 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Lập trình công cụ phân tích tâm lý không hề dễ với nhiều người. Hướng dẫn dưới đây sẽ giúp bạn xây dựng một chương trình phân tích tâm lý theo cách đơn giản nhất.

Phân tích tâm lý/quan điểm là một kỹ thuật xử lý ngôn ngữ tự nhiên, nhằm xác định thái độ đằng sau một văn bản. Nó còn được gọi là khai thác ý kiến. Mục tiêu của phân tích quan điểm là xác định xem một văn bản nào đó có tính chất tích cực, tiêu cực hay trung tính. Nó thường được sử dụng rộng rãi trong doanh nghiệp để tự động phân loại quan điểm trong đánh giá khách hàng. Phân tích số lượng lớn đánh giá giúp bạn thu được thông tin chi tiết đáng giá về sở thích của khách hàng.
Thiết lập môi trường
Bạn cần làm quen với những kiến thức Python cơ bản để làm theo hướng dẫn dưới đây. Tới Google Colab hoặc mở Jupyter Notebook. Sau đó, tạo một notebook mới. Thực hiện lệnh sau để cài các thư viện cần thiết trong môi trường của bạn.
! pip install tensorflow scikit-learn pandas numpy pickle5Bạn sẽ dùng thư viện NumPy và pandas để xử lý dataset. Sử dụng TensorFlow tạo và huấn luyện mô hình học máy. Scikit-learn để tách dataset thành các nhóm đào tạo và kiểm thử. Cuối cùng, bạn sẽ dùng pickle5 để tuần tự hóa và lưu đối tượng tokenizer.
Nhập các thư viện cần thiết
Nhập các thư viện cần thiết cho việc xử lý trước dữ liệu vào tạo mẫu.
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense, Dropout
import pickle5 as pickleBạn sẽ dùng những class nhập từ các mô đun sau đó trong code này.
Tải dataset
Ví dụ sẽ dùng dataset Trip Advisor Hotel Reviews từ Kaggle để xây dựng mô hình phân tích cảm xúc/quan điểm.
df = pd.read_csv('/content/tripadvisor_hotel_reviews.csv')
print(df.head())Tải dataset và in 5 hàng đầu tiên. In 5 hàng đầu tiên sẽ giúp bạn kiểm tra tên cột của dataset. Điều này quan trọng khi xử lý trước dataset.

Dataset Trip Advisor Hotel Reviews có một cột index, một cột Review và một cột Rating.
Xử lý trước dữ liệu
Chọn các cột Review và Rating từ dataset. Tạo một cột mới dựa trên cột Rating và đặt tên sentiment cho nó. Nếu xếp hạng lớn hơn 3, nhãn sentiment hay cảm xúc ở trạng thái positive - tích cực. Nếu đánh giá thấp hơn 3, nhãn là negative - tiêu cực. Nếu đánh giá bằng 3, nhãn ở mức neutral - trung bình.
Chỉ chọn cột Review và quan điểm từ dataset. Trộn ngẫu nhiên các hàng và thiết lập lại chỉ mục của khung dữ liệu. Xáo trộn và reset đảm bảo dữ liệu được phân bổ ngẫu nhiên, điều này cần thiết cho việc đào tạo và kiểm tra mô hình đúng cách.
df = df[['Review', 'Rating']]
df['sentiment'] = df['Rating'].apply(lambda x: 'positive' if x > 3
else 'negative' if x < 3
else 'neutral')
df = df[['Review', 'sentiment']]
df = df.sample(frac=1).reset_index(drop=True)Chuyển đổi text Review thành một chuỗi số nguyên bằng thuật toán tách từ. Điều này tạo một từ điển các từ độc đáo hiện có ở nội dung Review và sắp xếp mỗi từ với một giá trị số nguyên độc đáo. Dùng hàm pad_sequences từ Keras để đảm bảo tất cả các chuỗi đánh giá đều có cùng độ dài.
tokenizer = Tokenizer(num_words=5000, oov_token='<OOV>')
tokenizer.fit_on_texts(df['Review'])
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(df['Review'])
padded_sequences = pad_sequences(sequences, maxlen=100, truncating='post')Chuyển đổi nhãn quan điểm sang mã hóa One-hot
sentiment_labels = pd.get_dummies(df['sentiment']).valuesMã hóa One-hot trình bày dữ liệu phân loại ở định dạng dễ hơn cho mô hình hoạt động.
Tách dataset thành các nhóm huấn luyện và kiểm thử
Dùng scikit-learn để tách dataset ngẫu nhiên thành các nhóm đào tạo và kiểm tra. Bạn sẽ dùng nhóm traning để đào tạo mô hình phân loại quan điểm của các đánh giá, còn nhóm test được dùng để phân loại mức độ phân loại đánh giá mới của mô hình.
x_train, x_test, y_train, y_test = train_test_split(padded_sequences, sentiment_labels, test_size=0.2)Kích thước phân tách của dataset là 0.2. Điều đó có nghĩa 80% dữ liệu sẽ huấn luyện mô hình này. 20% còn lại sẽ kiểm tra hiệu quả hoạt động của mô hình.
Tạo mạng nơ ron nhân tạo
Tạo một mạng nơ ron nhân tạo với 6 lớp.
model = Sequential()
model.add(Embedding(5000, 100, input_length=100))
model.add(Conv1D(64, 5, activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(3, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()Lớp đầu tiên của mạng này là Embedding. Layer này học cách trình bày dày đặc các từ trong từ vựng. Lớp thứ hai là layer Conv1D với 64 bộ lọc và kích thước hạt nhân là 5. Layer này thực hiện các thao tác tích chập trên những chuỗi đầu vào, dùng một cửa sổ dạng trượt nhỏ (có kích thước 5).
Lớp thứ 3 giảm trình tự các bản đồ đặc trưng thành một vectơ duy nhất. Nó lấy giá trị tối đa trên mỗi bản đồ tính năng. Lớp thứ 4 thực hiện phép biến đổi tuyến tính trên vectơ đầu vào. Lớp thứ 5 đặt ngẫu nhiên một phần của các đơn vị đầu vào thành 0 trong quá trình đào tạo. Điều này giúp ngăn chặn tình trạng quá mức. Lớp cuối cùng chuyển đổi đầu ra thành phân bổ xác suất trên ba lớp có thể: tích cực, trung lập và tiêu cực.
Đào tạo mạng nơ ron nhân tạo
Khớp các nhóm đào tạo và kiểm tra cho mô hình. Huấn luyện mô hình trong 10 giai đoạn. Bạn có thể thay đổi số giai đoạn như ý thích.
model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_test, y_test))Sau mỗi giai đoạn, hiệu quả của mô hình khi thử nghiệm sẽ được đánh giá.
Đánh giá hiệu quả của mô hình được huấn luyện
Dùng phương thức model.predict() để dự đoán các nhãn quan điểm cho nhóm test. Tính điểm chính xác bằng hàm accuracy_score() từ scikit-learn.
y_pred = np.argmax(model.predict(x_test), axis=-1)
print("Accuracy:", accuracy_score(np.argmax(y_test, axis=-1), y_pred))Độ chính xác của mô hình này vào khoảng 84%.
Lưu mô hình
Lưu mô hình bằng phương thức model.save(). Dùng pickle để tuần tự hóa và lưu đối tượng tokenizer.
model.save('sentiment_analysis_model.h5')
with open('tokenizer.pickle', 'wb') as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)Đối tượng tokenizer sẽ phân tách nội dung bạn nhập và và chuẩn bị cung cấp nó cho mô hình được đào tạo.
Dùng mô hình để phân loại quan điểm của văn bản
Sau khi tạo và lưu mô hình, bạn có thể dùng nó để phân loại quan điểm của văn bản cá nhân. Đầu tiên, tải mô hình đã lưu và tokenizer.
# Load the saved model and tokenizer
import keras
model = keras.models.load_model('sentiment_analysis_model.h5')
with open('tokenizer.pickle', 'rb') as handle:
tokenizer = pickle.load(handle)Định nghĩa một hàm để dự đoán quan điểm của văn bản nhập vào.
def predict_sentiment(text):
# Tokenize and pad the input text
text_sequence = tokenizer.texts_to_sequences([text])
text_sequence = pad_sequences(text_sequence, maxlen=100)
# Make a prediction using the trained model
predicted_rating = model.predict(text_sequence)[0]
if np.argmax(predicted_rating) == 0:
return 'Negative'
elif np.argmax(predicted_rating) == 1:
return 'Neutral'
else:
return 'Positive'Cuối cùng, dự đoán nội dung văn bản của bạn.
text_input = "I absolutely loved my stay at that hotel. The staff was amazing and the room was fantastic!"
predicted_sentiment = predict_sentiment(text_input)
print(predicted_sentiment)Bạn sẽ nhận được kết quả như sau:
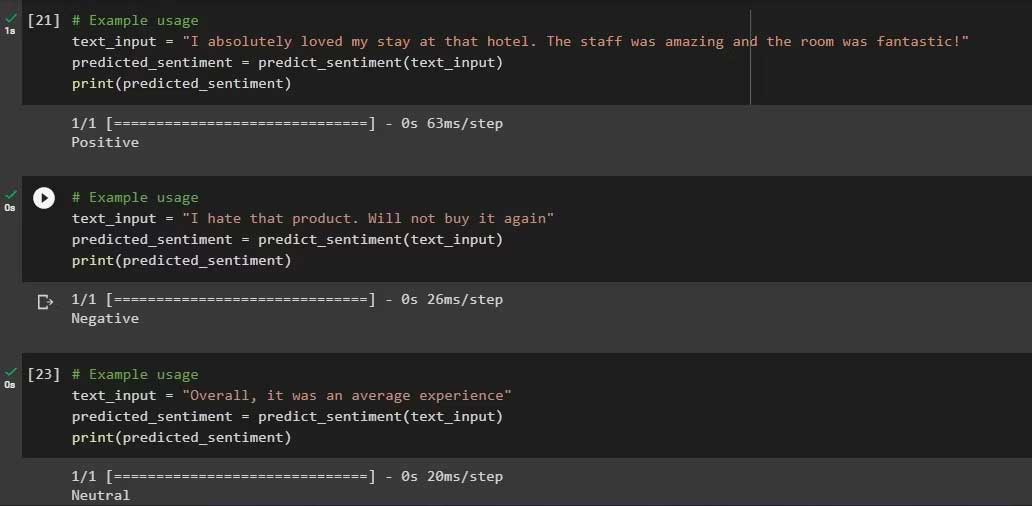
Trên đây là cách tạo một chương trình phân tích quan điểm bằng Python. Hi vọng bài viết hữu ích với các bạn.









 Lập trình
Lập trình
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học