 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Hàm SCAN làm cho REGEX trở nên tốt hơn nữa
Kết hợp cả hai để giải quyết các vấn đề phức tạp
Hàm SCAN xử lý các mảng theo từng hàng và trả về kết quả tích lũy. Nó duyệt qua toàn bộ phạm vi, áp dụng một hàm cho mỗi giá trị trong khi vẫn theo dõi những giá trị trước đó, không giống như các hàm tiêu chuẩn chỉ hoạt động trên những ô đơn lẻ.
Nó sử dụng cú pháp sau:
=SCAN([initial_value], array, lambda)Hãy cùng phân tích các tham số:
- initial_value (tùy chọn): Để chọn điểm bắt đầu cho phép tính của bạn. Nếu bỏ qua, SCAN sẽ sử dụng phần tử đầu tiên của mảng làm giá trị tích lũy ban đầu, do đó các phép toán của hàm lambda sẽ bắt đầu từ phần tử đó.
- array: Phạm vi các ô cần xử lý.
- lambda: Một hàm tùy chỉnh xác định cách xử lý mỗi giá trị. Lambda cho phép bạn viết công thức như một con người và nhận hai đối số - kết quả tích lũy và giá trị hiện tại.
Hàm SCAN rất hữu ích cho việc tính tổng hoặc xử lý có điều kiện. Nhưng khi được kết hợp với hàm REGEX, bạn có thể trích xuất những mẫu từ toàn bộ các cột và dọn dẹp dữ liệu lộn xộn trong một công thức.
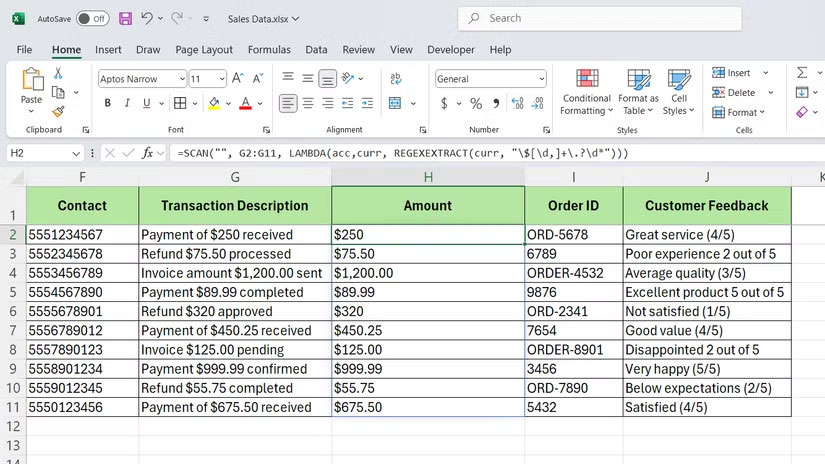
Hãy cùng xem một ví dụ thực tế. Trong bảng tính dữ liệu bán hàng, cột G chứa các mô tả giao dịch với số tiền được ẩn bên trong văn bản - chẳng hạn như "Đã nhận khoản thanh toán 250 USD" hoặc "Đã xử lý khoản hoàn lại 75,50 USD". Bạn chỉ cần số tiền bằng USD.
Công thức REGEXEXTRACT tiêu chuẩn hoạt động với một ô:
=REGEXEXTRACT(D2, "\$\d+\.?\d*")Nhưng để xử lý toàn bộ cột, thông thường bạn sẽ phải kéo công thức xuống hàng trăm hàng. Với hàm SCAN, bạn có thể xử lý tất cả cùng một lúc, chỉ cần sử dụng:
=SCAN("", G2:G11, LAMBDA(acc, curr, REGEXEXTRACT(curr, "\$[\d,]+\.?\d*")))Công thức này lặp qua các ô từ G2 đến G11, trích xuất số tiền bằng USD từ mỗi ô và trả về toàn bộ mảng. Giá trị tích lũy (acc) không cần thiết ở đây vì chúng ta chỉ đang trích xuất, nhưng SCAN vẫn yêu cầu nó trong cấu trúc lambda.
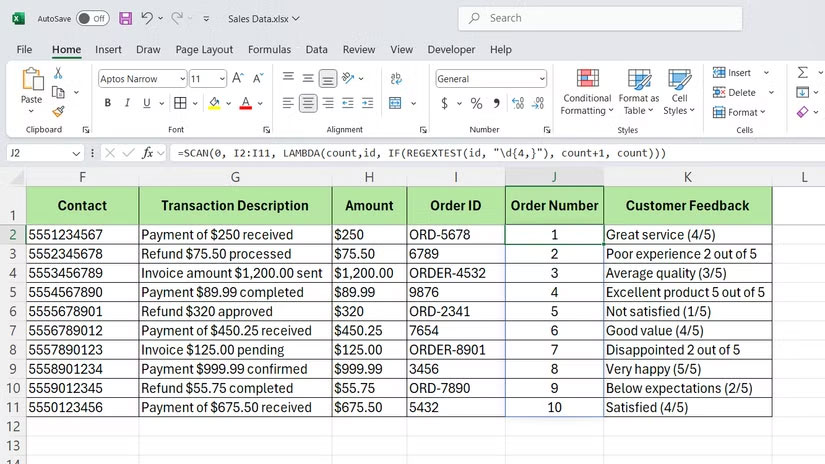
Công cụ này rất hữu ích khi bạn cần xây dựng dựa trên các kết quả trước đó. Giả sử cột I theo dõi các ID đơn hàng được định dạng không nhất quán - một số có tiền tố, một số thì không. Nếu muốn trích xuất phần số và tạo một bộ đếm các ID hợp lệ, bạn sẽ sử dụng:
=SCAN(0, E2:E100, LAMBDA(count, id, IF(REGEXTEST(id, "\d{4,}"), count+1, count)))Công thức trên kiểm tra mỗi ô để tìm ít nhất 4 chữ số liên tiếp bằng hàm REGEXTEST. Nếu tìm thấy, hàm sẽ tăng bộ đếm; nếu không, hàm sẽ giữ nguyên số đếm trước đó trong cột J. Kết quả là một cột hiển thị các ID hợp lệ tích lũy khi bạn di chuyển xuống danh sách.
SCAN cũng xử lý các phép toán REGEX nhiều bước trong một công thức duy nhất. Nếu bạn cần trích xuất, xác thực và chuyển đổi văn bản cùng một lúc, việc lồng hàm REGEX bên trong hàm SCAN sẽ thực hiện việc này mà không cần các cột hỗ trợ. Điều này đặc biệt hữu ích khi làm việc với các tập dữ liệu lớn, nơi việc thêm những cột bổ sung có thể làm chậm tiến độ.
Khi nào nên sử dụng các hàm này thay cho những công thức chuẩn?
REGEX và SCAN không phải là sự thay thế cho VLOOKUP hoặc IF, nhưng chúng là công cụ hữu ích khi các mẫu văn bản quan trọng hơn những kết quả khớp chính xác. Nếu bạn đang dọn dẹp dữ liệu đã nhập hoặc trích xuất các phần cụ thể từ văn bản phi cấu trúc, chúng sẽ giúp bạn tiết kiệm thời gian so với việc chỉnh sửa thủ công hoặc các hàm TEXT lồng nhau.
Cú pháp ban đầu có thể trông phức tạp, nhưng khi bạn đã thành thạo một vài mẫu, chẳng hạn như xác thực email, trích xuất số điện thoại và tách tên, bạn có thể sử dụng lại chúng trong nhiều dự án. Lý tưởng nhất là bạn nên bắt đầu với REGEXTEST để kiểm tra các mẫu, sau đó chuyển sang REGEXEXTRACT khi cần văn bản thực tế. Thêm SCAN khi bạn cần xử lý toàn bộ cột và cần chạy kết quả.






 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học