 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

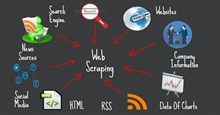
Web scraping là một trong số phương thức sưu tập dữ liệu tốt nhất và xây dựng dataset tùy biến. Dưới đây là chi tiết cách thực hiện.

Dataset chất lượng cao cực kỳ cần thiết trong kỷ nguyên quyết định dựa trên dữ liệu. Dù hiện có sẵn nhiều dataset công khai, đôi khi có thể bạn cần xây dựng dataset tùy biến đáp ứng nhu cầu cụ thể. Web scraping cho phép bạn trích xuất dữ liệu từ web. Sau đó, bạn có thể dùng dữ liệu này để tạo dataset tùy biến.
Tổng quan về phương pháp thu thập dữ liệu
Hiện có nhiều phương pháp thu thập dữ liệu khác nhau, bao gồm nhập dữ liệu theo cách thủ công, API, dataset công khai và web scraping. Mỗi phương pháp có ưu điểm và hạn chế riêng.
Nhập dữ liệu theo cách thủ công tốn thời gian và dễ sinh lỗi hơn, nhất là với bộ sưu tập dữ liệu quy mô lớn. Tuy nhiên, nó hữu ích với sưu tập dữ liệu quy mô nhỏ và khi không có sẵn dữ liệu qua các phương tiện khác.
API cho phép lập trình viên truy cập và trích xuất dữ liệu theo cách có cấu trúc. Chúng thường cung cấp thông tin được update thường xuyên hoặc ngay tại thời gian thực. Tuy nhiên, API truy cập có thể bị hạn chế, cần xác thực hoặc có hạn chế sử dụng.
Dataset công khai bao gồm nhiều chủ đề và lĩnh vực khác nhau. Chúng được thu thập trước, thường ở định dạng có cấu trúc, giúp người dùng dễ dàng truy cập. Nhờ đó, bạn tiết kiệm được thời gian và công sức đáng kể khi dữ liệu cần thiết phù hợp với dataset sẵn có. Tuy nhiên, không phải lúc nào chúng cũng đáp ứng nhu cầu của bạn hay được update.
Web scraping cung cấp một cách thu thập dữ liệu từ trang web, không cung cấp API hoặc có truy cập hạn chế. Nó cho phép tùy biến, mở rộng và khả năng thu thập dữ liệu từ nhiều nguồn. Tuy nhiên, nó đòi hỏi kỹ năng lập trình, kiến thức về cấu trúc HTML và tuân thủ nguyên tắc pháp lý & đạo đức.
Chọn Web Scraping để thu thập dữ liệu
Web scraping cho phép bạn trực tiếp trích xuất thông tin từ trang web, trao cho bạn quyền truy cập tới một loạt nguồn dữ liệu. Nó cũng cho bạn quyền kiểm soát dữ liệu trích xuất và cách cấu trúc nó. Điều này giúp điều chỉnh quy trình khai thác dữ liệu dễ dàng hơn, nhằm đáp ứng yêu cầu cụ thể và trích xuất thông tin bạn cần cho dự án
Xác định nguồn dữ liệu
Bước đầu tiên trong web scraping là xác định nguồn dữ liệu. Đây là web chứa dữ liệu bạn muốn khai thác. Khi chọn nguồn dữ liệu, đảm bảo bạn tuân thủ quy tắc dịch vụ của nguồn. Bài viết sẽ dùng IMDb (Internet Movie Database) làm dữ liệu nguồn.
Thiết lập môi trường
Thiết lập môi trường ảo. Sau đó chạy lệnh sau để cài các thư viện cần thiết.
pip install requests beautifulsoup4 pandasBạn sẽ dùng thư viện requests để tạo truy vấn HTTP. beautifulsoup4 để phân tích nội dung HTML và trích xuất dữ liệu từ trang web. Cuối cùng, bạn sẽ dùng pandas để thao tác và phân tích dữ liệu.
Viết tập lệnh Web Scraping
Nhập những thư viện được cài trong script để có thể dùng các hàm chúng cung cấp.
import requests
from bs4 import BeautifulSoup
import time
import pandas as pd
import reMô đun time và re là một phần của thư viện chuẩn Python. Vì thế, không yêu cầu cài đặt riêng.
time sẽ thêm trì hoãn cho quá trình khai thác, còn re sẽ xử lý những biểu thức thông thường.
Bạn sẽ dùng Beautiful Soup để khai thác dữ liệu trên web mục tiêu.
Tạo một hàm gửi truy vấn HTTP GET tới URL mục tiêu. Sau đó, nó sẽ trích xuất nội dung của phản hồi và tạo đối tượng BeautifulSoup từ nội dung HTML.
def get_soup(url, params=None, headers=None):
response = requests.get(url, params=params, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
return soupBước tiếp theo là trích xuất thông tin từ đối tượng BeautifulSoup. Để trích xuất thông tin, bạn cần hiểu cấu trúc web mục tiêu. Điều này liên quan tới việc kiểm tra mã code HTML của web, giúp nhận diện các phần tử và thuộc tính chứa dữ liệu bạn muốn trích xuất. Để kiểm tra trang web mục tiêu, mở link của nó trong trình duyệt web và điều hướng tới trang web chứa dữ liệu bạn muốn khai thác.
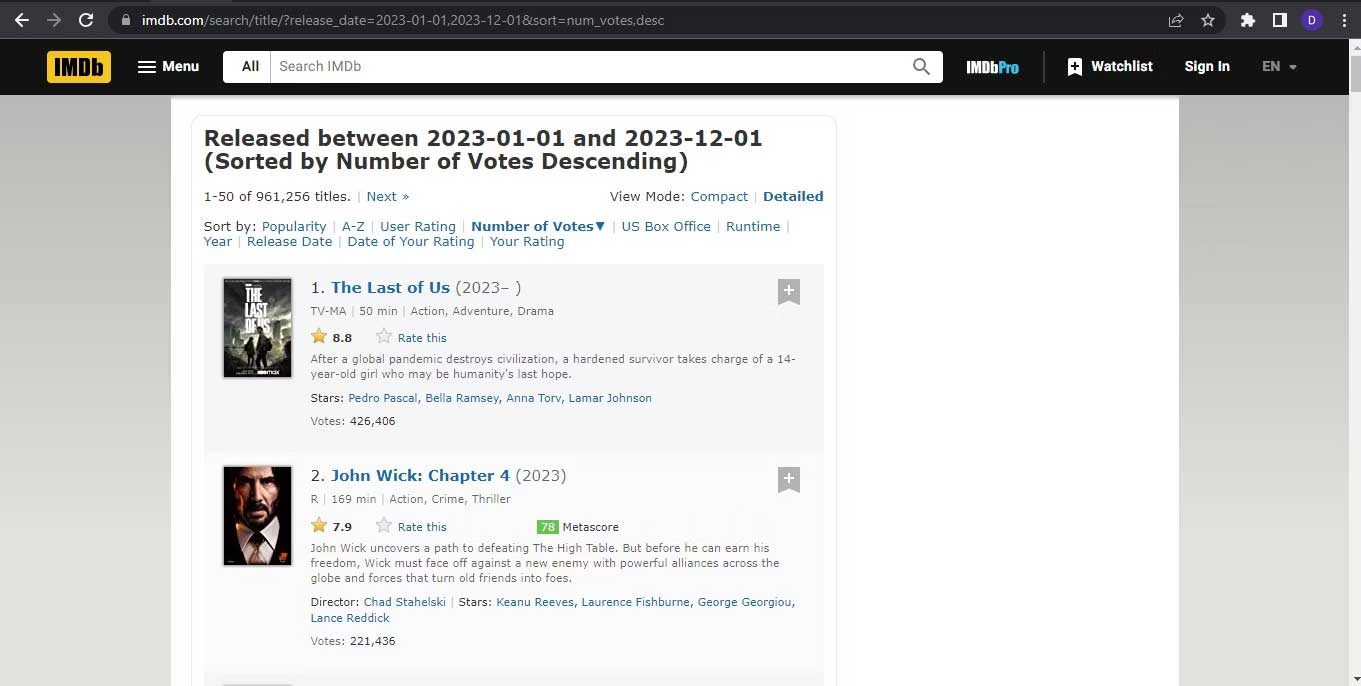
Click chuột phải vào trang web và chọn Inspect từ menu ngữ cảnh. Hành động này sẽ mở ra công cụ lập trình của trình duyệt.
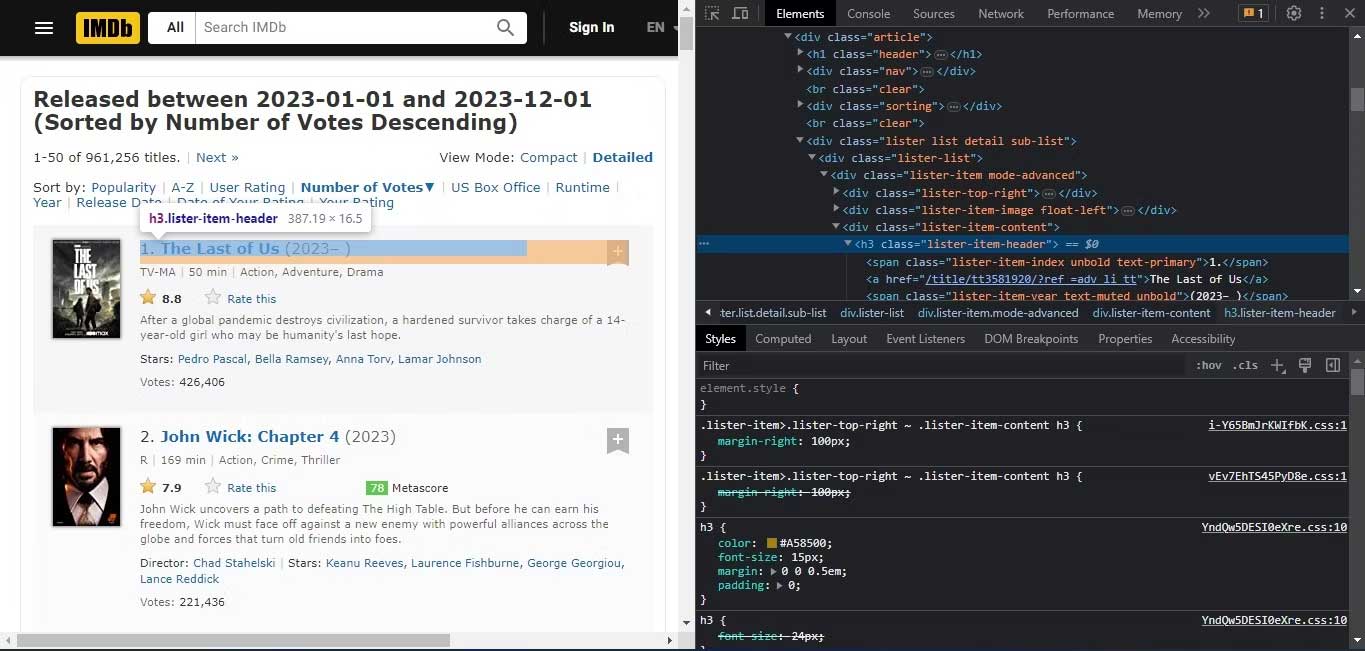
Trong code HTML của trang web, tìm phần tử chứa dữ liệu bạn muốn khai thác. Chú ý tới thẻ HTML, class và thuộc tính kết hợp với dữ liệu bạn cần. Bạn sẽ dùng chúng để tạo các bộ chọn để trích xuất dữ liệu bằng BeautifulSoup. Ở ảnh chụp màn hình kể trên, bạn có thể thấy tên bộ phim nằm trong class lister-item-header. Kiểm tra từng tính năng bạn muốn trích xuất.
Tạo một hàm trích xuất thông tin từ đối tượng BeautifulSoup. Trong trường hợp này, hàm tìm thấy tiêu đề, xếp hạng, mô tả, thể loại, ngày phát hành, đạo diễn và diễn viên của phim bằng thẻ HTML và thuộc tính class phù hợp.
def extract_movie_data(movie):
title = movie.find("h3", class_="lister-item-header").find("a").text
rating = movie.find("div", class_="ratings-imdb-rating").strong.text
description = movie.find("div", class_="lister-item-content").find_all("p")[1].text.strip()
genre_element = movie.find("span", class_="genre")
genre = genre_element.text.strip() if genre_element else None
release_date = movie.find("span", class_="lister-item-year text-muted unbold").text.strip()
director_stars = movie.find("p", class_="text-muted").find_all("a")
directors = [person.text for person in director_stars[:-1]]
stars = [person.text for person in director_stars[-1:]]
movie_data = {
"Title": title,
"Rating": rating,
"Description": description,
"Genre": genre,
"Release Date": release_date,
"Directors": directors,
"Stars": stars
}
return movie_dataCuối cùng, tạo hàm sẽ khai thác dữ liệu thực sự bằng hai hàm kể trên. Nó sẽ lấy năm và số phim tối đa mà bạn muốn khai thác.
def extract_movie_data(movie):
title = movie.find("h3", class_="lister-item-header").find("a").text
rating = movie.find("div", class_="ratings-imdb-rating").strong.text
description = movie.find("div", class_="lister-item-content").find_all("p")[1].text.strip()
genre_element = movie.find("span", class_="genre")
genre = genre_element.text.strip() if genre_element else None
release_date = movie.find("span", class_="lister-item-year text-muted unbold").text.strip()
director_stars = movie.find("p", class_="text-muted").find_all("a")
directors = [person.text for person in director_stars[:-1]]
stars = [person.text for person in director_stars[-1:]]
movie_data = {
"Title": title,
"Rating": rating,
"Description": description,
"Genre": genre,
"Release Date": release_date,
"Directors": directors,
"Stars": stars
}
return movie_dataSau đó gọi def scrape_imdb_movies để triển khai nhiệm vụ.
# Tìm 1000 bộ phim được phát hành trong năm 2023 (hoặc nhiều hơn nếu có)
movies = scrape_imdb_movies(2023, 1000)Giờ bạn đã có dữ liệu được khai thác:
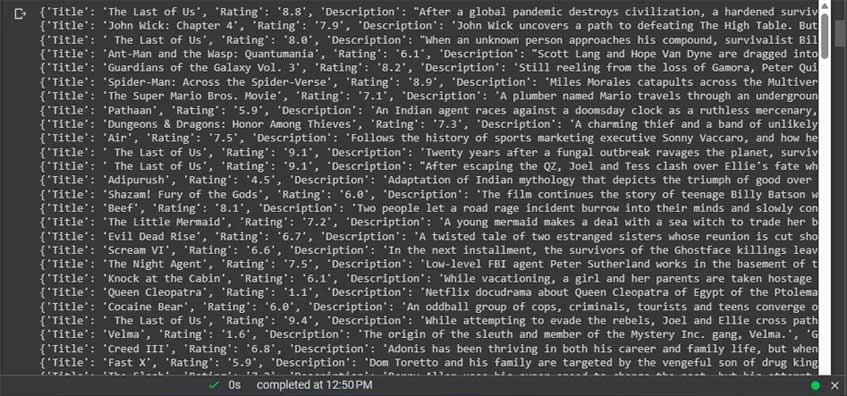
Bước tiếp theo là tạo dataset từ dữ liệu này.
Tạo dataset từ dữ liệu được khai thác
Tạo DataFrame bằng Pandas từ dữ liệu được khai thác.
df = pd.DataFrame(movies)Sau đó, tiến hành xử lý trước và làm sạch. Trong trường hợp này, loại bỏ hàng chứa dữ liệu bị thiếu. Sau đó, trích xuất năm từ ngày phát hành và chuyển đổi nó sang dạng số. Loại bỏ các cột không cần thiết. Chuyển đổi cột Rating sang dạng số. Cuối cùng, xóa những ký tự không phải chữ cái khỏi cột Title.
df = df.dropna()
df['Release Year'] = df['Release Date'].str.extract(r'(\d{4})')
df['Release Year'] = pd.to_numeric(df['Release Year'],
errors='coerce').astype('Int64')
df = df.drop(['Release Date'], axis=1)
df['Rating'] = pd.to_numeric(df['Rating'], errors='coerce')
df['Title'] = df['Title'].apply(lambda x: re.sub(r'\W+', ' ', x))Lưu dữ liệu vào một file để sử dụng sau trong dự án của bạn.
df.to_csv("imdb_movies_dataset.csv", index=False)Cuối cùng, in 5 hàng đầu tiên của dataset để có cửa sổ xem hình ảnh của nó.
df.head()Kết quả:
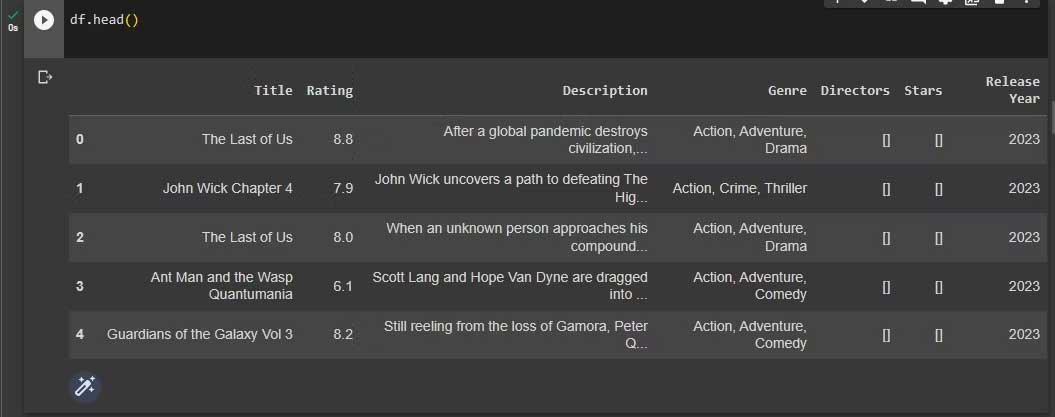
Giờ bạn đã có một dataset được lấy về bằng web scraping.
Beautiful Soup không phải thư viện Python duy nhất mà bạn có thể dùng để khai thác web. Bạn còn có nhiều lựa chọn khác với ưu điểm và hạn chế riêng. Hãy nghiên cứu chúng để tìm được lựa chọn phù hợp nhất với mình nhé!




 Lập trình
Lập trình
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học