 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

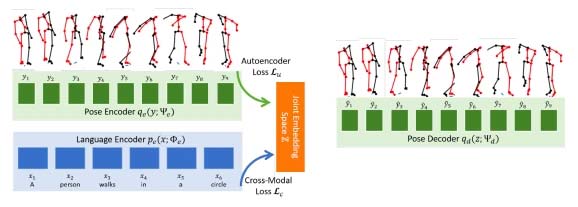
Các nhà nghiên cứu AI đến từ Đại học Carnegie Mellon, Pennsylvania, Hoa Kỳ mới đây đã phát triển thành công một mô hình AI chuyên sâu, có khả năng dịch các ngôn ngữ (văn bản, giọng nói) thành chuyển động, cử chỉ vật lý với độ chính xác tương đối cao.
Mô hình AI này được đặt tên là Joint Language-to-Pose (JL2P), đồng thời được biết đến như một phương pháp đem lại khả năng kết hợp ngôn ngữ tự nhiên với các mô hình mô phỏng tư thế 3D hiệu quả khi được ứng dụng vào thực tiễn trong tương lai gần.
 Mô hình AI này được đặt tên là Joint Language-to-Pose (JL2P)
Mô hình AI này được đặt tên là Joint Language-to-Pose (JL2P)
Khả năng phân tích và mô phỏng tư thế, cử chỉ trong không gian 3 chiều của JL2P được đào tạo kỹ lưỡng thông qua các chương trình end-to-end xuyên suốt - một cách tiếp cận mạnh mẽ và hiệu quả với việc các chương trình đào tạo được “xé nhỏ” theo dạng chuỗi riêng lẻ. Mô hình AI sẽ phải hoàn thành các nhiệm vụ ngắn, đơn giản trước khi được phép chuyển sang những mục tiêu phức tạp hơn.
Hiện tại, khả năng mô phỏng hoạt hình của JL2P đang được giới hạn ở dạng hình ảnh thô sơ (tạo thành từ các đường thẳng đơn giản), tuy nhiên khả năng mô phỏng chuyển động giống của con người dựa trên ngôn ngữ của mô hình AI này là tương đối chính xác và trực quan. Nhóm nghiên cứu tin rằng những mô hình như JL2P một ngày nào đó có thể giúp robot thực hiện các nhiệm vụ vật lý trong thế giới thực tương tự như con người, hoặc hỗ trợ sáng tạo nhân vật hoạt hình ảo cho trong trò chơi video cũng như phim ảnh.
 Khả năng mô phỏng hoạt hình của JL2P đang được giới hạn ở dạng hình ảnh thô sơ, đơn giản
Khả năng mô phỏng hoạt hình của JL2P đang được giới hạn ở dạng hình ảnh thô sơ, đơn giản
Thực ra ý tưởng phát triển một mô hình AI với khả năng dịch ngôn ngữ thành chuyển động vật lý không phải mới. Trước khi Đại học Carnegie Mellon giới thiệu JL2P, Microsoft cũng đã phát triển thành công một mô hình có tên ObjGAN, với nhiệm vụ chuyên phác họa hình ảnh và storyboard (bảng phác thảo lại câu chuyện bạn muốn kể dưới dạng hình ảnh) từ những chú thích dạng ngôn ngữ. Một mô hình AI khác của của Disney cũng đã được biết đến rộng rãi với khả năng sử dụng chính những từ ngữ trong kịch bản để tạo storyboard. Hay nổi tiếng hơn cả là mô hình GauGAN của Nvidia, có thế biến một bức vẽ nguệch ngoạc như được tạo ra bằng trackpad hoặc Microsoft Paint thành những bản phác thảo kỹ thuật số thông minh với tính thẩm mỹ cực cao.
Trở lại với JL2P, mô hình AI này hiện có thể mô phỏng rất chính xác một số chuyển động từ đơn giản đến tương đối phức tạp như đi bộ hoặc chạy, chơi nhạc cụ (như guitar hoặc violin), làm theo hướng dẫn định hướng (trái hoặc phải) hoặc điều khiển tốc độ (nhanh hoặc chậm).
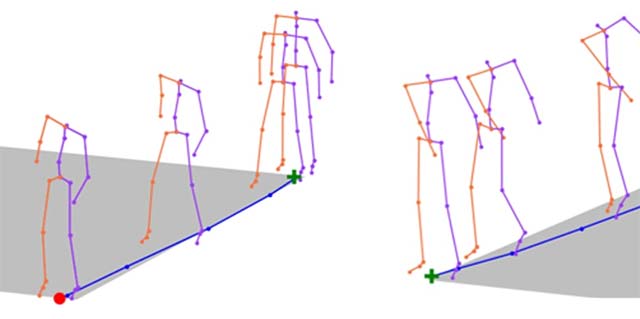 JL2P hiện có thể mô phỏng rất chính xác một số chuyển động từ đơn giản đến tương đối phức tạp
JL2P hiện có thể mô phỏng rất chính xác một số chuyển động từ đơn giản đến tương đối phức tạp
“Trước tiên chúng tôi tối ưu hóa mô hình để dự đoán 2 bước thời gian dựa trên những câu từ hoàn chỉnh. Nhiệm vụ đơn giản này có thể giúp mô hình AI học cách mô phỏng các chuỗi tư thế rất ngắn, chẳng hạn như chuyển động chân khi đi bộ, chuyển động tay trong khi vẫy hay tư thế, dáng người khi cúi đầu. Sau khi JL2P đã biết cách mô phỏng những cử chỉ tương tự với độ chính xác cao, chúng tôi sẽ chuyển sang giai đoạn tiếp theo trong chương trình giảng dạy. Mô hình hiện được đưa ra 2 lần (số) tư thế để dự đoán trong cùng một lúc”, nhóm nghiên cứu Đại học Carnegie Mellon cho biết.
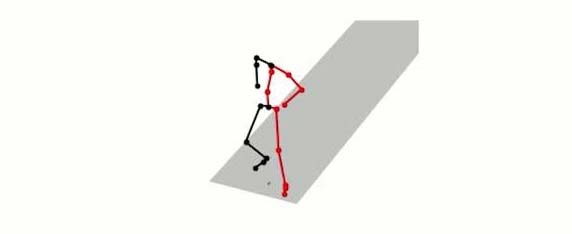 Mô phỏng tư thế chạy bộ của một người bình thường
Mô phỏng tư thế chạy bộ của một người bình thường
Chi tiết về phương thức hoạt động cũng như các “tác phẩm” điển hình của JL2P đã được trình bày lần đầu tiên trong một bài báo khoa học xuất bản ngày 2 tháng 7 trên chuyên trang arXiv.org, và dự kiến sẽ được trình bày bởi chính hội đồng tác giả và các nhà nghiên cứu của Viện Công nghệ Ngôn ngữ CMU Chaitanya Ahuja vào ngày 19 tháng 9 tới đây, trên sân khấu của Hội nghị Quốc tế về 3D Vision diễn ra ở Quebec, Canada.
Nhóm nghiên cứu tự tin khẳng định JL2P có thể cho khả năng mô phỏng tư thế cũng như chuyển động vật lý chính xác hơn 9% so với một mô hình AI “đỉnh cao” khác được phát triển bởi các chuyên gia AI của SRI International vào năm 2018.
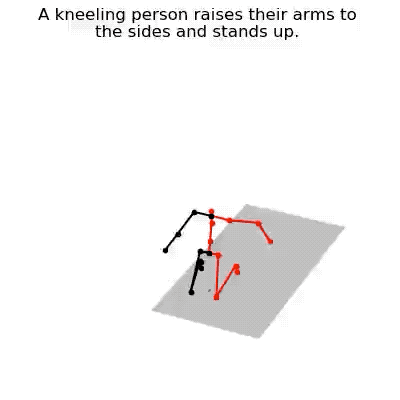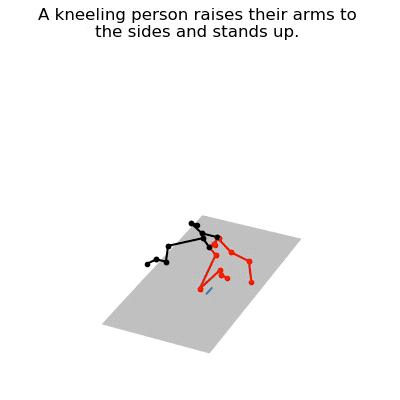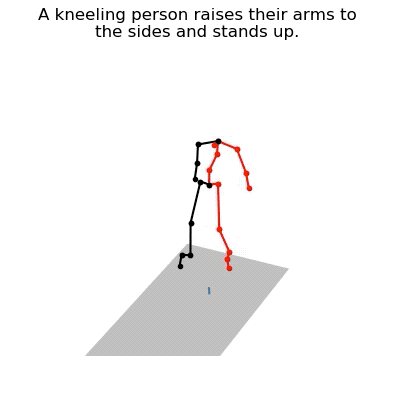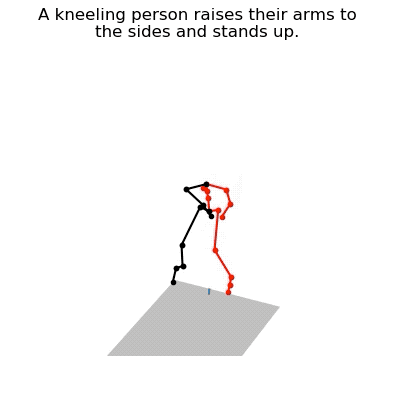 JL2P mô phỏng hành động chống tay đứng dậy của con người
JL2P mô phỏng hành động chống tay đứng dậy của con người
Sản phẩm tạo ra bởi JL2P sau khi được đào tạo bằng bộ dữ liệu ngôn ngữ chuyển động KIT (KIT Motion-Language Dataset).
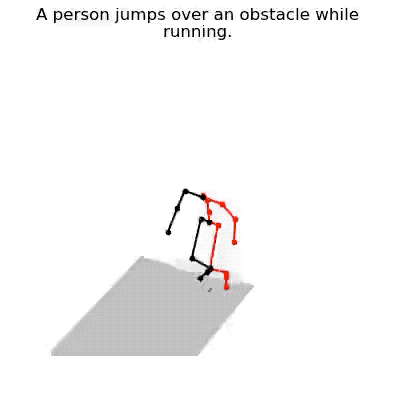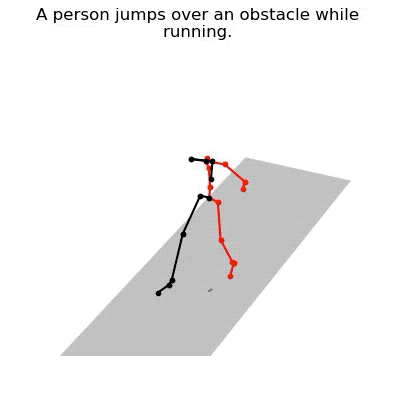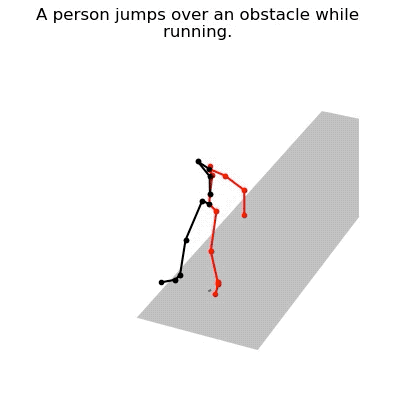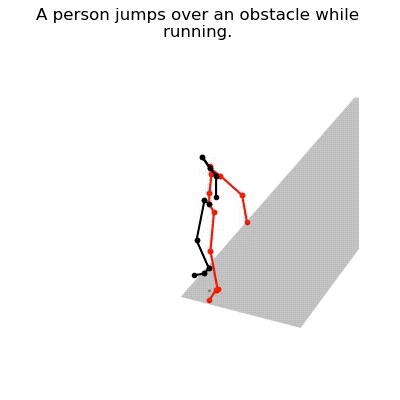 JL2P mô phỏng hành động nhảy qua qua chướng ngại vật và chạy
JL2P mô phỏng hành động nhảy qua qua chướng ngại vật và chạy
Được giới thiệu lần đầu vào năm 2016 bởi tổ chức Performance Humanoid Technologies, Đức, bộ dữ liệu đào này là một sự kết hợp của chuyển động con người với các mô tả ngôn ngữ tự nhiên, ánh xạ 11 giờ chuyển động liên tục một người, được ghi lại thành hơn 6.200 câu tiếng Anh, mỗi câu có độ dài khoảng 8 từ.









 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học