 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Như chúng ta đã biết, việc đào tạo các mạng lưới thần kinh sâu (deep neural networks) đòi hỏi lượng dữ liệu cực lớn. Ngoài ra, tùy thuộc vào kiến trúc AI bạn đang nắm trong tay mà dữ liệu đó sẽ không thể được sử dụng nhiều lần nếu nó chưa được gắn nhãn, điều này sẽ rất mất thời gian - đặc biệt là khi bạn đang triển khai các dự án với quy mô lên tới hàng trăm ngàn đối tượng.
Để giảm bớt gánh nặng cho các chuyên gia chú thích dữ liệu cũng như các nhà khoa học dữ liệu, Intel đã phát hành một chương trình mới với mã nguồn mở, đó là công cụ chú thích thị giác máy tính (Computer Vision Annotation Tool - CVAT), được xây dựng để hỗ trợ việc đơn giản hóa và đẩy nhanh quá trình chú thích những mẫu video và hình ảnh được sử dụng để huấn luyện các thuật toán thị giác máy tính. Intel có thông báo trong một bài đăng trên blog của họ như sau:
“Để tăng tốc quá trình chú thích dữ liệu trong lĩnh vực Computer Vision, chúng tôi đã phát triển một chương trình có tên CVAT. Nhìn chung, có nhiều cách để bạn chú thích dữ liệu, nhưng việc sử dụng các công cụ đặc biệt như CVAT có thể giúp quá trình này trở nên đơn giản và nhanh gọn hơn".
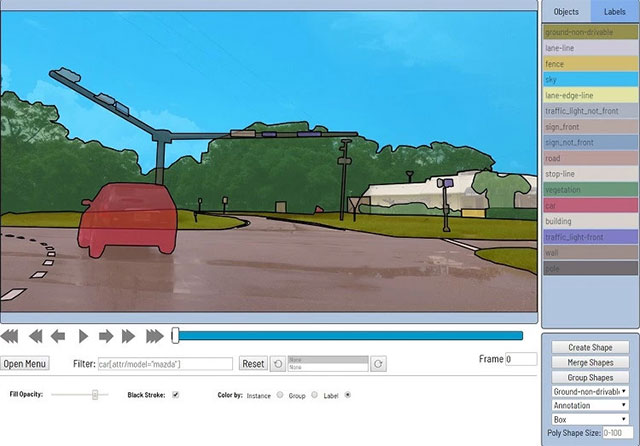
Như công ty quản lý dữ liệu Santa Clara đã giải thích trước đó, CVAT sẽ triển khai thông qua Docker và được truy cập thông qua giao diện dựa trên trình duyệt (hoặc được nhúng theo tùy chọn vào các nền tảng như Onepanel), đồng thời sở hữu hệ thống quản lý dựa trên nhiệm vụ được tối ưu hóa cho công việc cụ thể (người dùng tạo các tác vụ công khai để phân chia công việc với nhau). Bên cạnh đó, CVAT cũng hỗ trợ các tác vụ học máy được giám sát liên quan đến phát hiện đối tượng, phân loại hình ảnh, phân đoạn hình ảnh và chú thích với 1 trong 4 loại hình: hộp, đa giác, đa nét và đa điểm.
Trong CVAT, các trình chú thích chứa đựng rất nhiều công cụ để sao chép và truyền bá các đối tượng, áp dụng bộ lọc, điều chỉnh cài đặt trực quan, thực hiện chú thích tự động, hay phát hiện đối tượng thông qua API TensorFlow framework của Google… Ngoài ra, CVAT cũng sẽ thực hiện một số kiểm tra tự động (nhưng không phải tất cả), và có khả năng tương thích độc đáo với các bộ công cụ phân tích dữ liệu như của Intel, OpenVino, Nvidia, Cuda và ELK (Elaticsearch, Logstash và Kibana).

Có thể nói, CVAT là sự tổng hợp của rất nhiều công việc trong một quá trình. Intel lưu ý rằng bộ công cụ này chỉ mới được thử nghiệm rộng rãi với Chrome, và không khuyến khích sử dụng với Chrome Sandbox (tính năng "hộp cát" trong Chrome giúp giới hạn môi trường đối với các quy trình, bao gồm cả việc sử dụng RAM và ảnh hưởng tiêu cực đến hiệu suất của bộ công cụ này). Tuy nhiên, Intel cũng cam kết sẽ cải thiện dần điểm yếu này của CVAT trong thời gian tới.
“CVAT được xây dựng cho các đội ngũ phát triển thuật toán và chú thích chuyên nghiệp, đồng thời cũng nhận được sự hỗ trợ rất lớn từ chính những người này, và chúng tôi đã cố gắng cung cấp những tính năng hữu ích nhất. Phản hồi từ phía người dùng sẽ giúp Intel xác định rõ hơn phương hướng về việc phát triển CVAT trong tương lai. Chúng tôi hy vọng sẽ sớm cải thiện trải nghiệm người dùng, bộ tính năng, tính ổn định, tính năng tự động hóa và khả năng tương thích với các dịch vụ khác của CVAT. Đồng thời Intel cũng khuyến khích những người quan tâm trên toàn thế giới tham gia tích cực vào việc phát triển bộ công cụ này”.

Intel đã quyết định phát hành CVAT chỉ vài tuần sau khi Uber chính thức mở nguồn hệ thống trực quan tự động (một nền tảng dựa trên web cho dữ liệu phương tiện), và khi các công ty khởi nghiệp cũng hoạt động trong lĩnh vực chú thích dữ liệu như Scale và Hive bắt đầu tăng vốn đầu tư mạo hiểm và thu hút được nhiều khách hàng lớn như Uber và General Motors.





 Làng Công nghệ
Làng Công nghệ
 Chuyện công nghệ
Chuyện công nghệ
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học