 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Các nền tảng trí tuệ nhân tạo của DeepMind đã trở nên nổi tiếng trên khắp thế giới trong vài năm trở lại đây nhờ vào khả năng làm chủ tuyệt vời đối với các trò chơi phức tạp, cần “nhiều não” như cờ vua, shogi và Go. Qua thời gian, chúng dần “tiến hóa”, đánh bại các game thủ bằng da bằng thịt của chúng ta với những kỹ thuật học máy tiên tiến.
Năm 2016, DeepMind trình làng AlphaGo, một hệ thống AI có khả năng chơi game tuyệt đỉnh. Một năm sau, công ty tiếp tục cho ra mắt AlphaGo Zero. Đây là phiên bản kế nhiệm hoàn hảo của AlphaGo, sở hữu khả năng học chơi cờ vây chỉ thông qua việc quan sát các trận đấu của con người, sau đó làm chủ trò chơi bằng cách tự đấu với chính mình. Sau đó nữa là AlphaZero, một hệ thống AI thậm chí còn ưu việt hơn với khả năng chơi cùng lúc cả cờ vây, cờ vua và shogi chỉ với một thuật toán duy nhất.
Tuy nhiên, điểm chung của các thuật toán AI trên là chúng đều cần phải trải qua quá trình đào tạo chuyên sâu về gameplay cũng như các quy tắc trong game thì mới có thể làm chủ được một trò chơi nhất định. Đây là một quy trình phức tạp và tương đối mất thời gian.
Để giải quyết vấn đề, DeepMind vừa ra mắt một hệ thống AI mới cực kỳ siêu việt có tên MuZero. AI này có khả năng chơi thành thạo cờ vây, cờ vua, shogi và một bộ trò chơi Atari mà không cần phải được đào tạo trước về bộ quy tắc của các trò chơi trên. Nó sẽ tự học tất cả, và sau đó có thể chơi các trò chơi này tương đương hoặc thậm chí giỏi hơn bất kỳ thuật toán nào trước đây của DeepMind.

Tạo ra một thuật toán có thể thích ứng với mọi tình huống trong trò chơi mà không cần được đào tạo trước, đồng thời vẫn có thể tìm ra cách lập kế hoạch để làm chủ trò chơi đó thực sự là một thách thức lớn mà các nhà nghiên cứu AI đã tìm cách giải quyết trong một thời gian dài. DeepMind đã cố gắng hiện thực hóa điều này bằng cách sử dụng một phương pháp được gọi là “Lookahead Search”. Với kỹ thuật này, thuật toán AI sẽ xem xét các tình huống, trạng thái có thể xảy ra theo dự tính để lập kế hoạch hành động.
Để dễ hiểu, bạn hãy liên tưởng đến một trò chơi chiến lược như cờ vua. Trước khi đưa đến một quyết định hoặc một nước đi, bạn sẽ cần cân nhắc xem đối thủ sẽ phản ứng như thế nào và lên kế hoạch sao cho phù hợp. Tương tự, AI cũng sử dụng phương pháp Lookahead Search để cố gắng lên kế hoạch trước cho một số bước di chuyển. Sau đó chọn lọc và ưu tiên những nước đi có khả năng dẫn đến chiến thắng cao nhất.
Vấn đề với cách tiếp cận này là hầu hết các tình huống trong thế giới thực (và thậm chí một số trò chơi) không chứa đựng bộ quy tắc đơn giản để điều chỉnh cách thức chúng hoạt động. Vì vậy, các nhà nghiên cứu đã giải quyết vấn đề bằng cách để AI cố gắng mô hình hóa cách một trò chơi hoặc môi trường kịch bản cụ thể sẽ ảnh hưởng đến kết quả như thế nào. Sau đó, sử dụng kiến thức, thông tin thu được để lập kế hoạch. Hạn chế của phương pháp này là việc mô hình hóa mọi khía cạnh là gần như không thể.
Do vậy, thay vì mô hình hóa mọi thứ, MuZero sẽ chỉ cố gắng xem xét những yếu tố quan trọng để đưa ra quyết định, tương tự như con người. Chẳng hạn, khi nhìn ra ngoài cửa sổ và thấy những đám mây đen hình thành ở phía xa, đa số chúng ta sẽ bị cuốn vào dòng liên tưởng về những cơn mưa, giông bão, hay mình nên mặc như thế nào để không bị ướt nếu đi ra ngoài… Thay vì suy nghĩ về những vấn đề như hiện tượng ngưng tụ và áp suất không khí. Đó là một dạng tư duy chọn lọc theo bản năng. Cách MuZero “tư duy” cũng giống như vậy.
Khi phải đưa ra một quyết định, MuZero phải tính đến ba yếu tố khác nhau. Nó sẽ xem xét kết quả của quyết định trước đó, tình hình hiện tại, và cuối cùng là hướng hành động tốt nhất để thực hiện quyết định tiếp theo. Cách tiếp cận có vẻ đơn giản này khiến MuZero trở thành thuật toán hiệu quả nhất mà DeepMind từng tạo ra cho đến nay.
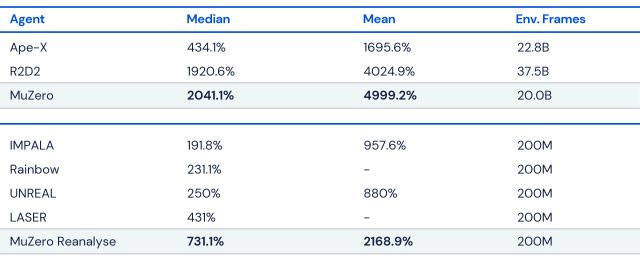
Trong các thử nghiệm nội bộ, kết quả cho thấy MuZero cho hiệu suất tương tự như AlphaZero ở cờ vua, cờ vây và shogi. Và tốt hơn tất cả các thuật toán đã ra mắt trước đó, bao gồm cả Agent57, ở trò chơi Atari. Ngoài ra, nếu càng cho MuZero nhiều thời gian để xem xét một hành động, thì thuật toán sẽ càng hoạt động hiệu quả hơn.
Khả năng học tập tự động hiệu quả của MuZero một ngày nào đó có thể giúp giải quyết các vấn đề phức tạp trong nhiều lĩnh vực “nóng” hiện nay, chẳng hạn như chế tạo người máy - nơi không có chỗ cho các quy tắc đơn giản.







 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học