 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Chỉ khoảng một năm trước, các mô hình AI Omni vẫn còn là một lời hứa nhiều hơn là một công nghệ thực sự sẵn sàng để các nhà phát triển sử dụng. Phần lớn hệ thống AI đa phương thức (multimodal AI) khi đó vẫn phải kết hợp nhiều mô hình riêng biệt: một mô hình xử lý văn bản, một mô hình xử lý hình ảnh, một mô hình nhận diện giọng nói và đôi khi còn thêm một mô hình khác dành riêng cho video. Ý tưởng về một AI duy nhất có thể hiểu đồng thời nhiều loại dữ liệu đầu vào và phản hồi bằng nhiều định dạng khác nhau vẫn còn khá xa vời.
Điều đó đang dần thay đổi.
Ngày nay, nhiều mô hình AI Omni và AI đa phương thức mã nguồn mở đã có thể xử lý văn bản, hình ảnh, âm thanh và video theo một cách thống nhất hơn rất nhiều. Một số mô hình có khả năng phân tích hình ảnh, tài liệu, phiên âm và suy luận từ âm thanh, hiểu nội dung video rồi trả lời bằng văn bản. Những mô hình tiên tiến hơn còn có thể tạo giọng nói, sinh ảnh hoặc hỗ trợ tương tác đa phương thức theo thời gian thực.
Trong bài viết này, chúng ta sẽ cùng điểm qua 5 mô hình AI Omni mã nguồn mở đang dẫn đầu xu hướng này. Cần lưu ý rằng không phải mô hình nào cũng là AI "any-to-any" thực sự. Một số chỉ hỗ trợ nhiều loại dữ liệu đầu vào nhưng vẫn chỉ trả lời bằng văn bản, trong khi các mô hình khác còn có thể tạo giọng nói, sinh hình ảnh hoặc tương tác âm thanh - hình ảnh theo thời gian thực. Hiểu rõ điểm mạnh của từng mô hình sẽ giúp bạn lựa chọn công cụ phù hợp với nhu cầu sử dụng.
NVIDIA Nemotron 3 Nano Omni 30B A3B Reasoning
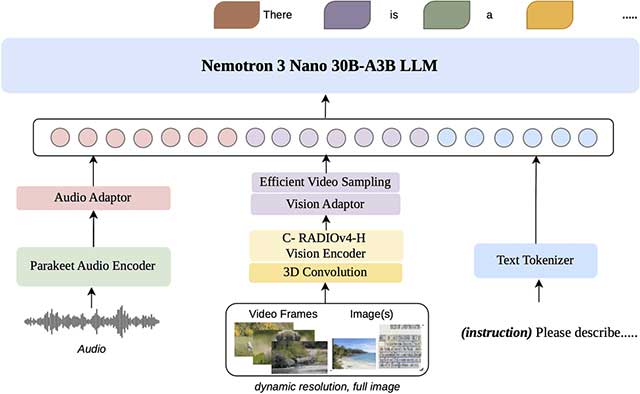
NVIDIA Nemotron 3 Nano Omni 30B A3B Reasoning là mô hình AI Omni mạnh mẽ được phát triển hướng đến các ứng dụng doanh nghiệp. Mô hình có thể xử lý đồng thời video, âm thanh, hình ảnh và văn bản trước khi đưa ra phản hồi bằng văn bản.
Nhờ đó, Nemotron phù hợp với nhiều tác vụ như phân tích video, nhận diện và phân tích giọng nói, xử lý tài liệu, đọc biểu đồ, nhận dạng ký tự quang học (OCR), chuyển giọng nói thành văn bản, hiểu giao diện người dùng (GUI) và trả lời các câu hỏi đa phương thức.
Mô hình được xây dựng trên kiến trúc lai Mamba2-Transformer kết hợp Mixture-of-Experts với tổng cộng khoảng 31 tỷ tham số, trong đó chỉ khoảng 3 tỷ tham số được kích hoạt cho mỗi token. Thiết kế này giúp cân bằng giữa khả năng suy luận mạnh và tốc độ xử lý.
Nemotron còn hỗ trợ cửa sổ ngữ cảnh lên tới 256.000 token, đủ để phân tích các tài liệu dài, biên bản cuộc họp, video đào tạo hay những kho dữ liệu lớn trong doanh nghiệp.
Điểm nổi bật của Nemotron không nằm ở những màn trình diễn AI đa phương thức, mà ở khả năng giải quyết các quy trình làm việc thực tế như chăm sóc khách hàng, phân tích truyền thông, rà soát tài liệu, trợ lý AI, trình duyệt thông minh, tác nhân email hay tự động hóa thao tác trên giao diện người dùng.
Phù hợp nhất với: phân tích video và giọng nói, OCR, xử lý tài liệu, đọc biểu đồ, hiểu giao diện GUI, nhận diện giọng nói (ASR) và hệ thống hỏi đáp đa phương thức trong doanh nghiệp.
Google Gemma 4 12B IT
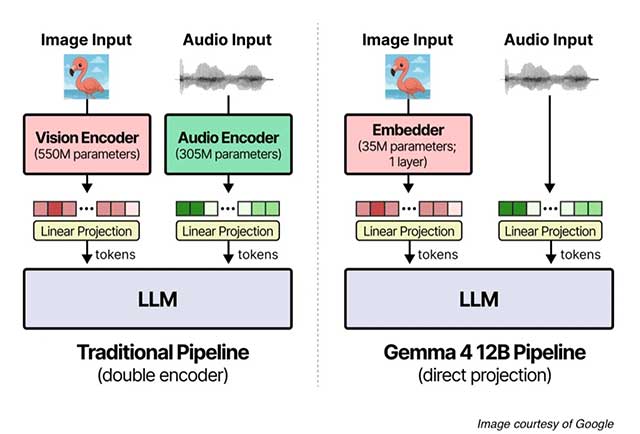
Google Gemma 4 12B IT là thành viên của dòng mô hình Gemma mã nguồn mở do Google DeepMind phát triển. Đây là mô hình AI đa phương thức nhỏ gọn nhưng hiệu quả, hướng đến các ứng dụng AI chạy cục bộ hoặc tự triển khai (self-hosted).
Gemma 4 có thể tiếp nhận văn bản, hình ảnh, âm thanh và video, sau đó tạo phản hồi bằng văn bản. Mô hình phù hợp với nhiều tác vụ như trả lời câu hỏi dựa trên hình ảnh, hiểu tài liệu PDF, OCR, phân tích biểu đồ, phiên âm âm thanh, dịch giọng nói, lập trình, suy luận và xây dựng trợ lý AI đa phương thức.
Điểm đáng chú ý nhất của phiên bản 12B là kiến trúc đa phương thức không sử dụng encoder riêng. Thay vì phải có các bộ mã hóa hình ảnh hoặc âm thanh độc lập, Gemma chuyển trực tiếp dữ liệu hình ảnh và sóng âm vào không gian biểu diễn của mô hình ngôn ngữ thông qua các lớp tuyến tính nhẹ. Điều này giúp kiến trúc đơn giản hơn và giảm đáng kể chi phí tính toán.
Giống Nemotron, Gemma 4 cũng hỗ trợ cửa sổ ngữ cảnh lên tới 256.000 token, đủ sức xử lý các tài liệu dài, dự án lập trình lớn, hội thoại kéo dài hoặc dữ liệu kết hợp giữa văn bản, hình ảnh, âm thanh và video.
Phù hợp nhất với: trợ lý AI đa phương thức, phân tích tài liệu, suy luận từ hình ảnh và âm thanh, phân tích khung hình video, lập trình, xử lý đa ngôn ngữ và các ứng dụng AI chạy cục bộ.
Qwen3-Omni 30B A3B Instruct
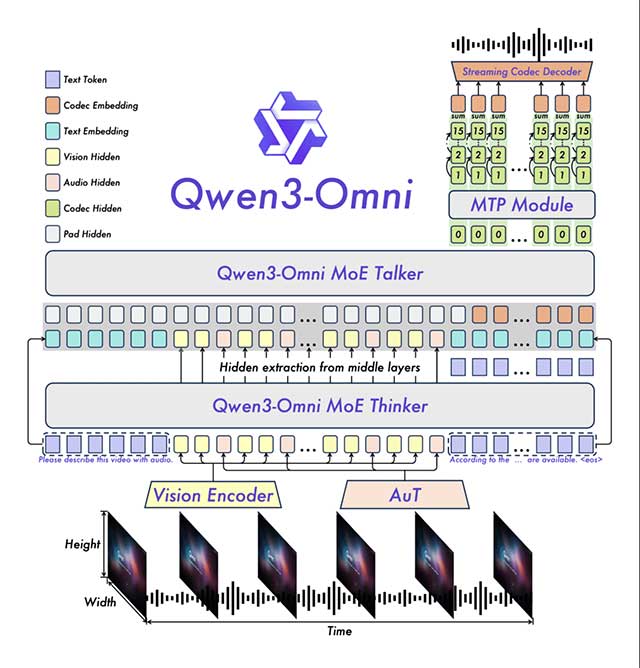
Qwen3-Omni 30B A3B Instruct hiện là một trong những mô hình AI Omni mã nguồn mở mạnh nhất hiện nay. Đây là mô hình đa phương thức đa ngôn ngữ được thiết kế theo hướng end-to-end, có thể tiếp nhận văn bản, hình ảnh, âm thanh và video, sau đó phản hồi bằng cả văn bản lẫn giọng nói tự nhiên.
Khả năng này giúp Qwen3-Omni trở thành nền tảng lý tưởng để xây dựng các trợ lý AI có thể quan sát, lắng nghe, suy luận và phản hồi gần như theo thời gian thực. Mô hình hỗ trợ nhận diện giọng nói, dịch lời nói, mô tả âm thanh, phân tích nhạc, OCR, trả lời câu hỏi về hình ảnh, hiểu video và hội thoại đa phương thức.
Bên trong, Qwen3-Omni sử dụng kiến trúc Mixture-of-Experts với thiết kế Thinker - Talker . Thành phần Thinker đảm nhiệm việc hiểu và suy luận đa phương thức, trong khi Talker chịu trách nhiệm tạo giọng nói tự nhiên. Cách phân chia này giúp mô hình vừa có khả năng suy luận sâu, vừa duy trì tốc độ phản hồi rất thấp.
Một trong những ưu điểm lớn nhất của Qwen3-Omni là khả năng tương tác âm thanh và video theo thời gian thực. Không giống nhiều mô hình phải chờ người dùng tải dữ liệu lên rồi mới xử lý, Qwen3-Omni được thiết kế để làm việc với luồng dữ liệu liên tục, cho phép phản hồi ngay bằng văn bản hoặc giọng nói.
Khả năng đa ngôn ngữ của mô hình cũng rất ấn tượng khi hỗ trợ 119 ngôn ngữ văn bản, 19 ngôn ngữ đầu vào bằng giọng nói và 10 ngôn ngữ đầu ra bằng giọng nói. Đây là lợi thế lớn đối với các trợ lý AI toàn cầu, công cụ hỗ trợ người khuyết tật hoặc các hệ thống xử lý âm thanh - video đa ngôn ngữ.
Không chỉ hiểu nhiều loại dữ liệu đầu vào, Qwen3-Omni còn có thể tạo giọng nói tự nhiên, thực hiện theo system prompt, hỗ trợ các quy trình kiểu AI Agent và xử lý những tác vụ âm thanh - hình ảnh phức tạp. Đây cũng là mô hình tiến gần nhất tới khái niệm "trợ lý AI Omni" đúng nghĩa.
Phù hợp nhất với: trợ lý AI Omni, hội thoại giọng nói theo thời gian thực, phân tích video, suy luận từ âm thanh, ứng dụng đa ngôn ngữ và phản hồi bằng cả văn bản lẫn giọng nói.
DeepSeek Janus-Pro 7B

Khác với các mô hình phía trên, DeepSeek Janus-Pro 7B không phải là AI Omni hoàn chỉnh dành cho văn bản, âm thanh, hình ảnh và video. Tuy nhiên, đây vẫn là một trong những mô hình mã nguồn mở đáng chú ý nhờ kết hợp khả năng hiểu hình ảnh và tạo hình ảnh trong cùng một hệ thống.
Janus-Pro phù hợp với các tác vụ như trả lời câu hỏi dựa trên hình ảnh, suy luận trực quan, mô tả nội dung ảnh, tạo ảnh từ văn bản và các quy trình sáng tạo đa phương thức.
Mô hình được xây dựng trên DeepSeek-LLM-7B với kiến trúc tự hồi quy (autoregressive) mới, trong đó tách riêng luồng xử lý dành cho việc hiểu hình ảnh và luồng phục vụ sinh ảnh. Thiết kế này giải quyết một trong những hạn chế phổ biến của AI đa phương thức khi cùng một bộ mã hóa hình ảnh phải đảm nhận cả hai nhiệm vụ.
Ở chế độ hiểu hình ảnh, Janus-Pro sử dụng bộ mã hóa SigLIP-L và hỗ trợ ảnh đầu vào có độ phân giải 384 × 384 pixel. Trong khi đó, chức năng tạo ảnh sử dụng một bộ tokenizer chuyên biệt để sinh ảnh trực tiếp từ câu lệnh văn bản.
Việc tách biệt hai quy trình nhưng vẫn duy trì một Transformer thống nhất giúp Janus-Pro đạt hiệu quả tốt ở cả khả năng phân tích lẫn tạo ảnh.
Phù hợp nhất với: hiểu hình ảnh, suy luận trực quan, mô tả ảnh, trả lời câu hỏi dựa trên hình ảnh và tạo ảnh từ văn bản.
MiniCPM-o 4.5
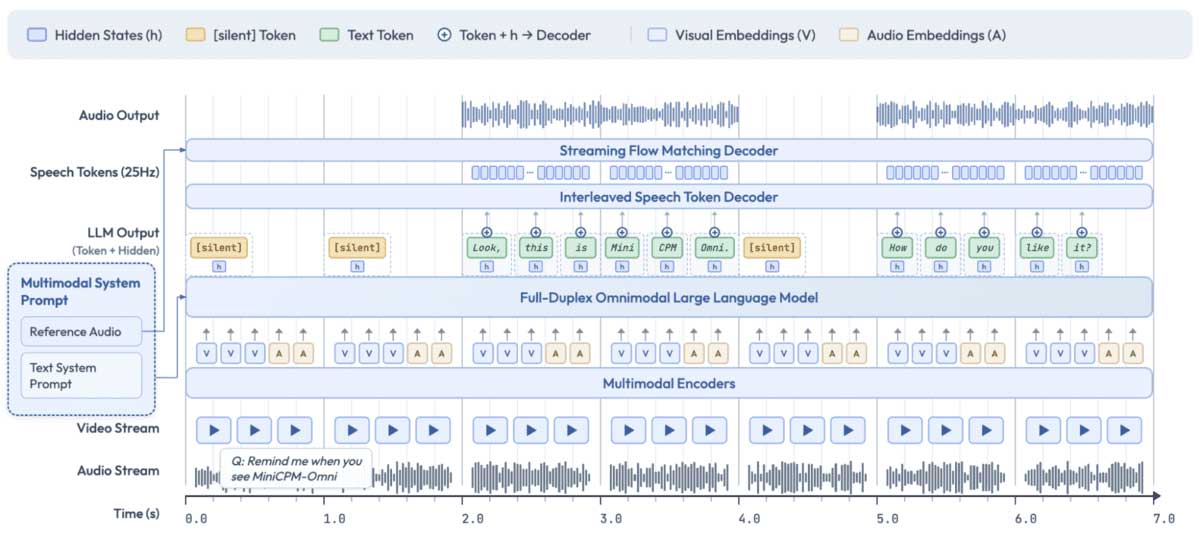
MiniCPM-o 4.5 là một trong những mô hình AI Omni mã nguồn mở đáng chú ý nhất hiện nay nhờ tập trung vào xử lý hình ảnh, giọng nói và truyền phát đa phương thức hai chiều (full-duplex) theo thời gian thực.
Mô hình có thể xử lý văn bản, hình ảnh, video và âm thanh, sau đó phản hồi bằng cả văn bản lẫn giọng nói. Đây là nền tảng phù hợp để xây dựng các trợ lý AI có thể quan sát, lắng nghe và trò chuyện đồng thời với người dùng.
MiniCPM-o 4.5 hỗ trợ nhiều tác vụ như hội thoại giọng nói theo thời gian thực, hiểu video, OCR, phân tích tài liệu, trả lời câu hỏi về hình ảnh và xây dựng trợ lý AI đa phương thức.
Mô hình có tổng cộng khoảng 9 tỷ tham số và kết hợp nhiều thành phần nổi tiếng như SigLIP2, Whisper-medium, CosyVoice2 và Qwen3-8B. Nhờ đó, MiniCPM-o sở hữu khả năng xử lý hình ảnh, giọng nói và ngôn ngữ khá mạnh trong khi vẫn đủ nhỏ để triển khai cục bộ.
Điểm nổi bật nhất của MiniCPM-o 4.5 là khả năng xử lý luồng video và âm thanh liên tục. Thay vì chờ người dùng tải dữ liệu lên rồi mới phản hồi, mô hình có thể theo dõi dòng dữ liệu trực tiếp và đồng thời tạo văn bản cũng như giọng nói.
MiniCPM-o còn hỗ trợ tương tác chủ động. AI có thể liên tục quan sát khung cảnh, tự quyết định thời điểm phát biểu, đưa ra nhận xét hoặc phản hồi mà không cần đợi người dùng gửi lệnh.
Khả năng OCR và hiểu hình ảnh của mô hình cũng rất mạnh khi hỗ trợ ảnh độ phân giải cao, video tốc độ khung hình lớn và tài liệu với nhiều tỷ lệ khác nhau. Điều này đặc biệt hữu ích trong các ứng dụng phân tích tài liệu, nhận diện giao diện màn hình và AI thị giác.
Một ưu điểm lớn khác là khả năng triển khai linh hoạt. MiniCPM-o hỗ trợ PyTorch trên GPU NVIDIA, đồng thời tương thích với llama.cpp, Ollama, GGUF, vLLM và SGLang, giúp các nhà phát triển dễ dàng chạy mô hình trên máy tính cá nhân, máy chủ GPU hoặc các thiết bị biên (edge device).
Phù hợp nhất với: trợ lý AI đa phương thức thời gian thực, xử lý video và âm thanh trực tiếp, hội thoại bằng giọng nói, OCR, phân tích tài liệu, Edge AI và các ứng dụng Omni hai chiều.
Các mô hình AI Omni đang trở thành xu hướng quan trọng khi AI dần vượt khỏi phạm vi chatbot để tiến tới những hệ thống có thể hỗ trợ con người trong các tình huống thực tế.
Trong cuộc sống hàng ngày, dữ liệu không chỉ tồn tại dưới dạng văn bản mà còn bao gồm hình ảnh, tài liệu, âm thanh, video, ảnh chụp màn hình, biểu đồ hay các cuộc họp trực tuyến. Để AI thực sự hữu ích, nó cần có khả năng hiểu tất cả những nguồn thông tin này một cách tự nhiên.
Trước đây, việc xây dựng một hệ thống như vậy thường đòi hỏi phải kết hợp nhiều mô hình AI khác nhau, từ nhận diện giọng nói, thị giác máy tính, OCR đến mô hình ngôn ngữ và mô hình tạo nội dung. Cách tiếp cận này tuy hiệu quả nhưng làm tăng độ phức tạp, độ trễ cũng như chi phí triển khai.
Xu hướng hiện nay đang đi theo hướng tích hợp nhiều khả năng trực tiếp vào cùng một mô hình. Thay vì ghép nối nhiều hệ thống riêng biệt, các mô hình Omni có thể quan sát, lắng nghe, suy luận và phản hồi trong cùng một kiến trúc, giúp giảm đáng kể độ trễ và mang lại trải nghiệm tự nhiên hơn.
Đây sẽ là nền tảng quan trọng cho thế hệ trợ lý AI thời gian thực, AI Agent, hệ thống phân tích video, xử lý tài liệu, công cụ hỗ trợ người khuyết tật và nhiều ứng dụng AI đa phương thức khác trong tương lai.






 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học