 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Bạn có bao giờ thắc mắc xe tự lái, chatbot và đề xuất tự động của Netflix hoạt động như thế nào chưa? Những tiến bộ công nghệ tiện ích ấy là sản phẩm của machine learning.
Machine learning là một loại trí tuệ nhân tạo với khả năng đào tạo máy tính để nghiên cứu các hành vi người dùng và sử dụng thuật toán để đưa ra quyết định thông minh mà không cần can thiệp của con người. Các thuật toán học độc lập với dữ liệu đầu vào và dự đoán đầu ra logic dựa trên tính năng độc của tập dữ liệu huấn luyện.
Dưới đây là một số thuật toán machine learning tốt nhất giúp tạo và huấn luyện các hệ thống máy tính thông minh.
Tầm quan trọng của thuật toán trong machine learning
Thuật toán machine learning là một tập hợp các hướng dẫn được sử dụng để giúp máy tính bắt chước hành vi của con người. Các thuật toán như vậy có thể thực hiện các tác vụ phức tạp mà không cần hoặc cần rất ít sự trợ giúp của con người.
Thay vì viết code cho mọi tác vụ, thuật toán sẽ xây dựng logic từ dữ liệu bạn đưa vào mô hình. Với một tập dữ liệu đủ lớn, nó sẽ xác định được một mẫu, cho phép nó đưa ra các quyết định hợp lý và dự đoán đầu ra có giá trị.
Các hệ thống hiện đại sử dụng một số thuật toán máy học, mỗi thuật toán có lợi ích hiệu suất riêng. Các thuật toán cũng khác nhau về độ chính xác, dữ liệu đầu vào và trường hợp sử dụng. Như vậy, bước quan trọng nhất để xây dựng một mô hình machine learning thành công đó là chọn đúng thuật toán cần dùng.
1. Hồi quy logistic
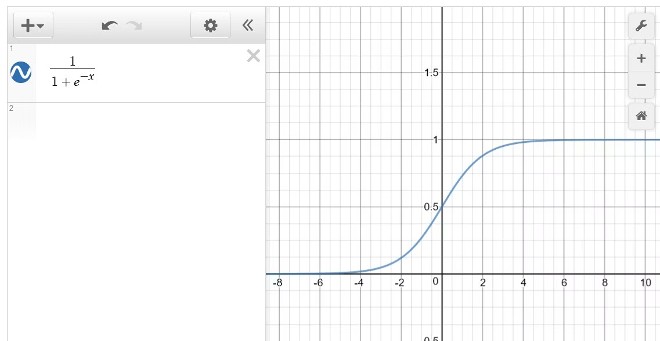
Thuật toán hồi quy logistic, hay còn được gọi là hồi quy logistic nhị thức, có thể tìm xác suất thành công hay thất bại của một sự kiện. Nói chung, nó là phương thức nên chọn khi biến phụ thuộc là nhị phân. Hơn nữa, kết quả thường được xử lý đơn giản là đúng/sai hoặc có/không.
Để sử dụng mô hình thống kê này, bạn phải nghiên cứu và phân loại các tập dữ liệu đã được dán nhãn thành các danh mục riêng biệt. Một tính năng ấn tượng khác đó là bạn có thể mở rộng hồi quy logistic cho nhiều lớp và đưa ra cái nhìn thực tế về các dự đoán của lớp dựa trên xác suất.
Với nhiệm vụ như phân loại các bản ghi chưa biết và các tập dữ liệu đơn giản, hồi quy logistic hoạt động rất nhanh và chính xác. Nó cũng đặt biệt xuất sắc trong việc giải thích các hệ số mô hình. Ngoài ra, hồi quy logistic còn hoạt động tốt trong các tình huống mà tập dữ liệu có thể phân tách tuyến tính.
Với thuật toán này, bạn có thể dễ dàng cập nhật các mô hình để phản ánh dữ liệu mới và sử dụng suy luận để xác định mối quan hệ giữa các tính năng. Nó cũng ít bị trang bị quá mức, có kỹ thuật chính quy hóa trong trường hợp có một và nhiều yêu cầu ít sức mạnh tính toán.
Một hạn chế lớn của hồi quy logistic là nó giả định mối quan hệ tuyến tính giữa các biến phụ thuộc và biến độc lập. Điều này khiến nó không phù hợp với các bài toán phi tuyến tính vì nó chỉ dự đoán các hàm rời rạc sử dụng bề mặt quyết định tuyến tính. Do đó, với các tác vụ phức tạp hơn bạn sẽ phải cần tới các thuật toán mạnh hơn.
2. Cây quyết định
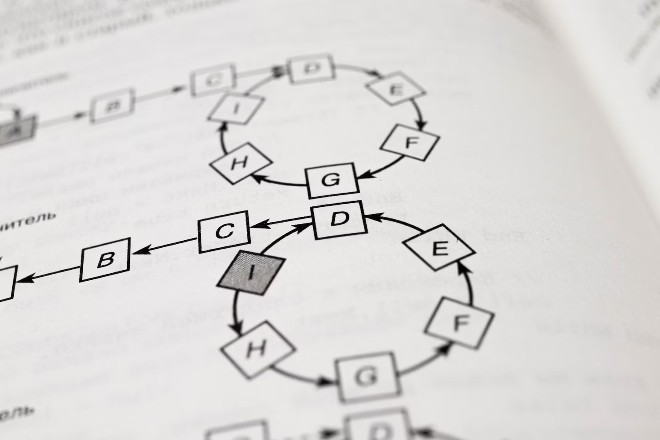
Tên của thuật toán này bắt nguồn từ cách tiếp cận theo cấu trúc cây của nó. Bạn có thể sử dụng framework Cây quyết định cho các vấn đề phân loại và hồi quy. Tuy nhiên, nó có nhiều chức năng hơn khi giải các bài toán phân loại.
Giống như một cái cây, nó bắt đầu với nút gốc đại diện cho tập dữ liệu. Các nhánh đại diện cho các quy tắc hướng dẫn quá trình học. Các nhánh này, được gọi là các nút quyết định, là các câu hỏi có hoặc không để dẫn tới các nhánh khác hoặc kết thúc tại các nút lá.
Mỗi nút lá đại diện cho kết quả có thể xảy ra từ việc xây dựng các quyết định. Nút lá và nút quyết định là hai thực thể chính liên quan đến việc dự đoán kết quả từ thông tin được cung cấp. Do đó, đầu ra hoặc quyết định cuối cùng dựa trên các tính năng của tập dữ liệu.
Cây quyết định là thuật toán machine learning có giám sát. Loại thuật toán này yêu cầu người dùng giải thích đầu vào là gì. Họ cũng cần mô tả về đầu ra dự kiến từ dữ liệu huấn luyện.
Nói một cách đơn giản, thuật toán này là một biểu diễn đồ họa của các tùy chọn khác nhau được hướng dẫn bởi các điều kiện đặt trước nhằm tìm ra tất cả các giải pháp khả thi cho một vấn đề. Như vậy, các câu hỏi được đặt ra là một quá trình xây dựng để đi đến một giải pháp. Cây quyết định bắt chước quá trình suy nghĩ của con người để đưa ra phán quyết logic bằng cách sử dụng các quy tắc đơn giản.
Nhược điểm chính của thuật toán này là nó dễ bị mất ổn định; chỉ một thay đổi nhỏ trong dữ liệu có thể gây ra sự gián đoạn lớn trong cấu trúc. Do vậy, bạn nên khám phá nhiều cách khác nhau để có được các tập dữ liệu nhất quán cho dự án của mình.
3. Thuật toán K-NN
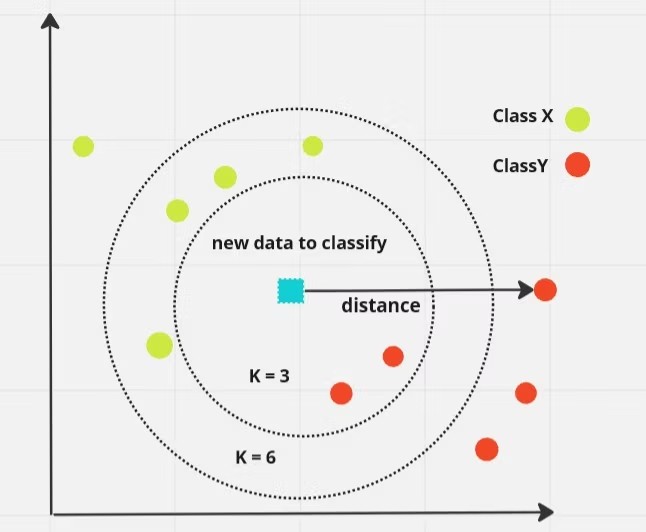
K-NN đã được chứng minh là một thuật toán đa diện hữu ích cho việc giải quyết nhiều vấn đề trong thế giới thực. Mặc dù là một trong những thuật toán machine learning đơn giản nhất nhưng K-NN lại có thể ứng dụng hữu ích trong nhiều ngành, từ bảo mật đến tài chính và kinh tế.
Đúng như tên gọi của mình, K-Nearest Neighbor (viết tắt là K-NN) hoạt động như một bộ phân loại giả định sự giống nhau giữa dữ liệu lân cận mới và hiện có. Sau đó, nó đặt trường hợp mới vào danh mục giống hoặc tương tự như dữ liệu có sẵn gần nhất.
Điều quan trọng cần lưu ý là K-NN là một thuật toán phi tham số; nó không đưa ra các giả định về dữ liệu cơ bản. K-NN còn được gọi là thuật toán lười học do nó không học ngay lập tức từ dữ liệu huấn luyện. Thay vào đó, nó lưu trữ các tập dữ liệu hiện tại và đợi cho tới khi nhận được dữ liệu mới. Tiếp theo, nó thực hiện phân loại dựa trên sự gần gũi và tương đồng.
K-NN rất thiết thực và mọi người sử dụng nó trong nhiều lĩnh vực khác nhau. Trong lĩnh vực chăm sóc sức khỏe, thuật toán này có thể dự đoán các rủi ro sức khỏe có thể xảy ra dựa trên các biểu hiện gen có khả năng nhất của một cá nhân. Trong lĩnh vực tài chính, các chuyên gia sử dụng K-NN để dự báo thị trường chứng khoán và thậm chí cả tỷ giá hối đoái.
Nhược điểm chính của việc sử dụng thuật toán này là nó tốn nhiều bộ nhớ hơn các thuật toán machine learning khác. Nó cũng gặp khó khăn trong việc xử lý dữ liệu đầu vào phức tạp, nhiều chiều.
Tuy nhiên, K-NN vẫn là một lựa chọn tốt vì nó thích ứng dễ dàng, xác định mẫu đơn giản và cho phép bạn sửa đổi dữ liệu runtime mà không ảnh hưởng tới độ chính xác của dự đoán.
4. K-Means

K-Means là một thuật toán học không giám sát giúp nhóm các bộ dữ liệu không được gắn nhãn thành các cụm (cluster) duy nhất. Nó nhận dữ liệu đầu vào, giảm thiểu khoảng cách giữa các điểm dữ liệu và tổng hợp dữ liệu dựa trên những điểm chung.
Rõ ràng hơn thì một cluster là một tập hợp các điểm dữ liệu được nhóm vào với nhau do những điểm tương đồng nhất định. Yếu tố "K" cho hệ thống biết cần bao nhiêu cluster.
Một minh họa thực tế về cách thức hoạt động của thuật toán này liên quan tới việc phân tích một nhóm cầu thủ bóng đá được đánh số. Bạn có thể sử dụng thuật toán này để tạo và chia các cầu thủ thành hai nhóm: cầu thủ chuyên nghiệp và cầu thủ nghiệp dư.
Thuật toán K-Means có một số ứng dụng trong thực tế. Bạn có thể sử dụng nó để phân loại điểm của học sinh, thực hiện chẩn đoán y tế và hiển thị kết quả của công cụ tìm kiếm. Tóm lại, nó vượt trội trong việc phân tích số lượng lớn dữ liệu và chia chúng thành các cluster logic.
Vấn đề lớn nhất của thuật toán này đó là kết quả thường không nhất quán. Nó phụ thuộc vào thứ tự, do đó, bất kỳ thay đổi nào mới thứ tự của tập dữ liệu hiện có đều có thể ảnh hưởng đến kết quả của nó. Hơn nữa, nó thiếu hiệu ứng thống nhất và chỉ có thể xử lý dữ liệu số.
Bất chấp những hạn chế này, K-Means là một trong những thuật toán machine learning hoạt động tốt nhất. Nó hoàn hảo cho việc phân đoạn các bộ dữ liệu và được tin cậy vì khả năng thích ứng của nó.
Chọn thuật toán tốt nhất cho bạn
Là một người mới bắt đầu, có thể bạn sẽ cần hỗ trợ trong việc chọn lựa thuật toán nào tốt nhất. Đây là một điều khó khăn khi mà hiện có rất nhiều lựa chọn tuyệt vời. Tuy nhiên, đầu tiên, bạn nên lựa chọn dựa trên một thứ khác thay vì những tính năng nổi bật của thuật toán.
Bạn nên xem xét quy mô của thuật toán, bản chất của dữ liệu, mức độ khẩn cấp của nhiệm vụ và các yêu cầu về hiệu suất. Những yếu tố này, cùng với các yếu tố khác, sẽ giúp bạn xác định được thuật toán hoàn hảo cho dự án của mình.









 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học