 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Google vừa giới thiệu Gemini 2.5, mà công ty gọi là "mô hình AI thông minh nhất". Phiên bản đầu tiên của mô hình là Gemini 2.5 Pro, đạt được điểm benchmark ấn tượng trong nhiều bài kiểm tra.
Google tuyên bố rằng Gemini 2.5 vượt trội hơn so với mô hình tốt nhất từ OpenAI, DeepSeek và những gã khổng lồ công nghệ AI khác
Gemini 2.5 Pro hiện có sẵn thông qua Google AI Studio và trong ứng dụng Gemini nếu bạn là người dùng Gemini Advanced. Gemini 2.5 Pro cũng sẽ có sẵn thông qua Vertex AI trong tương lai gần.
Hiện tại, Google chưa chia sẻ giá của Gemini 2.5 Pro hoặc các mô hình Gemini 2.5 khác.
Tất cả các mô hình sử dụng Gemini 2.5 đều là "mô hình suy nghĩ", nghĩa là chúng có thể xử lý quá trình suy nghĩ trước khi tạo ra phản hồi. Các mô hình "lý luận" này là bước tiến lớn tiếp theo trong không gian AI vì chúng tạo ra những phản hồi phức tạp hơn và thường chính xác hơn.
"Bây giờ, với Gemini 2.5, chúng tôi đã đạt được một cấp độ hiệu suất mới bằng cách kết hợp một mô hình cơ sở được cải thiện đáng kể với quá trình đào tạo sau được cải thiện", Google cho biết.
"Trong tương lai, chúng tôi sẽ xây dựng những khả năng suy nghĩ này trực tiếp vào tất cả các mô hình của mình để chúng có thể xử lý những vấn đề phức tạp hơn và hỗ trợ các agent có khả năng nhận thức ngữ cảnh tốt hơn nữa".
Gemini 2.5 so với các mô hình OpenAI ra sao?
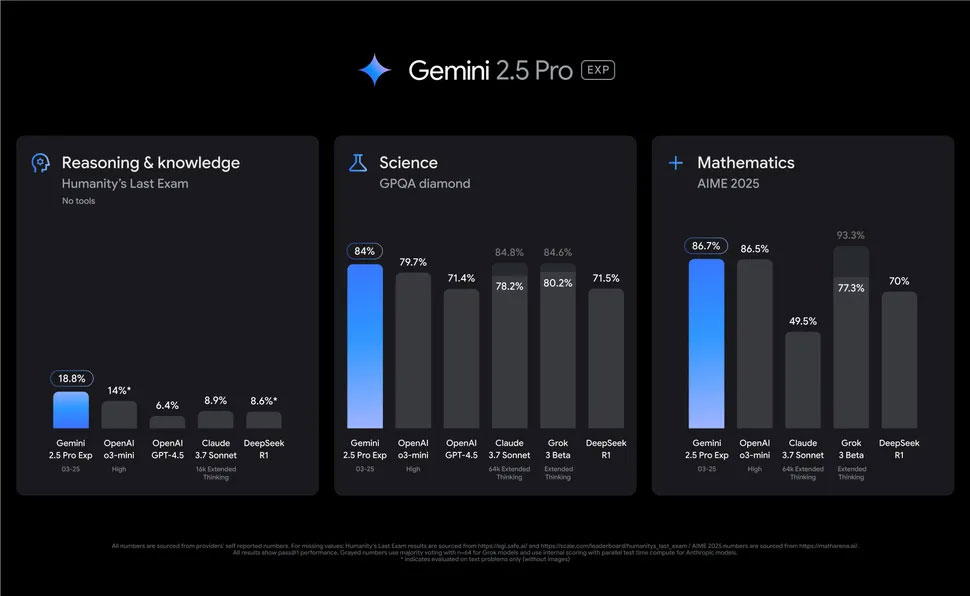
Các mô hình Gemini 2.5 Pro của Google vượt trội hơn những mô hình hàng đầu trước đây từ OpenAI và DeepSeek.
Điểm benchmark cho Gemini 2.5 do Google chia sẻ khá ấn tượng. Gemini 2.5 Pro Experimental đạt 18,5% trong Last Exam của Humanity.
Điểm số đó có nghĩa là, ít nhất là cho đến hiện tại, Gemini 2.5 Pro Experimental là mô hình tốt nhất theo số liệu đó. Điểm số của nó vượt qua OpenAI 03-mini (14%) và DeepSeek R1 (8,6%).
Bài kiểm tra cụ thể đó được coi là khó, mặc dù nó không phải là cách duy nhất để đo lường hiệu quả của một mô hình AI.
Google cũng nhấn mạnh khả năng lập trình của Gemini 2.5 Pro và các chuẩn mực của mô hình về toán học và khoa học. Gemini 2.5 Pro hiện đang dẫn đầu về chuẩn mực toán học và khoa học khi được đo lường thông qua GPQA và AIME 2025.
Có thể lập trình bằng Gemini 2.5 không?
Lập trình là trọng tâm chính của Gemini 2.5. Google tuyên bố "một bước nhảy vọt lớn so với 2.0" và hé lộ nhiều cải tiến hơn nữa đang được triển khai.
Mô hình mới của Google có thể tạo ứng dụng web và ứng dụng agentic code. Bản demo từ Google cho thấy Gemini 2.5 Pro đang được sử dụng để tạo game từ một dấu nhắc dòng duy nhất.
4 lý do tại sao Gemini 2.5 Pro của Google lại quan trọng đối với AI doanh nghiệp
Dưới đây là 4 điểm chính cần ghi nhớ đối với các nhóm doanh nghiệp khi đánh giá Gemini 2.5 Pro.
1. Lý luận có cấu trúc, minh bạch – một chuẩn mực mới cho sự rõ ràng của chuỗi suy nghĩ
Điểm khiến Gemini 2.5 Pro trở nên khác biệt không chỉ là trí thông minh của nó – mà còn là cách trí thông minh đó thể hiện rõ ràng công việc của nó. Phương pháp đào tạo từng bước của Google tạo ra một chuỗi suy nghĩ có cấu trúc (CoT) không giống như sự lan man hay phỏng đoán, giống như những gì chúng ta đã thấy từ các mô hình như DeepSeek. Các CoT này không bị cắt ngắn thành những bản tóm tắt hời hợt như các mô hình của OpenAI. Mô hình Gemini mới trình bày các ý tưởng theo những bước được đánh số, với các dấu đầu dòng phụ và logic nội bộ cực kỳ mạch lạc và minh bạch.
Về mặt thực tế, đây là một bước đột phá về độ tin cậy và khả năng điều hướng. Người dùng doanh nghiệp đánh giá đầu ra cho các nhiệm vụ quan trọng – như xem xét những tác động của chính sách, logic mã hóa hoặc tóm tắt nghiên cứu phức tạp – giờ đây có thể thấy cách mô hình đưa ra câu trả lời. Điều đó có nghĩa là họ có thể xác thực, sửa hoặc chuyển hướng câu trả lời một cách tự tin hơn. Đây là một bước tiến lớn từ cảm giác "hộp đen" vẫn còn tồn tại trong nhiều đầu ra của mô hình ngôn ngữ lớn (LLM).
Để biết hướng dẫn sâu hơn về cách thức hoạt động của mô hình này, hãy xem video phân tích nơi Gemini 2.5 Pro được thử nghiệm trực tiếp. Một ví dụ đã thảo luận: Khi được hỏi về những hạn chế của các mô hình ngôn ngữ lớn, Gemini 2.5 Pro đã thể hiện nhận thức đáng chú ý. Nó đã nêu ra những điểm yếu phổ biến và phân loại chúng thành các lĩnh vực như "trực giác vật lý", "tổng hợp khái niệm mới", "lập kế hoạch dài hạn" và "sắc thái đạo đức", cung cấp một framework giúp người dùng hiểu được mô hình biết những gì và cách tiếp cận vấn đề.
Các nhóm kỹ thuật doanh nghiệp có thể tận dụng khả năng này để:
- Gỡ lỗi chuỗi lý luận phức tạp trong các ứng dụng quan trọng
- Hiểu rõ hơn về các hạn chế của mô hình trong những domain cụ thể
- Cung cấp quyết định hỗ trợ AI minh bạch hơn cho các bên liên quan
- Cải thiện tư duy phản biện của chính họ bằng cách nghiên cứu cách tiếp cận của mô hình
Một hạn chế đáng lưu ý là mặc dù lý luận có cấu trúc này có sẵn trong ứng dụng Gemini và Google AI Studio, nhưng hiện tại vẫn chưa thể truy cập được qua API - một thiếu sót đối với các nhà phát triển muốn tích hợp khả năng này vào những ứng dụng doanh nghiệp.
2. Một ứng cử viên thực sự cho công nghệ tiên tiến – không chỉ trên lý thuyết
Mô hình hiện đang đứng đầu bảng xếp hạng Chatbot Arena với biên độ đáng kể – hơn 35 điểm Elo so với mô hình tốt nhất tiếp theo, đáng chú ý là bản cập nhật OpenAI 4o đã ra mắt vào ngày sau khi Gemini 2.5 Pro ra mắt. Và trong khi sự thống trị chuẩn mực thường là thoáng qua (vì các mô hình mới ra mắt hàng tuần), Gemini 2.5 Pro thực sự mang lại cảm giác khác biệt.
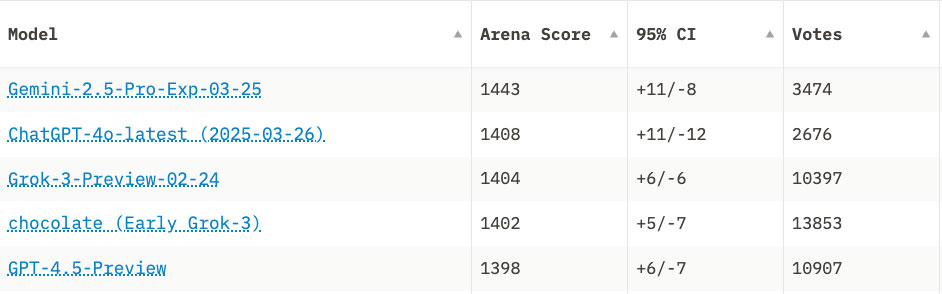
Nó nổi trội trong các nhiệm vụ khen thưởng cho lý luận sâu sắc: Mã hóa, giải quyết vấn đề sắc thái, tổng hợp trên những tài liệu và thậm chí là lập kế hoạch trừu tượng. Trong thử nghiệm nội bộ, nó hoạt động đặc biệt tốt trên các benchmark khó vượt qua trước đây như "Humanity’s Last Exam", một điểm chuẩn được ưa chuộng để phát hiện điểm yếu của LLM trong các lĩnh vực trừu tượng và sắc thái.
Các nhóm doanh nghiệp có thể không quan tâm mô hình nào giành chiến thắng trong bảng xếp hạng học thuật nào. Nhưng họ sẽ quan tâm rằng mô hình này có thể suy nghĩ - và cho bạn thấy cách nó suy nghĩ. Bài kiểm tra rung cảm rất quan trọng.
Như kỹ sư AI đáng kính Nathan Lambert đã lưu ý, "Google lại có những mô hình tốt nhất, vì họ đáng lẽ phải bắt đầu toàn bộ quá trình AI nở rộ này. Sai lầm nghiêm trọng đã được sửa chữa". Người dùng doanh nghiệp nên xem đây không chỉ là Google bắt kịp các đối thủ cạnh tranh mà còn có khả năng vượt qua họ về những khả năng quan trọng đối với các ứng dụng kinh doanh.
3. Cuối cùng, game mã hóa của Google rất mạnh
Theo truyền thống, Google đã tụt hậu so với OpenAI và Anthropic về hỗ trợ mã hóa tập trung vào nhà phát triển. Gemini 2.5 Pro đã thay đổi điều đó.
Trong các thử nghiệm thực hành, nó đã thể hiện khả năng mạnh mẽ trong một lần thử đối với những thách thức mã hóa, bao gồm xây dựng một game Tetris hoạt động chạy ngay lần thử đầu tiên khi xuất sang Replit - không cần gỡ lỗi. Đáng chú ý hơn nữa, nó đã lý giải cấu trúc code một cách rõ ràng, gắn nhãn các biến và những bước một cách chu đáo và trình bày cách tiếp cận của mình trước khi viết một dòng code.
Mô hình này cạnh tranh với Claude 3.7 Sonnet của Anthropic, được coi là công cụ dẫn đầu trong việc tạo code và là lý do chính cho sự thành công của Anthropic trong doanh nghiệp. Nhưng Gemini 2.5 cung cấp một lợi thế quan trọng: Cửa sổ ngữ cảnh token khổng lồ lên tới 1 triệu. Claude 3.7 Sonnet hiện chỉ mới cung cấp 500.000 token.
Cửa sổ ngữ cảnh lớn này mở ra những khả năng mới cho việc lập luận trên toàn bộ cơ sở code, đọc tài liệu trực tuyến và làm việc trên nhiều file phụ thuộc lẫn nhau. Kinh nghiệm của kỹ sư phần mềm Simon Willison đã chứng mình cho lợi thế này.
Khi sử dụng Gemini 2.5 Pro để triển khai một tính năng mới trên cơ sở code của mình, mô hình đã xác định những thay đổi cần thiết trên 18 file khác nhau và hoàn thành toàn bộ dự án trong khoảng 45 phút, trung bình chưa đến 3 phút cho mỗi file đã sửa đổi. Đây là một công cụ nghiêm túc dành cho các doanh nghiệp đang thử nghiệm với những agent framework hoặc môi trường phát triển được hỗ trợ bởi AI.
4. Tích hợp đa phương thức với hành vi giống như agent
Trong khi một số mô hình như 4o mới nhất của OpenAI có thể cho thấy sự hào nhoáng hơn với việc tạo hình ảnh bắt mắt, Gemini 2.5 Pro cho cảm giác như đang âm thầm định nghĩa lại hình ảnh của lý luận đa phương thức có cơ sở.
Trong một ví dụ, thử nghiệm thực hành của Ben Dickson cho VentureBeat đã chứng minh khả năng của mô hình trong việc trích xuất thông tin chính từ một bài viết kỹ thuật về thuật toán tìm kiếm và tạo sơ đồ luồng SVG tương ứng - sau đó cải thiện sơ đồ luồng đó khi hiển thị phiên bản đã kết xuất có lỗi trực quan. Mức độ lý luận đa phương thức này cho phép tạo ra các quy trình làm việc mới mà trước đây không thể thực hiện được với những mô hình chỉ có văn bản.
Trong một ví dụ khác, nhà phát triển Sam Witteveen đã upload lên một ảnh chụp màn hình đơn giản về bản đồ Las Vegas và hỏi những sự kiện Google nào đang diễn ra gần đó vào ngày 9 tháng 4. Mô hình đã xác định vị trí, suy ra ý định của người dùng, tìm kiếm trực tuyến và trả về thông tin chi tiết chính xác về Google Cloud Next, bao gồm ngày tháng, vị trí và trích dẫn. Tất cả những điều này được thực hiện mà không cần agent framework tùy chỉnh, chỉ có mô hình cốt lõi và tìm kiếm tích hợp.
Trên thực tế, mô hình lý luận về đầu vào đa phương thức này ngoài việc chỉ nhìn vào nó. Nó gợi ý về quy trình làm việc của doanh nghiệp có thể trông như thế nào trong 6 tháng: Upload lên tài liệu, sơ đồ và bảng thông tin, để mô hình thực hiện tổng hợp, lập kế hoạch hoặc hành động có ý nghĩa dựa trên nội dung.






 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học