 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Qwen3 là thế hệ mô hình ngôn ngữ lớn mới nhất của Alibaba. Với khả năng hỗ trợ hơn 100 ngôn ngữ và hiệu suất mạnh mẽ trên các tác vụ lý luận, viết code và dịch thuật, Qwen3 có thể sánh ngang với nhiều mô hình hàng đầu hiện nay, bao gồm DeepSeek-R1, o3-mini và Gemini 2.5.
Hướng dẫn này sẽ giải thích từng bước cách chạy Qwen3 cục bộ bằng Ollama. Hướng dẫn cũng sẽ xây dựng một ứng dụng nhẹ cục bộ bằng Qwen 3. Ứng dụng này sẽ cho phép bạn chuyển đổi giữa các chế độ lý luận của Qwen3 và dịch giữa nhiều ngôn ngữ khác nhau.
Mục lục bài viết
Tại sao nên chạy Qwen3 cục bộ?
Chạy Qwen3 cục bộ mang lại một số lợi ích chính:
- Quyền riêng tư: Dữ liệu không bao giờ rời khỏi máy của bạn.
- Độ trễ: Suy luận cục bộ nhanh hơn mà không cần API khứ hồi.
- Tiết kiệm chi phí: Không tính phí token hoặc hóa đơn đám mây.
- Kiểm soát: Bạn có thể điều chỉnh prompt, chọn mô hình và cấu hình chế độ suy nghĩ.
- Truy cập ngoại tuyến: Bạn có thể làm việc mà không cần kết nối Internet sau khi tải xuống mô hình.
Qwen3 được tối ưu hóa cho cả lý luận sâu (chế độ suy nghĩ) và phản hồi nhanh (chế độ không suy nghĩ) và hỗ trợ hơn 100 ngôn ngữ.
Thiết lập Qwen3 cục bộ bằng Ollama
Ollama là một công cụ cho phép bạn chạy các mô hình ngôn ngữ như Llama hoặc Qwen cục bộ trên máy tính của mình bằng giao diện dòng lệnh đơn giản.
Bước 1: Cài đặt Ollama
Tải xuống Ollama cho macOS, Windows hoặc Linux từ: https://ollama.com/download.
Thực hiện theo hướng dẫn cài đặt và sau khi cài đặt, hãy xác minh bằng cách chạy lệnh này trong terminal:
ollama --versionBước 2: Tải xuống và chạy Qwen3
Ollama cung cấp nhiều mô hình Qwen3 được thiết kế để phù hợp với nhiều cấu hình phần cứng khác nhau, từ laptop nhẹ đến máy chủ cao cấp.
ollama run qwen3Chạy lệnh trên sẽ khởi chạy mô hình Qwen3 mặc định trong Ollama, hiện tại mặc định là qwen3:8b. Nếu đang làm việc với tài nguyên hạn chế hoặc muốn thời gian khởi động nhanh hơn, bạn có thể chạy rõ ràng các biến thể nhỏ hơn như mô hình 4B:
ollama run qwen3:4bQwen3 hiện có sẵn ở một số biến thể, bắt đầu từ mô hình tham số nhỏ nhất 0,6b (523MB) đến mô hình tham số lớn nhất 235b (142GB). Các biến thể nhỏ hơn này cung cấp hiệu suất ấn tượng cho lý luận, biên dịch và tạo code, đặc biệt là khi sử dụng ở chế độ suy nghĩ.
Các mô hình MoE (30b-a3b, 235b-a22b) đặc biệt thú vị vì chúng chỉ kích hoạt một tập hợp con những chuyên gia cho mỗi bước suy luận, cho phép đếm tổng tham số lớn trong khi vẫn giữ chi phí runtime hiệu quả.
Nhìn chung, hãy sử dụng mô hình lớn nhất mà phần cứng của bạn có thể xử lý và quay lại các mô hình 8B hoặc 4B để thực hiện những thử nghiệm cục bộ phản hồi trên máy của người tiêu dùng.
Sau đây là bản tóm tắt nhanh về tất cả các mô hình Qwen3 mà bạn có thể chạy:
|
Mô hình |
Lệnh Ollama |
Phù hợp nhất cho |
|
Qwen3-0.6B |
|
Các tác vụ nhẹ, ứng dụng di động và thiết bị biên |
|
Qwen3-1.7B |
|
Chatbot, trợ lý và các ứng dụng có độ trễ thấp |
|
Qwen3-4B |
|
Nhiệm vụ mục đích chung với hiệu suất cân bằng và sử dụng tài nguyên |
|
Qwen3-8B |
|
Hỗ trợ đa ngôn ngữ và khả năng lý luận vừa phải |
|
Qwen3-14B |
|
Lý luận nâng cao, sáng tạo nội dung và giải quyết vấn đề phức tạp |
|
Qwen3-32B |
|
Các nhiệm vụ cao cấp đòi hỏi khả năng suy luận mạnh mẽ và xử lý ngữ cảnh mở rộng |
|
Qwen3-30B-A3B (MoE) |
|
Hiệu suất hiệu quả với 3 tham số hoạt động, phù hợp cho các tác vụ mã hóa |
|
Qwen3-235B-A22B (MoE) |
|
Các ứng dụng quy mô lớn, lý luận sâu sắc và những giải pháp cấp doanh nghiệp |
Bước 3: Chạy Qwen3 ở chế độ nền (tùy chọn)
Để phục vụ mô hình thông qua API, hãy chạy lệnh này trong Terminal:
ollama serveĐiều này sẽ làm cho mô hình có sẵn để tích hợp với các ứng dụng khác tại http://localhost:11434.
Sử dụng Qwen3 cục bộ
Phần này sẽ hướng dẫn bạn một số cách có thể sử dụng Qwen3 cục bộ, từ tương tác CLI cơ bản đến tích hợp mô hình với Python.
Tùy chọn 1: Chạy suy luận thông qua CLI
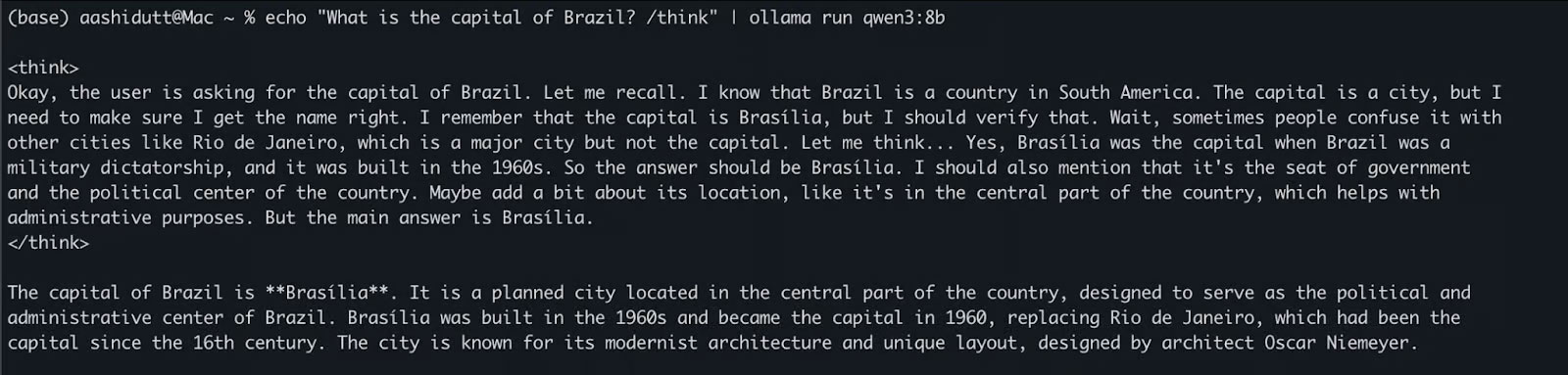
Sau khi mô hình được tải xuống, bạn có thể tương tác trực tiếp với Qwen3 trong Terminal. Chạy lệnh sau trong Terminal:
echo "What is the capital of Brazil? /think" | ollama run qwen3:8bĐiều này hữu ích cho các bài kiểm tra nhanh hoặc tương tác nhẹ mà không cần viết bất kỳ code nào. Tag /think ở cuối prompt hướng dẫn mô hình tham gia vào lý luận sâu hơn, từng bước. Bạn có thể thay thế điều này bằng /no_think để có phản hồi nhanh, nông hơn hoặc bỏ qua hoàn toàn để sử dụng chế độ suy luận mặc định của mô hình.
Tùy chọn 2: Truy cập Qwen3 qua API
Khi ollama serve chạy ở chế độ nền, bạn có thể tương tác với Qwen3 theo chương trình bằng API HTTP, hoàn hảo cho tích hợp backend, tự động hóa hoặc thử nghiệm REST client.
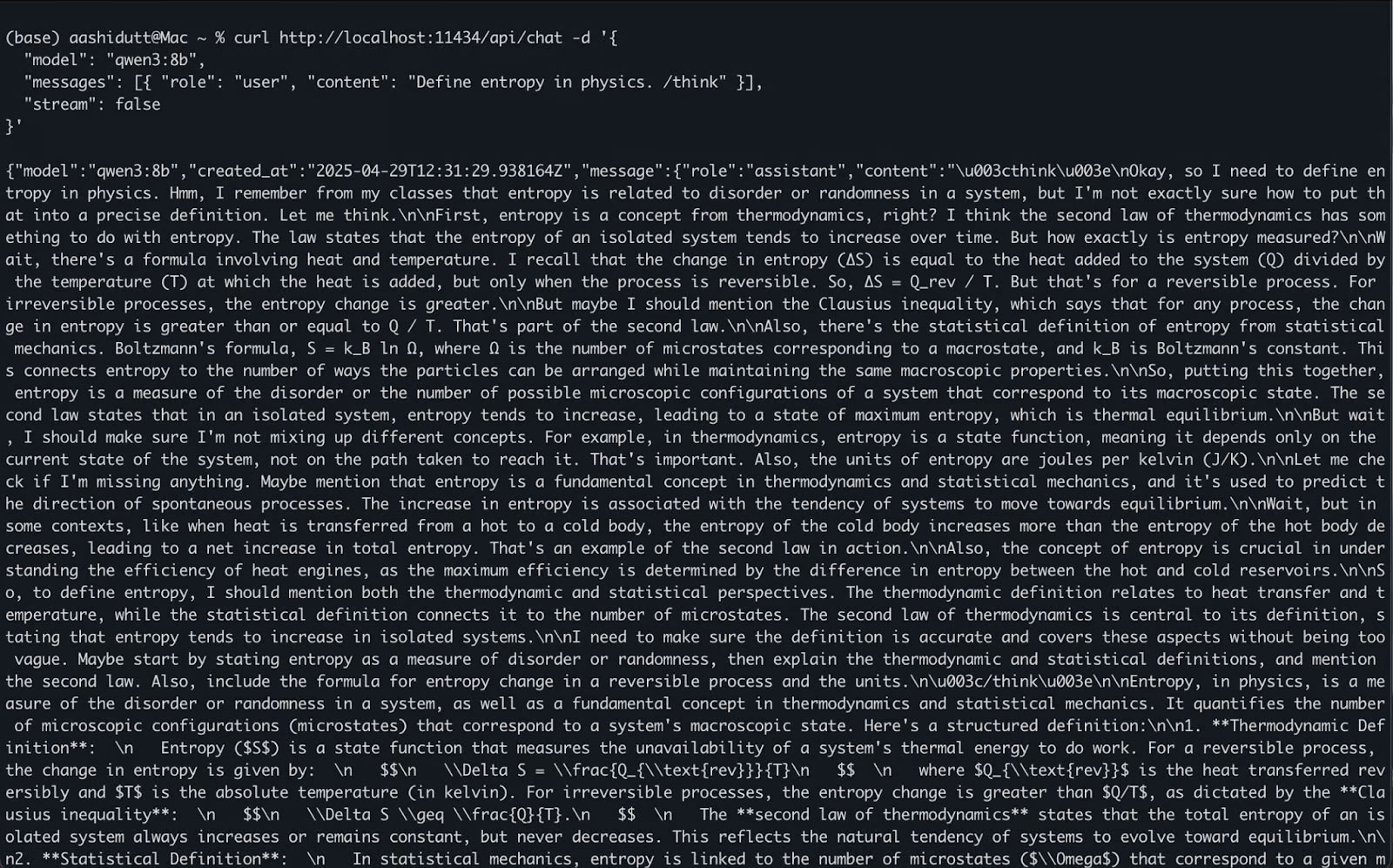
curl http://localhost:11434/api/chat -d '{
"model": "qwen3:8b",
"messages": [{ "role": "user", "content": "Define entropy in physics. /think" }],
"stream": false
}'Đây là cách thức hoạt động:
- curl thực hiện yêu cầu POST (cách chúng ta gọi API) tới máy chủ Ollama cục bộ đang chạy tại localhost:11434.
- Payload là một đối tượng JSON có:
- "model": Chỉ định mô hình sẽ sử dụng (ở đây là: qwen3:8b).
- "messages": Danh sách các tin nhắn trò chuyện có chứa vai trò và nội dung.
- "stream": false: Đảm bảo phản hồi được trả về cùng một lúc, không phải từng token.
Tùy chọn 3: Truy cập Qwen3 qua Python
Nếu bạn đang làm việc trong môi trường Python (như Jupyter, VSCode hoặc script), cách dễ nhất để tương tác với Qwen3 là thông qua Ollama Python SDK. Bắt đầu bằng cách cài đặt ollama:
pip install ollamaSau đó, chạy mô hình Qwen3 của bạn bằng script này (ví dụ đang sử dụng qwen3:8b bên dưới):
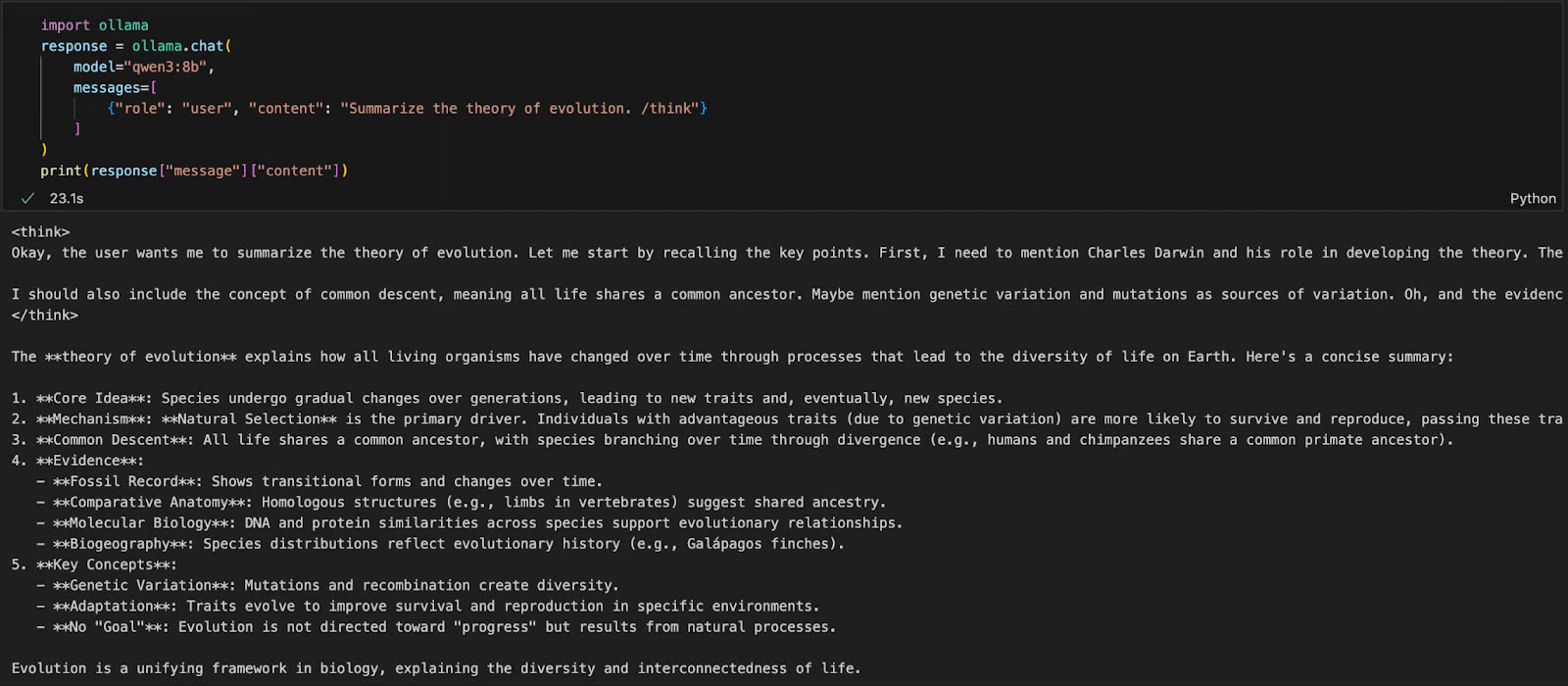
import ollama
response = ollama.chat(
model="qwen3:8b",
messages=[
{"role": "user", "content": "Summarize the theory of evolution. /think"}
]
)
print(response["message"]["content"])Trong code trên:
- ollama.chat(...) gửi yêu cầu theo kiểu trò chuyện đến máy chủ Ollama cục bộ.
- Bạn chỉ định mô hình (qwen3:8b) và danh sách các tin nhắn theo định dạng tương tự như API của OpenAI.
- Tag /think yêu cầu mô hình lý giải từng bước.
- Cuối cùng, phản hồi được trả về dưới dạng từ điển và bạn có thể truy cập câu trả lời của mô hình bằng cách sử dụng ["message"]["content"].
Cách tiếp cận này lý tưởng cho thử nghiệm cục bộ, tạo mẫu hoặc xây dựng các ứng dụng được LLM hỗ trợ mà không cần dựa vào API đám mây.
Xây dựng ứng dụng suy luận cục bộ với Qwen3
Qwen3 hỗ trợ hành vi Hybrid reasoning sử dụng tag /think (suy luận sâu) và tag /no_think (phản hồi nhanh). Trong phần này, chúng ta sẽ sử dụng Gradio để tạo một ứng dụng web cục bộ tương tác với hai tab riêng biệt:
- Giao diện suy luận để chuyển đổi giữa các chế độ suy luận.
- Giao diện đa ngôn ngữ để dịch hoặc xử lý văn bản bằng nhiều ngôn ngữ khác nhau.
Bước 1: Bản demo Hybrid reasoning (Tư Duy Kép)
Trong bước này, chúng ta sẽ xây dựng tab Hybrid reasoning với tag /think và tag /no_think.
import gradio as gr
import subprocess
def reasoning_qwen3(prompt, mode):
prompt_with_mode = f"{prompt} /{mode}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt_with_mode.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
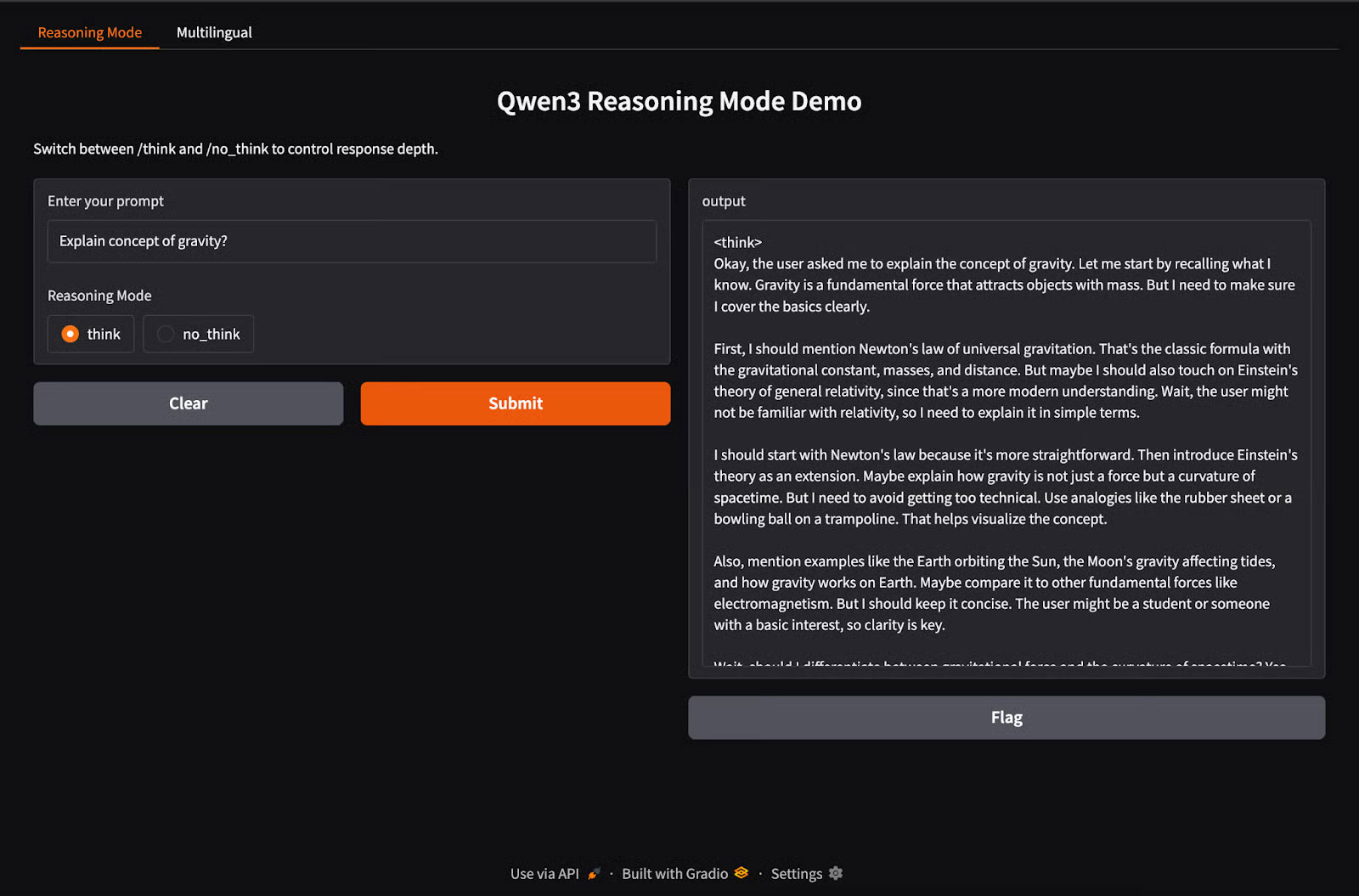
reasoning_ui = gr.Interface(
fn=reasoning_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Radio(["think", "no_think"], label="Reasoning Mode", value="think")
],
outputs="text",
title="Qwen3 Reasoning Mode Demo",
description="Switch between /think and /no_think to control response depth."
)Trong đoạn code trên:
- Hàm reasoning_qwen3() nhận một prompt người dùng và một chế độ suy luận ("think" hoặc "no_think").
- Hàm này thêm chế độ đã chọn làm hậu tố cho prompt.
- Sau đó, phương thức subprocess.run() chạy lệnh ollama run qwen3:8b, đưa prompt vào làm đầu vào chuẩn.
- Cuối cùng, đầu ra (phản hồi từ Qwen3) được ghi lại và trả về dưới dạng một chuỗi đã giải mã.
Sau khi hàm tạo đầu ra được định nghĩa, hàm gr.Interface() sẽ gói nó vào một giao diện người dùng web tương tác bằng cách chỉ định các thành phần đầu vào - một Textbox cho prompt và một nút Radio để chọn chế độ suy luận - và ánh xạ chúng với những đầu vào của hàm.
Bước 2: Bản demo ứng dụng đa ngôn ngữ
Bây giờ, hãy thiết lập tab ứng dụng đa ngôn ngữ.
import gradio as gr
import subprocess
def multilingual_qwen3(prompt, lang):
if lang != "English":
prompt = f"Translate to {lang}: {prompt}"
result = subprocess.run(
["ollama", "run", "qwen3:8b"],
input=prompt.encode(),
stdout=subprocess.PIPE
)
return result.stdout.decode()
multilingual_ui = gr.Interface(
fn=multilingual_qwen3,
inputs=[
gr.Textbox(label="Enter your prompt"),
gr.Dropdown(["English", "French", "Hindi", "Chinese"], label="Target Language", value="English")
],
outputs="text",
title="Qwen3 Multilingual Translator",
description="Use Qwen3 locally to translate prompts to different languages."
)Tương tự như bước trước, code này hoạt động như sau:
- Hàm multilingual_qwen3() nhận một prompt và một ngôn ngữ đích.
- Nếu ngôn ngữ đích không phải là tiếng Anh, nó sẽ thêm lệnh "Translate to {lang}:" để hướng dẫn mô hình.
- Một lần nữa, mô hình chạy cục bộ thông qua tiến trình con sử dụng Ollama.
- Kết quả được trả về dưới dạng plain text.
Bước 3: Khởi chạy cả hai tab trong Gradio
Hãy cùng gộp cả hai tab lại với nhau trong một ứng dụng Gradio.
demo = gr.TabbedInterface(
[reasoning_ui, multilingual_ui],
tab_names=["Reasoning Mode", "Multilingual"]
)
demo.launch(debug = True)Sau đây là những gì chúng ta đang làm trong đoạn code trên:
- Hàm gr.TabbedInterface() tạo một giao diện người dùng với hai tab:
- Một tab để kiểm soát độ sâu suy luận.
- Một tab để dịch prompt đa ngôn ngữ.
- Hàm demo.launch(debug=True) chạy ứng dụng cục bộ và mở ứng dụng trong trình duyệt với chế độ gỡ lỗi được bật.
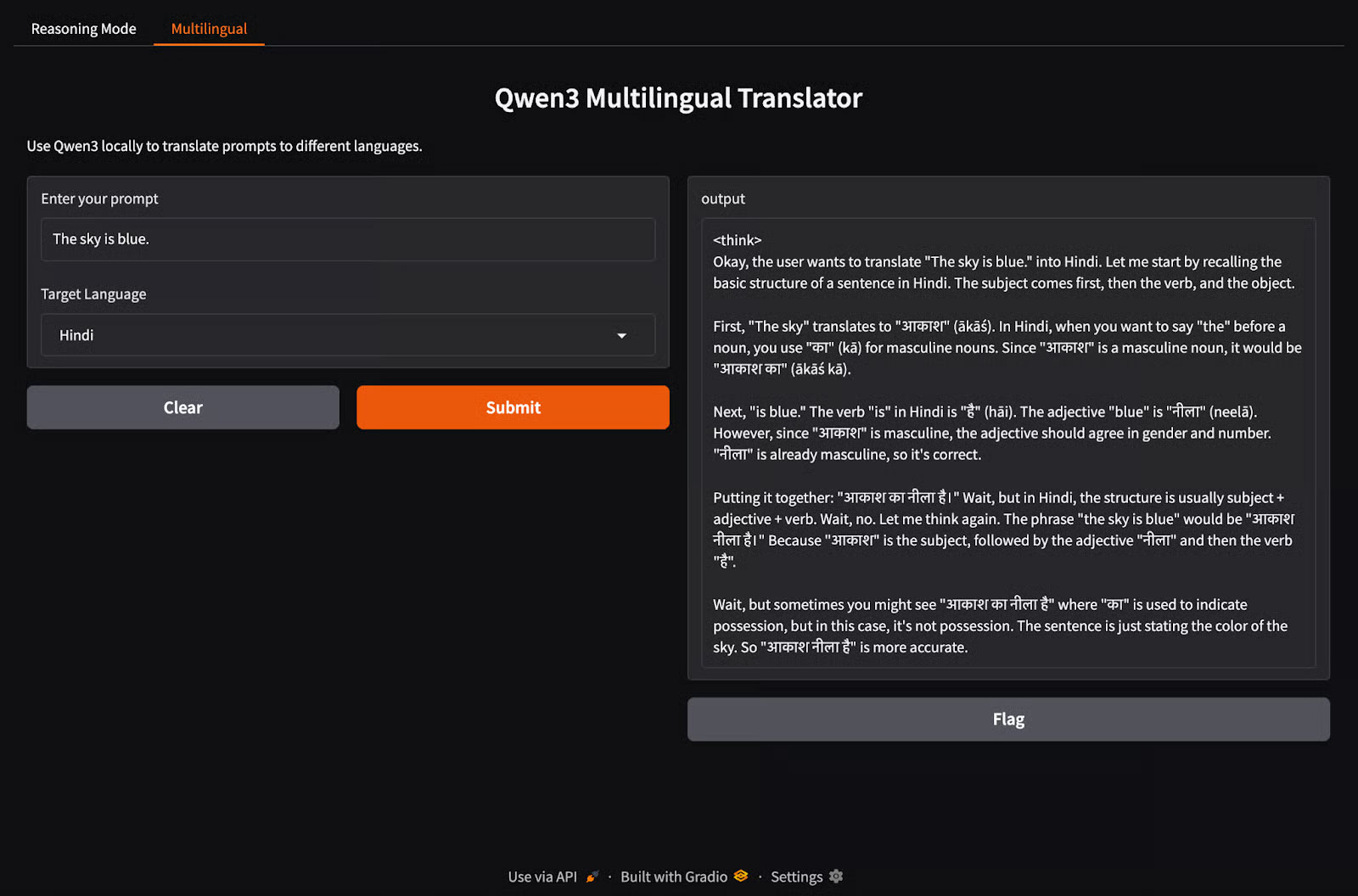
Qwen3 mang đến khả năng suy luận nâng cao, giải mã nhanh và hỗ trợ đa ngôn ngữ cho máy cục bộ bằng Ollama.
Với thiết lập tối thiểu, bạn có thể:
- Chạy suy luận LLM cục bộ mà không phụ thuộc vào đám mây
- Chuyển đổi giữa các phản hồi nhanh và chu đáo
- Sử dụng API hoặc Python để xây dựng các ứng dụng thông minh









 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học