 AI
AI  ChatGPT
ChatGPT  Gemini
Gemini  Thư viện Prompt
Thư viện Prompt  Công nghệ
Công nghệ  Học IT
Học IT  Tiện ích
Tiện ích 
Khái niệm MCM (Multi-Chiplet Module - Mô-đun Đa Chiplet) không hoàn toàn mới trong phân khúc đồ họa, nhưng với những hạn chế của thiết kế đơn khối (monolithic), xu hướng hướng tới MCM trong ngành chắc chắn đang tăng lên. AMD có vẻ như là một trong những hãng giàu kinh nghiệm trong thiết kế đa chiplet, với nòng cốt là dòng sản phẩm AI Instinct MI200. Đây là thế hệ GPU đầu tiên của AMD sở hữu thiết kế MCM với nhiều chiplet xếp chồng trên một gói duy nhất, như các GPC (Graphics Processing Cores), ngăn HBM và die I/O. Với dòng Instinct MI350, AMD đã thực hiện một cách tiếp cận khá mới, mà nếu thành công sẽ trở thành nền tảng cho GPU tiêu dùng dựa trên chiplet,
Hiện tại, hạn chế lớn nhất khi áp dụng thiết kế chiplet với GPU chơi game là độ trễ cao hơn, vì các khung hình không dung thứ cho việc dữ liệu phải "nhảy" qua khoảng cách dài, và để giải quyết vấn đề này, AMD cần đưa ra giải pháp thu hẹp khoảng cách giữa dữ liệu và tính toán một cách gần nhất có thể. Dựa trên một đơn đăng ký cấp bằng sáng chế mới được tiết lộ, người ta phát hiện ra rằng AMD có thể đã giải mã thành công cho GPU chơi game "đa chiplet". Thú vị là bằng sáng chế đã tiết lộ chi tiết về CPU thay vì GPU, nhưng văn bản và cơ chế chỉ ra rằng nó nhắm đến trường hợp sử dụng đồ họa.
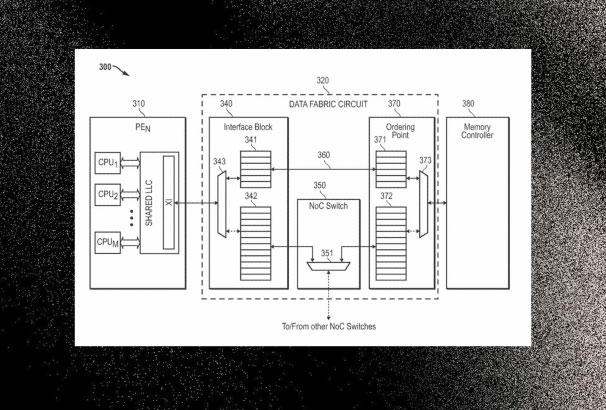
Vậy, chính xác thì AMD sẽ sử dụng thiết kế đa chiplet với GPU như thế nào? Thành phần chính trong bằng sáng chế được cho là một "mạch data-fabric với một công tắc thông minh" cầu nối giao tiếp giữa các chiplet tính toán và bộ điều khiển bộ nhớ. Về cơ bản, nó là Infinity Fabric của AMD, nhưng được thu nhỏ cho GPU phổ thông, vì Team Red không thể sử dụng các die bộ nhớ HBM. Công tắc được thiết kế để tối ưu hóa truy cập bộ nhớ bằng cách đầu tiên so sánh xem yêu cầu cho một tác vụ đồ họa có cần di chuyển tác vụ (task migration) hay sao chép dữ liệu (data replication) hay không, với độ trễ quyết định ở mức nano giây.
Khi vấn đề truy cập dữ liệu đã được giải quyết, bằng sáng chế đề xuất có các GCD với bộ đệm L1 và L2, tương tự như những gì đang xảy ra với gia tốc AI. Tuy nhiên, một bộ đệm L3 chia sẻ bổ sung (hoặc SRAM xếp chồng) có thể được truy cập thông qua công tắc, vốn được sử dụng kết nối tất cả các GCD. Điều này sẽ giảm nhu cầu truy cập bộ nhớ toàn cục (global memory), và quan trọng hơn, hoạt động như một vùng chia sẻ chung (shared staging zone) giữa các chiplet, tương tự như những gì AMD làm với 3D V-Cache của họ, ngoại trừ việc nó chủ yếu dành cho bộ xử lý. Sau đó, còn có DRAM xếp chồng tham gia, về cơ bản là nền tảng cho một thiết kế MCM.
Điều khiến sự xuất hiện của các bằng sáng chế đa chiplet lần này trở nên đáng chú ý ở chỗ AMD về cơ bản đã sẵn sàng về hệ sinh thái. Công ty có thể sử dụng cầu nối InFO-RDL của TSMC và một phiên bản cụ thể của Infinity Fabric giữa các die để đóng gói. Và điều khiến việc triển khai này trở nên hấp dẫn hơn nữa là nó là một phiên bản thu nhỏ của gia tốc AI. Trước đây, AMD đã từng có kế hoạch hợp nhất kiến trúc chơi game và AI của mình dưới một nền tảng duy nhất: kiến trúc UDNA.

Với những hạn chế của thiết kế đơn khối, ngành công nghiệp đồ họa cần một sự thay đổi, và AMD có thể đang nắm trong tay một trong những cơ hội tốt nhất để vươn lên dẫn đầu. Tuy nhiên, có những phức tạp cần giải quyết với thiết kế chiplet, một trong số đó AMD đã trải nghiệm với nền tảng RDNA 3, liên quan đến độ trễ do kết nối chiplet gây ra. Tuy nhiên, với cách tiếp cận mới, kết hợp với bộ đệm L3 chia sẻ bổ sung, Team Red hy vọng giải quyết các vấn đề về độ trễ; tuy nhiên, đây chắc chắn không phải nhiệm vụ đơn giản.
















 AI
AI  Hướng dẫn AI
Hướng dẫn AI  Ứng dụng
Ứng dụng  Hệ thống
Hệ thống  Game - Trò chơi
Game - Trò chơi  iPhone
iPhone  Android
Android  Hàm Excel
Hàm Excel  Download
Download  Khoa học
Khoa học  Cuộc sống
Cuộc sống  Làng Công nghệ
Làng Công nghệ