt động hiệu quả trên các lĩnh vực trò chuyện, suy luận, hiểu hình ảnh và code. Trong khi Scout đẩy giới hạn về độ dài ngữ cảnh, Maverick tập trung vào đầu ra cân bằng, chất lượng cao trên các tác vụ. Đây là câu trả lời của Meta cho GPT-40, DeepSeek-V3 và Gemini 2.0 Flash.

Maverick có cùng 17 tỷ tham số hoạt động như Scout, nhưng với cấu hình MoE lớn hơn: 128 expert và tổng số tham số là 400 tỷ. Giống như Scout, nó sử dụng kiến trúc MoE, chỉ kích hoạt một phần của mô hình trên mỗi token - giảm chi phí suy luận trong khi mở rộng dung lượng. Mô hình chạy trên một máy chủ H100 DGX duy nhất, nhưng cũng có thể được triển khai với suy luận phân tán cho các ứng dụng quy mô lớn hơn.
Llama Behemoth
Llama 4 Behemoth là mô hình mạnh mẽ và lớn nhất của Meta cho đến nay - nhưng nó vẫn chưa được phát hành. Vì vẫn đang trong quá trình huấn luyện, Behemoth không phải là mô hình suy luận theo cùng nghĩa với DeepSeek-R1 hoặc o3 của OpenAI, vốn được xây dựng và tối ưu hóa cho các nhiệm vụ chuỗi suy nghĩ nhiều bước.
Dựa trên những gì chúng ta biết cho đến nay, nó dường như cũng không được thiết kế như một sản phẩm để sử dụng trực tiếp. Thay vào đó, nó hoạt động như một mô hình giảng dạy, được sử dụng để chắt lọc và định hình cả Scout và Maverick. Sau khi được phát hành, nó có thể cho phép những người khác cũng chắt lọc các mô hình của riêng họ.

Behemoth có 288 tỷ tham số hoạt động, được tổ chức thông qua 16 expert, với tổng số tham số gần 2 nghìn tỷ. Meta đã xây dựng một cơ sở hạ tầng huấn luyện hoàn toàn mới để hỗ trợ Behemoth ở quy mô này. Hãng đã giới thiệu học tăng cường bất đồng bộ, lấy mẫu chương trình giảng dạy dựa trên độ khó của prompt và một hàm chắt lọc mới giúp cân bằng động các mục tiêu mềm và cứng.
Benchmark Llama 4
Meta đã công bố kết quả benchmark nội bộ cho từng mô hình Llama 4, so sánh chúng với cả các biến thể Llama trước đó và một số mô hình trọng số mở và mô hình tiên phong cạnh tranh.
Phần này sẽ hướng dẫn bạn qua những điểm nổi bật về benchmark của Scout, Maverick và Behemoth, sử dụng chính số liệu của Meta. Những điểm số này cung cấp cái nhìn đầu tiên hữu ích về hiệu suất của từng mô hình trên các nhiệm vụ khác nhau và vị trí của chúng trong bối cảnh hiện tại. Hãy bắt đầu với Scout.
Benchmark Llama Scout
Llama 4 Scout thể hiện tốt trên nhiều bài kiểm tra khả năng suy luận, lập trình và đa phương thức -đặc biệt khi xét đến số lượng tham số hoạt động ít hơn và chỉ sử dụng một GPU.
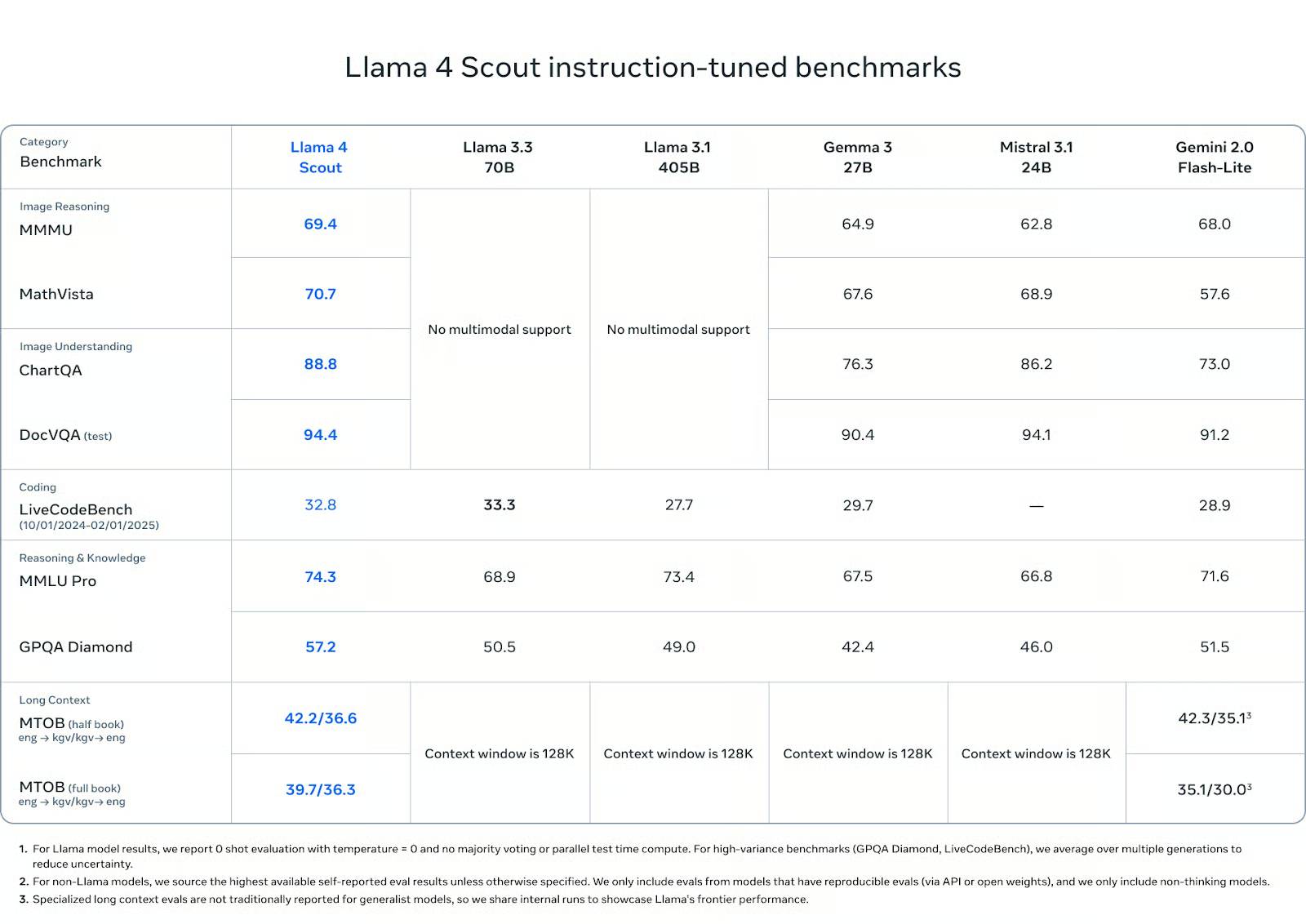
Về khả năng hiểu hình ảnh, Scout vượt trội hơn các đối thủ: đạt 88.8 điểm trên ChartQA và 94.4 điểm trên DocVQA (test), vượt qua Gemini 2.0 Flash-Lite (lần lượt là 73.0 và 91.2) và ngang bằng hoặc nhỉnh hơn một chút so với Mistral 3.1 và Gemma 3 27B.
Trong các bài kiểm tra khả năng suy luận hình ảnh như MMMU (69.4) và MathVista (70.7), nó cũng dẫn đầu nhóm các mô-đun có trọng số mở, vượt qua Gemma 3 (64.9, 67.6), Mistral 3.1 (62.8, 68.9) và Gemini Flash-Lite (68.0, 57.6).
Trong lập trình, Scout đạt 32.8 điểm trên LiveCodeBench, vượt trội hơn Gemini Flash-Lite (28.9) và Gemma 3 27B (29.7), mặc dù hơi thấp hơn Llama 3.3 với 33.3 điểm. Nó không phải là mô hình ưu tiên lập trình, nhưng khả năng của nó vẫn được đánh giá cao.
Về kiến thức và khả năng suy luận, Scout đạt 74.3 điểm trên MMLU Pro và 57.2 điểm trên GPQA Diamond, vượt trội hơn tất cả các mô hình trọng số mở khác trên cả hai bài kiểm tra. Các bài kiểm tra này ưu tiên khả năng suy luận đa bước dài, vì vậy hiệu suất mạnh mẽ của Scout ở đây rất đáng chú ý, đặc biệt là ở quy mô này.
Benchmark Llama Maverick
Maverick là mô hình toàn diện nhất trong dòng sản phẩm Llama 4 - và kết quả benchmark phản ánh điều đó. Mặc dù nó không nhắm đến độ dài ngữ cảnh cực đoan như Scout hay quy mô thô sơ như Behemoth, nhưng nó hoạt động nhất quán trên mọi hạng mục quan trọng: Suy luận đa phương thức, mã hóa, hiểu ngôn ngữ và khả năng ghi nhớ ngữ cảnh dài.
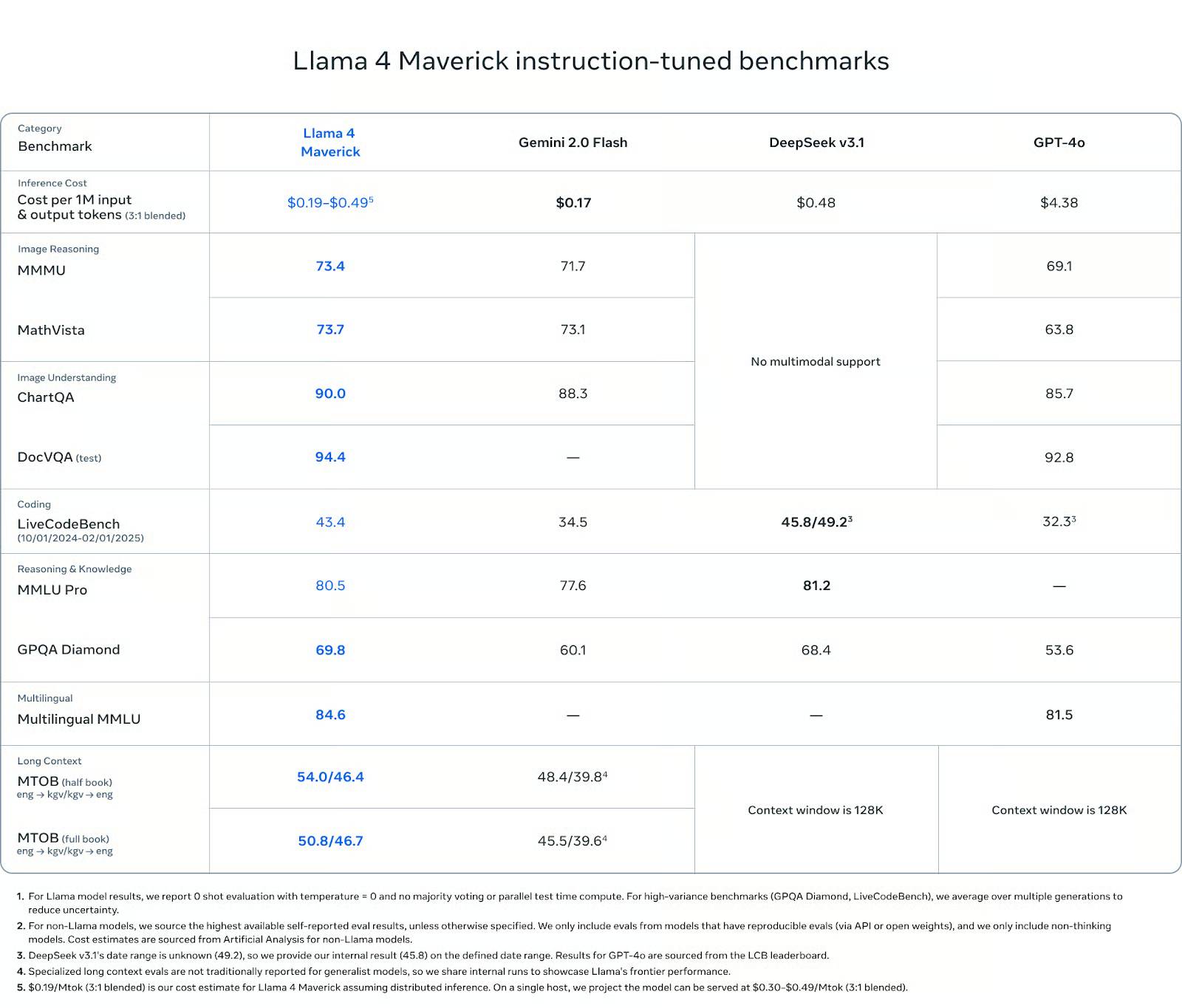
Trong suy luận hình ảnh, Maverick đạt 73,4 điểm trên MMMU và 73,7 điểm trên MathVista, vượt trội hơn Gemini 2.0 Flash (71,7 và 73,1) và GPT-4o (69,1 và 63,8). Trên ChartQA (hiểu hình ảnh), Maverick đạt 90.0 điểm, cao hơn một chút so với Gemini (88.3) và cao hơn hẳn GPT-4o (85.7). Trên DocVQA, Maverick đạt 94.4 điểm, ngang bằng với Scout và vượt trội hơn GPT-4o (92.8).
Về lập trình, Maverick đạt 43.4 điểm trên LiveCodeBench, cao hơn GPT-4o (32.3), Gemini Flash (34.5) và gần bằng DeepSeek v3.1 (45.8).
Về suy luận và kiến thức, Maverick đạt 80.5 điểm trên MMLU Pro và 69.8 điểm trên GPQA Diamond, một lần nữa vượt trội hơn Gemini Flash (77.6 và 60.1) và GPT-4o (không có kết quả MMLU Pro, 53.6 trên GPQA). DeepSeek v3.1 dẫn trước 0.7 điểm trên MMLU Pro.
Benchmark Llama Behemoth
Behemoth chưa được phát hành, nhưng các con số Benchmark của nó rất đáng chú ý.
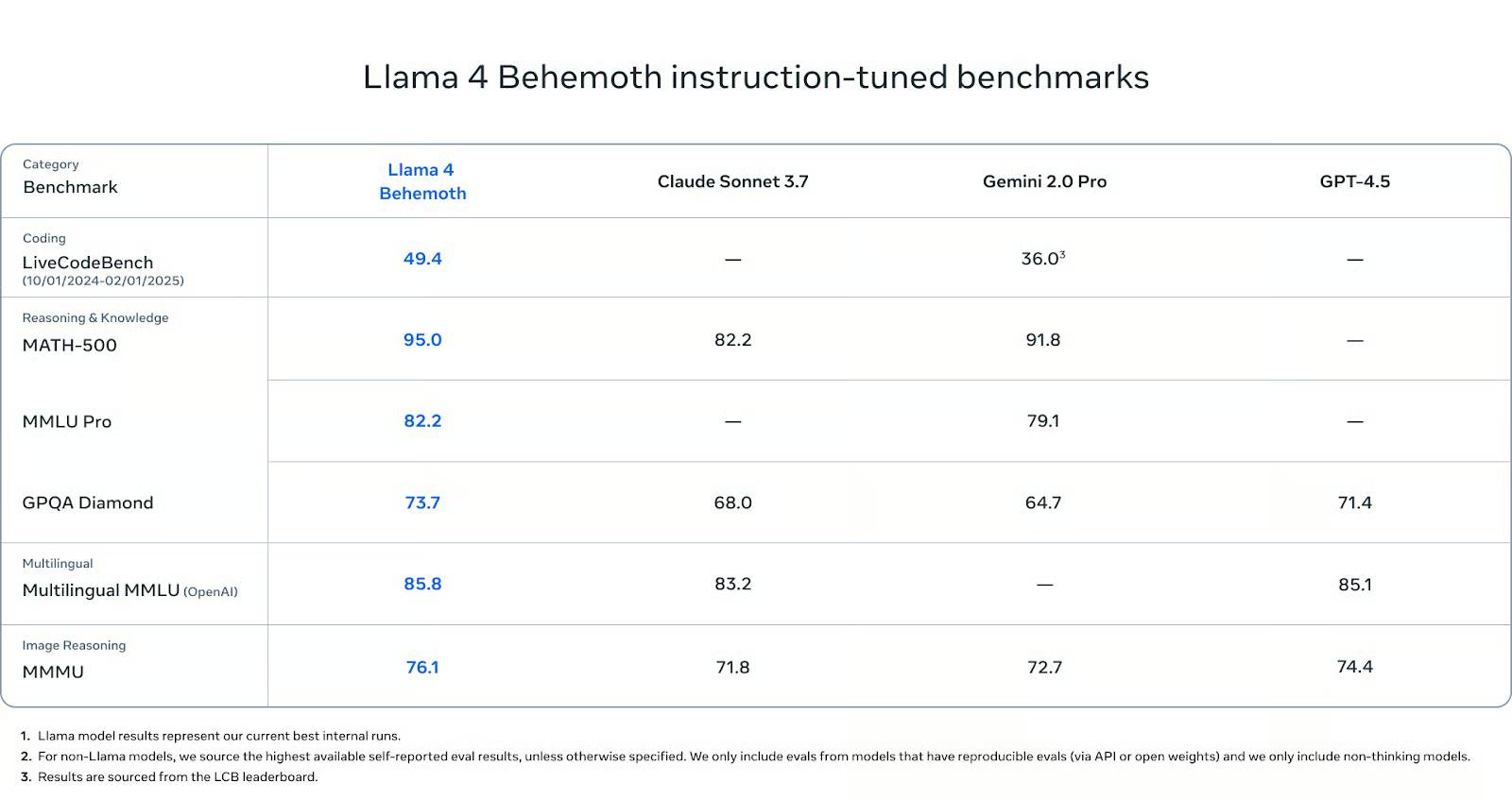
Trên các bài kiểm tra chuyên sâu về STEM, Behemoth thể hiện rất tốt. Nó đạt 95.0 điểm trên MATH-500 - cao hơn Gemini 2.0 Pro (91.8) và cao hơn đáng kể so với Claude Sonnet 3.7 (82.2). Trên MMLU Pro, Behemoth đạt 82.2 điểm, trong khi Gemini Pro đạt 79.1 điểm (Claude không có điểm số được báo cáo). Và trên GPQA Diamond, một bài kiểm tra khác đánh giá cao độ sâu và độ chính xác của thông tin thực tế, Behemoth đạt 73.7 điểm, vượt trội so với Claude (68.0), Gemini (64.7) và GPT-4.5 (71.4).
Về khả năng hiểu đa ngôn ngữ, Behemoth đạt 85.8 điểm trên Multilingual MMLU, nhỉnh hơn một chút so với Claude Sonnet (83.2) và GPT-4.5 (85.1). Những điểm số này rất quan trọng đối với các nhà phát triển toàn cầu làm việc ngoài tiếng Anh, và Behemoth hiện đang dẫn đầu hạng mục này.
Về khả năng suy luận hình ảnh, Behemoth đạt 76.1 điểm trên MMMU, vượt trội hơn Gemini (71.8), Claude (72.7) và GPT-4.5 (74.4). Mặc dù đây không phải là trọng tâm chính, nhưng nó vẫn thể hiện khả năng cạnh tranh với các mô hình đa phương thức hàng đầu.
Về khả năng tạo code, Behemoth đạt 49.4 điểm trên LiveCodeBench. Con số này cao hơn nhiều so với Gemini 2.0 Pro (36.0).
Cách truy cập Llama 4
Cả Llama 4 Scout và Llama 4 Maverick hiện đều có sẵn theo giấy phép mở của Meta. Bạn có thể tải xuống trực tiếp từ trang web chính thức của Llama hoặc thông qua Hugging Face.
Để truy cập các mô hình thông qua những dịch vụ của Meta, bạn có thể tương tác với Meta AI trên một số nền tảng: WhatsApp, Messenger, Instagram và Facebook. Hiện tại, việc truy cập yêu cầu đăng nhập bằng tài khoản Meta, và chưa có API endpoint độc lập nào cho Meta AI - ít nhất là cho đến hiện tại.
Nếu bạn dự định tích hợp các mô hình vào ứng dụng hoặc cơ sở hạ tầng của riêng mình, hãy lưu ý điều khoản cấp phép: Nếu sản phẩm hoặc dịch vụ của bạn có hơn 700 triệu người dùng hoạt động hàng tháng, bạn sẽ cần phải xin phép riêng từ Meta. Ngoài ra, các mô hình có thể được sử dụng cho nghiên cứu, thử nghiệm và hầu hết các trường hợp sử dụng thương mại.




 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học