 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Google Research vừa công bố một bước tiến quan trọng trong lĩnh vực học máy: một kỹ thuật mới mang tên Nested Learning, được thiết kế để giải quyết một trong những “tử huyệt” lâu nay của AI — hiện tượng “catastrophic forgetting” (tạm dịch: “quên lãng thảm họa”) trong quá trình học liên tục.
Hiểu đơn giản, “catastrophic forgetting” xảy ra khi một mô hình AI được huấn luyện thêm kiến thức hoặc kỹ năng mới, nhưng trong quá trình đó vô tình quên đi những gì nó đã biết trước đó. Điều này khiến mô hình trở nên “thiếu ổn định”, giống như học sinh học bài mới mà quên sạch bài cũ.
Lấy cảm hứng từ não người
Theo nhóm nghiên cứu của Google, Nested Learning được phát triển dựa trên cơ chế hoạt động của não người, cụ thể là tính dẻo thần kinh (neuroplasticity) — khả năng của não bộ thay đổi và thích nghi khi tiếp nhận thông tin mới mà không xóa đi ký ức cũ.
Google mô tả kỹ thuật này như một nền tảng vững chắc giúp thu hẹp khoảng cách giữa các mô hình ngôn ngữ hiện nay (LLM) và khả năng ghi nhớ linh hoạt của con người.
Điểm đặc biệt của Nested Learning là cách tư duy lại hoàn toàn về cấu trúc và thuật toán tối ưu của AI. Nếu trước đây, các nhà phát triển thường xem kiến trúc mô hình và thuật toán tối ưu là hai phần tách biệt, thì Nested Learning lại kết hợp cả hai thành một thể thống nhất.
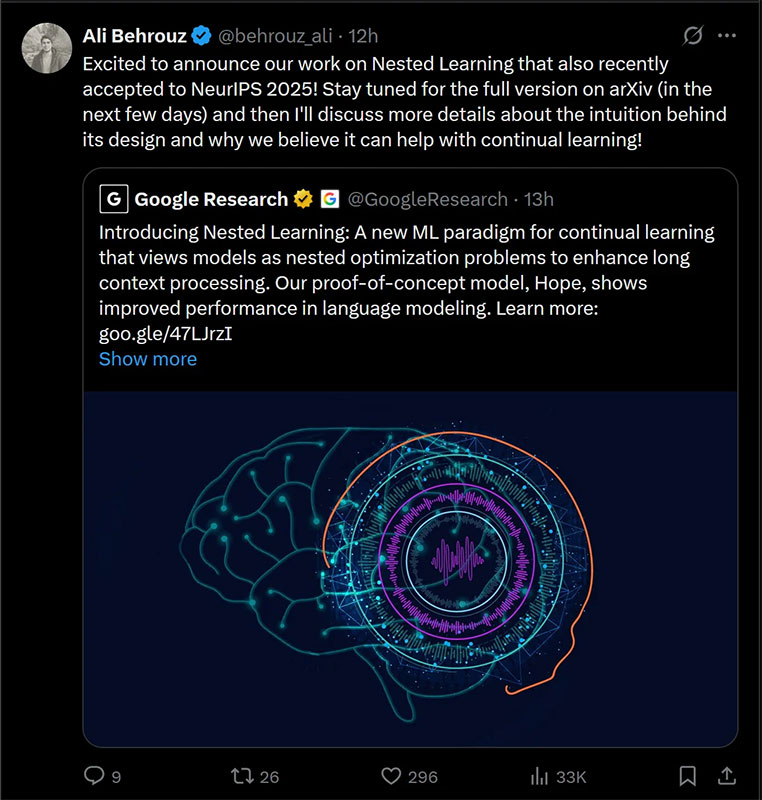
Mô hình học theo “nhiều tầng tốc độ”
Với Nested Learning, một mô hình AI được chia nhỏ thành các “bài toán tối ưu lồng nhau” (nested optimization problems). Mỗi phần nhỏ này được phép học và cập nhật kiến thức ở một tốc độ riêng biệt — kỹ thuật được gọi là multi-time-scale updates (cập nhật đa tốc độ).
Cơ chế này mô phỏng đúng cách não người xử lý thông tin: khi tiếp nhận trải nghiệm mới, chỉ một phần của não thay đổi để thích nghi, trong khi phần còn lại vẫn giữ nguyên ký ức cũ.
Nhờ đó, AI có thể học thêm điều mới mà không “xóa sổ” kiến thức trước đó, tạo nên một hệ thống học tập có tầng lớp, linh hoạt và bền vững hơn.
Mô hình thử nghiệm “Hope”
Từ nguyên lý này, Google Research đã phát triển một mô hình thử nghiệm có tên Hope — viết tắt của Hierarchical Optimization and Plasticity Engine . Hope là một kiến trúc tự điều chỉnh (self-modifying recurrent architecture), có khả năng tự tối ưu hóa bộ nhớ của chính mình.
Mô hình này sử dụng Continuum Memory Systems, coi bộ nhớ không phải chỉ gồm hai loại “ngắn hạn” và “dài hạn”, mà là một dải liên tục gồm nhiều tầng bộ nhớ khác nhau, mỗi tầng cập nhật ở một nhịp riêng. Nhờ đó, Hope có thể lưu trữ, xử lý và duy trì thông tin phong phú hơn theo thời gian, đồng thời tránh được tình trạng “quên kiến thức cũ” khi học thêm nội dung mới.
Kết quả thử nghiệm cho thấy Hope vượt trội hơn các mô hình hiện nay trong những bài kiểm tra ghi nhớ ngữ cảnh dài hạn (long-context tasks), đặc biệt là bài “Needle-In-Haystack”, nơi AI phải tìm lại một chi tiết nhỏ nằm sâu trong văn bản dài. Ngoài ra, mô hình cũng cho thấy độ chính xác và hiệu suất cao hơn trong các bài kiểm tra ngôn ngữ tổng quát.
Dù Google chưa công bố thời điểm triển khai cụ thể, nhóm nghiên cứu cho biết các cải tiến từ Nested Learning và mô hình Hope sẽ sớm được tích hợp vào các phiên bản tương lai của Google Gemini. Nếu thành công, đây có thể là bước ngoặt giúp AI tiến gần hơn đến khả năng ghi nhớ và học tập linh hoạt như con người.





 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học