 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

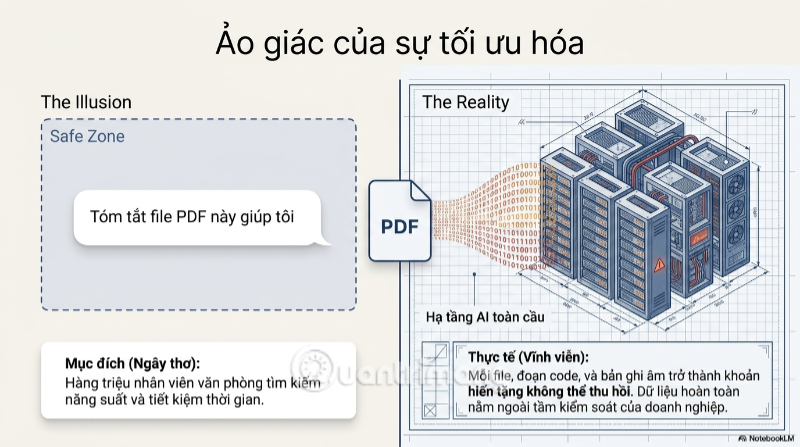
Mỗi ngày, hàng triệu nhân viên văn phòng nhấn nút "Upload file hoặc ảnh của bạn" lên trên ChatGPT, Claude hay Gemini với một niềm tin rằng họ chỉ đang tiết kiệm thời gian. Nhưng phía sau giao diện chat thân thiện ấy là một cỗ máy thu thập dữ liệu khổng lồ, nơi mỗi file PDF, mỗi đoạn code, mỗi bản ghi âm cuộc họp đều có thể trở thành một phần vĩnh viễn của hạ tầng AI toàn cầu - nằm ngoài tầm kiểm soát của chính doanh nghiệp đã tạo ra nó.

Vấn nạn "Shadow AI"
Trong giới an ninh mạng, người ta gọi đó là "Shadow AI" - AI trong bóng tối. Khái niệm này mô tả chính xác một thực trạng đang lan rộng: nhân viên sử dụng các công cụ AI cá nhân, miễn phí, để xử lý công việc của công ty, hoàn toàn nằm ngoài sự giám sát hay phê duyệt của bộ phận IT và bảo mật. Không cần xin phép, không cần khai báo, chỉ cần một tài khoản Gmail và vài giây đăng ký.
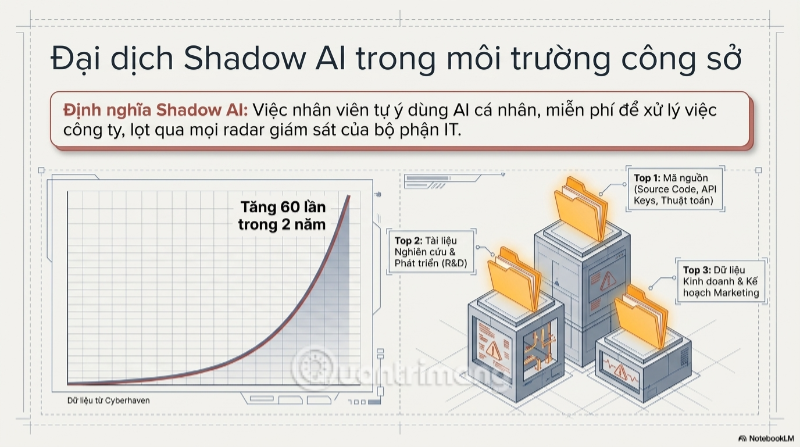
Vấn đề không nằm ở việc nhân viên có ác ý, ngược lại, phần lớn trường hợp xuất phát từ chính sự tận tâm quá mức với công việc. Một báo cáo gần đây của Cyberhaven - công ty bảo mật dữ liệu đã phân tích hành vi sử dụng AI của hàng triệu lao động tri thức, cho thấy mức độ phổ biến đáng kinh ngạc của hiện tượng này. Đó là tần suất sử dụng AI tại nơi làm việc đã tăng tới hơn 60 lần trong vòng hai năm, lan nhanh nhất ở các ngành sản xuất và bán lẻ - những lĩnh vực vốn ít được trang bị nhận thức về an ninh dữ liệu AI.
Hành vi "dâng nạp" dữ liệu diễn ra dưới nhiều hình thái khác nhau tùy theo từng nhóm ngành. Dân tài chính âm thầm dán các bảng doanh thu, dòng tiền, kế hoạch kinh doanh vào khung chat để AI giúp họ viết báo cáo nhanh hơn.
Giới lập trình viên copy-paste cả khối source code chứa API Key hay thuật toán cốt lõi, chỉ để nhờ AI tìm lỗi hoặc tối ưu hiệu năng. Bộ phận nhân sự và vận hành thì tải lên file ghi âm, video họp nội bộ, thậm chí cả bảng lương, với mục đích tưởng chừng vô hại: tóm tắt nội dung, phân tích hiệu suất nhân viên.
Theo phân tích của Cyberhaven dựa trên dữ liệu thực tế từ hàng triệu lượt tương tác, nguồn dữ liệu nhạy cảm bị đưa vào các công cụ AI nhiều nhất chính là mã nguồn (source code), tiếp theo là tài liệu nghiên cứu và phát triển sản phẩm (R&D), rồi đến dữ liệu kinh doanh và marketing. Điều đáng nói là đây không phải lỗi của một vài cá nhân bất cẩn riêng lẻ - nghiên cứu cho thấy việc nhân viên đưa dữ liệu nhạy cảm vào các công cụ AI diễn ra với tần suất trung bình chỉ vài ngày một lần trên quy mô toàn doanh nghiệp.
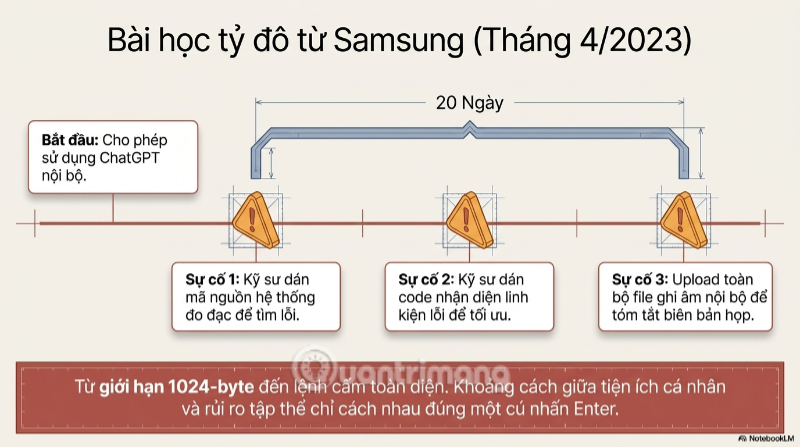
Không có case-study nào minh họa rõ hơn cho vấn nạn này bằng vụ việc xảy ra với Samsung vào tháng 4 năm 2023. Chỉ trong vòng chưa đầy 20 ngày sau khi tập đoàn bán dẫn cho phép nhân viên sử dụng ChatGPT, ba sự cố rò rỉ dữ liệu nghiêm trọng liên tiếp đã xảy ra. Một kỹ sư dán nguyên đoạn mã nguồn từ hệ thống đo đạc thiết bị nội bộ vào ChatGPT để tìm cách sửa lỗi. Một kỹ sư khác thì lại đưa vào đoạn code dùng để xác định linh kiện lỗi, nhờ AI tối ưu hóa cho. Trường hợp thứ ba thậm chí còn đáng lo hơn, đó là một nhân viên ghi âm toàn bộ một cuộc họp nội bộ, chuyển thành văn bản, rồi nhờ ChatGPT tóm tắt thành biên bản họp.
Hậu quả tức thì là Samsung phải áp dụng biện pháp khẩn cấp, bao gồm giới hạn mỗi lượt nhập liệu vào ChatGPT chỉ còn 1024 byte - một động thái chữa cháy mang tính tạm bợ hơn là giải pháp triệt để.
Thế rồi ít tuần sau, tập đoàn này ban hành lệnh cấm toàn diện việc sử dụng các công cụ AI tạo sinh trong nội bộ, đồng thời cảnh báo nhân viên rằng hành vi vi phạm có thể dẫn đến kỷ luật, kể cả sa thải. Đó là minh chứng sống cho việc khoảng cách giữa "tiện ích cá nhân" và "rủi ro tập thể" trong thời đại AI tạo sinh có thể chỉ cách nhau một cú nhấn Enter.
Điều gì đang thực sự xảy ra sau nút "Tải tệp lên"
Để hiểu vì sao một động tác tưởng chừng đơn giản như tải file lên AI lại nguy hiểm đến vậy, cần phải bóc tách cơ chế kỹ thuật ẩn sau giao diện chat thân thiện đó.
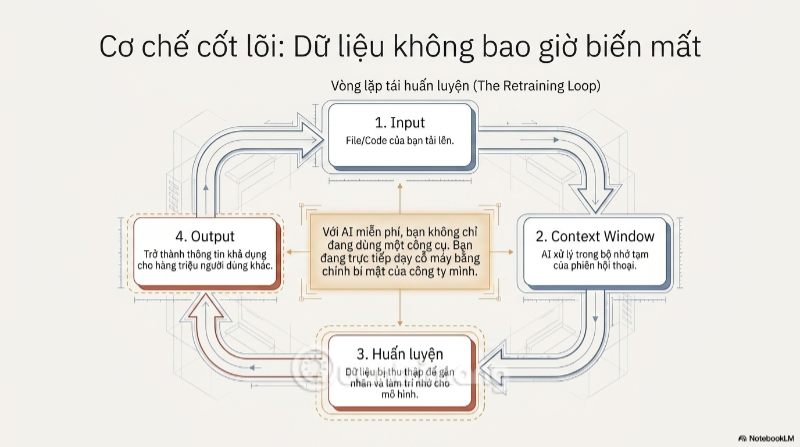
Với hầu hết các mô hình AI thương mại ở bản miễn phí, dữ liệu người dùng nhập vào không chỉ đơn thuần được xử lý rồi biến mất. Nó có thể bước vào cái gọi là "vòng lặp tái huấn luyện" (the retraining loop) - một quy trình mà các công ty phát triển AI sử dụng lại các cuộc hội thoại, file tải lên, để gắn nhãn và đưa vào tập dữ liệu huấn luyện cho những phiên bản mô hình tiếp theo. Nói cách khác, đoạn code bạn dán vào hôm nay có thể, theo đúng nghĩa đen, trở thành một phần "trí nhớ" của mô hình AI trong vài tháng tới.
Chính cơ chế này đã được nhắc đến công khai khi giới truyền thông đưa tin về vụ Samsung, vì ChatGPT là một nền tảng học máy, toàn bộ dữ liệu nhập vào đều được dùng để huấn luyện thuật toán của nó, đồng nghĩa với việc thông tin độc quyền của Samsung đã trở thành một phần khả dụng cho những người dùng khác trên cùng nền tảng.
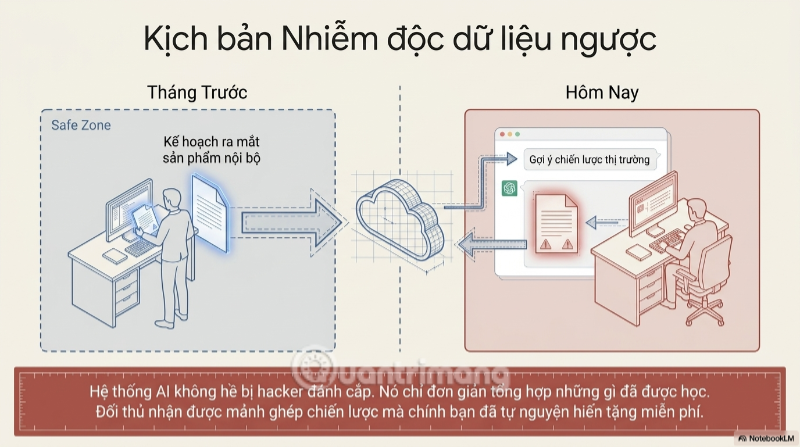
Từ đây nảy sinh một nguy cơ còn tinh vi và đáng sợ hơn - kịch bản "AI nhiễm độc dữ liệu" (data poisoning theo hướng ngược). Hãy tưởng tượng đối thủ cạnh tranh của bạn, vài tuần sau khi bạn vô tình tải lên một bản kế hoạch ra mắt sản phẩm, đặt một câu hỏi tưởng như ngẫu nhiên cho cùng một công cụ AI - và nhận lại gợi ý chứa đựng những mảnh ghép thông tin chiến lược mà chính họ không hề biết bạn đã "hiến tặng" miễn phí. Mô hình AI không "rò rỉ" dữ liệu theo nghĩa hacker đánh cắp; nó chỉ đơn giản tổng hợp lại những gì đã học được - và bạn chính là một trong những giáo viên dạy nó.
Đây chính là lý do tại sao hàng loạt tổ chức tài chính lớn như JPMorgan từng thừa nhận họ thậm chí không thể xác định được có bao nhiêu nhân viên đang dùng ChatGPT hay dùng để làm gì, bởi các công cụ bảo mật truyền thống (DLP - Data Loss Prevention) được thiết kế để giám sát file đính kèm email hay ổ đĩa chia sẻ, hoàn toàn "mù" trước hành vi copy-paste trực tiếp vào một trình duyệt web.
Vấn đề càng trở nên rõ ràng hơn khi nhìn vào "bẫy điều khoản dịch vụ" - sự khác biệt mang tính sống còn giữa phiên bản AI miễn phí và phiên bản doanh nghiệp (Enterprise). Ở các gói miễn phí dành cho cá nhân, điều khoản sử dụng thường cho phép nhà cung cấp dùng nội dung hội thoại để cải thiện mô hình, trừ khi người dùng tự tay vào cài đặt để tắt tùy chọn này - một bước mà phần lớn nhân viên chưa từng nghĩ tới.
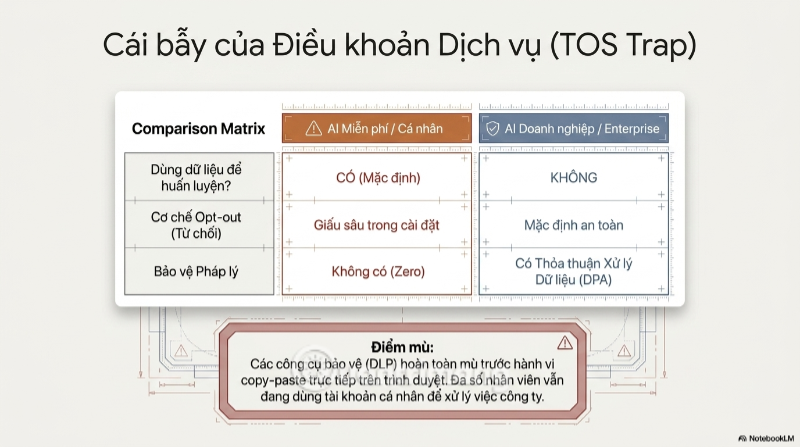
Ngược lại, các gói Enterprise hoặc API doanh nghiệp thường đi kèm cam kết hợp đồng rõ ràng: dữ liệu khách hàng không được dùng để huấn luyện mô hình, có thời hạn lưu trữ giới hạn, và đi kèm các điều khoản bảo mật ở cấp độ pháp lý (Data Processing Agreement). Khoảng cách giữa hai cấp độ này chính là khoảng trống mà phần lớn vụ rò rỉ dữ liệu doanh nghiệp đang rơi vào - không phải vì công nghệ thiếu an toàn, mà vì người dùng vô tình chọn nhầm "cánh cửa".
Thực tế cho thấy ranh giới giữa dùng cá nhân và dùng doanh nghiệp mong manh hơn nhiều người tưởng: phân tích từ Cyberhaven chỉ ra rằng phần lớn lượt truy cập ChatGPT tại nơi làm việc vẫn đến từ tài khoản cá nhân không qua kiểm soát của doanh nghiệp, và tỷ lệ này còn cao hơn đáng kể với các nền tảng AI khác. Nói cách khác, ngay cả khi công ty bạn đã ký hợp đồng Enterprise với một nhà cung cấp AI, điều đó không đồng nghĩa với việc toàn bộ nhân viên đang sử dụng đúng "cánh cửa an toàn" ấy.
Ma trận pháp lý và những "bản án" vô hình
Nếu rủi ro kỹ thuật là vô hình, thì rủi ro pháp lý lại đang ngày càng hiện hữu bằng những con số rất cụ thể.
Tại châu Âu, Quy định Bảo vệ Dữ liệu Chung (GDPR) tiếp tục là "thanh gươm" sắc nhất với các doanh nghiệp xử lý dữ liệu cá nhân sai cách - kể cả khi sai sót đến từ một công cụ AI bên thứ ba. Tổng mức phạt GDPR lũy kế từ năm 2018 đến nay đã vượt mốc 7 tỷ euro, riêng năm 2025 các cơ quan quản lý châu Âu đã áp mức phạt lên tới 1,2 tỷ euro.

Đáng chú ý, giới quản lý không chỉ nhắm vào Big Tech: cơ quan bảo vệ dữ liệu Ý từng phạt một công ty AI phát triển chatbot 5 triệu euro vì thu thập dữ liệu cá nhân và hành vi người dùng mà không có sự đồng ý hợp lệ, đồng thời thiếu cơ chế xác minh tuổi người dùng. Với Đạo luật AI của EU (EU AI Act) chính thức siết chặt thực thi từ tháng 8/2026, mức phạt tối đa cho các vi phạm nghiêm trọng có thể lên đến 35 triệu euro hoặc 7% doanh thu toàn cầu - cao hơn cả trần phạt của GDPR truyền thống.
Tại Việt Nam, khung pháp lý tương ứng là Nghị định 13/2023/NĐ-CP về Bảo vệ dữ liệu cá nhân, được Chính phủ ban hành ngày 17/4/2023 và có hiệu lực từ 1/7/2023, gồm 44 điều khoản quy định chi tiết về việc thu thập, lưu trữ, xử lý và chuyển giao dữ liệu cá nhân. Nghị định này phân loại doanh nghiệp thành các vai trò pháp lý cụ thể - Bên Kiểm soát dữ liệu hoặc Bên Xử lý dữ liệu - và mỗi vai trò đi kèm trách nhiệm pháp lý riêng khi xảy ra sự cố. Điểm đáng lưu tâm là phạm vi áp dụng của Nghị định 13 không chỉ giới hạn trong lãnh thổ Việt Nam - nó áp dụng cho cả dữ liệu cá nhân của công dân Việt Nam được xử lý ở nước ngoài, nghĩa là việc một nhân viên Việt Nam tải file chứa thông tin khách hàng lên một server AI đặt tại Mỹ hoàn toàn có thể nằm trong phạm vi điều chỉnh của luật trong nước.
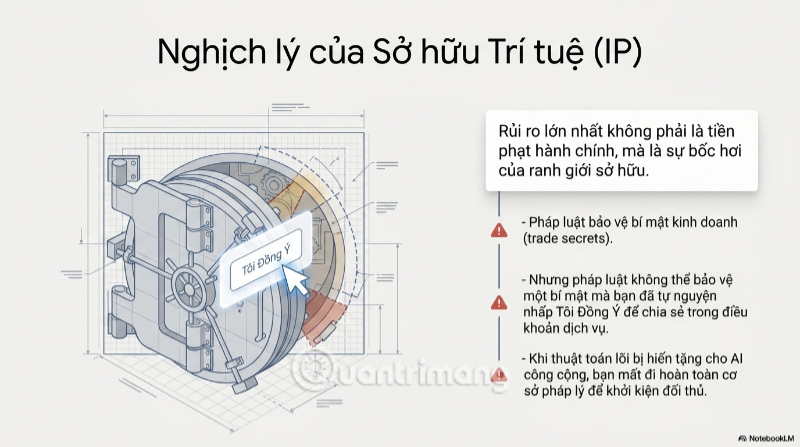
Nhưng có một lớp rủi ro khác còn nguy hiểm hơn vi phạm hành chính: mất quyền sở hữu trí tuệ (IP). Khi một thuật toán độc quyền, một công thức tính giá, hay một đoạn code lõi được đưa vào mô hình AI công cộng, ranh giới pháp lý về "ai sở hữu cái gì" trở nên vô cùng mập mờ.
Nếu sau này một đối thủ tung ra sản phẩm có logic tương tự, doanh nghiệp gốc gần như không có cơ sở để khởi kiện - bởi chính họ đã tự nguyện "công khai hóa" bí mật kinh doanh của mình thông qua điều khoản dịch vụ mà ít ai đọc kỹ trước khi nhấn "Tôi đồng ý". Đây chính là nghịch lý cay đắng nhất của vấn đề: pháp luật bảo vệ bí mật kinh doanh, nhưng không thể bảo vệ một bí mật mà chủ nhân của nó đã tự tay trao đi.
Xu hướng Self-Hosted và AI tự chủ
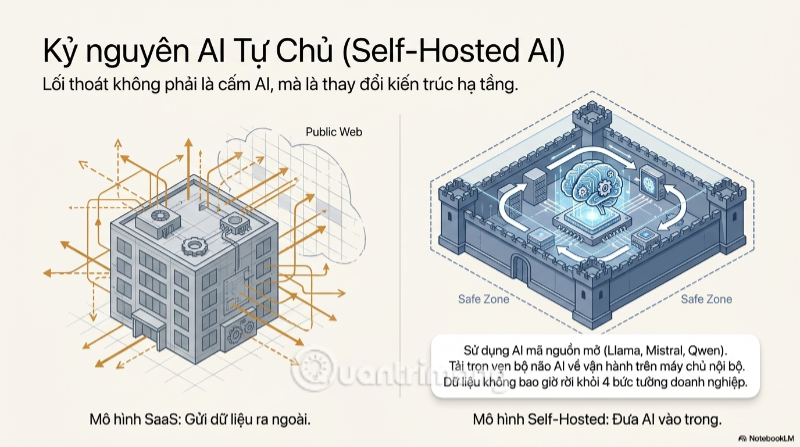
Giữa bối cảnh rủi ro chồng chất, một làn sóng công nghệ đang nổi lên như lối thoát thực sự: AI mã nguồn mở (open-source LLM). Các mô hình như Llama của Meta, Mistral từ Pháp, hay Qwen của Alibaba đang chứng minh rằng sức mạnh suy luận của AI không còn là đặc quyền riêng của những "ông lớn" vận hành cloud kín. Khác biệt cốt lõi nằm ở chỗ: với mô hình mã nguồn mở, doanh nghiệp có thể tải toàn bộ "bộ não" AI về và vận hành ngay trên hạ tầng riêng của mình - nghĩa là dữ liệu không bao giờ phải rời khỏi bốn bức tường công ty.
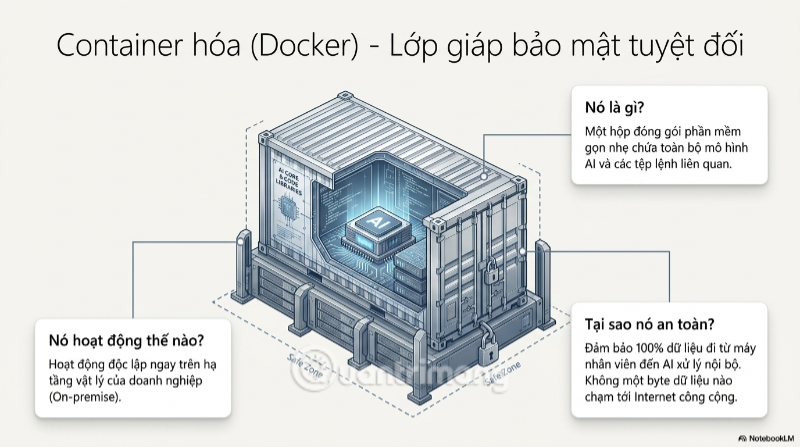
Công nghệ hiện thực hóa giải pháp này chính là container hóa, với Docker là cái tên phổ biến nhất. Nguyên lý vận hành rất đơn giản nhưng hiệu quả tuyệt đối về mặt bảo mật: dữ liệu đi từ máy nhân viên, qua một server nội bộ đang chạy container Docker chứa mô hình AI, AI xử lý và phân tích ngay tại đó - toàn bộ quy trình không một byte dữ liệu nào thoát ra khỏi mạng nội bộ để chạm tới Internet công cộng. Đây là sự đảo ngược hoàn toàn so với mô hình SaaS truyền thống, nơi dữ liệu luôn phải "đi du lịch" đến server của một bên thứ ba trước khi quay về kết quả.
Một mảnh ghép công nghệ khác đang được nhiều doanh nghiệp triển khai song song là kiến trúc RAG (Retrieval-Augmented Generation) nội bộ. Thay vì "nhồi" toàn bộ tài liệu công ty vào quá trình huấn luyện AI - một việc vừa tốn kém vừa rủi ro - RAG cho phép "băm nhỏ" tài liệu thành các đoạn dữ liệu, lưu trữ trong một cơ sở dữ liệu vector (Vector Database) đặt ngay trên hạ tầng riêng của doanh nghiệp.
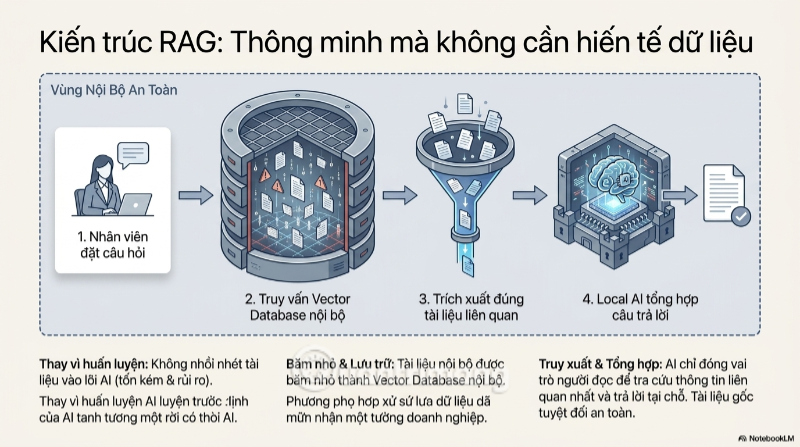
Khi nhân viên đặt câu hỏi, AI sẽ "tra cứu" tại chỗ trong chính cơ sở dữ liệu đó để tìm thông tin liên quan nhất, rồi tổng hợp câu trả lời - toàn bộ tài liệu gốc không hề bị đưa vào quá trình huấn luyện mô hình và không rời khỏi hệ thống nội bộ. Đây được xem là giải pháp dung hòa tối ưu: doanh nghiệp vẫn có được trải nghiệm AI thông minh, cá nhân hóa theo đúng dữ liệu của mình, mà không phải đánh đổi bằng việc "hiến tặng" dữ liệu cho bên thứ ba.
Tất nhiên, con đường self-hosted không miễn phí về công sức. Doanh nghiệp cần đầu tư hạ tầng server, nhân lực kỹ thuật để duy trì hệ thống, và mô hình mã nguồn mở thường đòi hỏi việc fine-tuning (tinh chỉnh) để đạt độ chính xác tương đương các mô hình thương mại hàng đầu. Nhưng so với cái giá phải trả khi xảy ra một vụ rò rỉ dữ liệu - từ thiệt hại uy tín, mất lợi thế cạnh tranh, đến các khoản phạt pháp lý có thể lên tới hàng triệu USD - chi phí đầu tư ban đầu cho hạ tầng AI tự chủ ngày càng trở thành một bài toán kinh tế dễ thuyết phục hơn bao giờ hết.
Kết luận & dự báo tương lai
Thông điệp cốt lõi rút ra từ toàn bộ câu chuyện này không phải là "cấm đoán" nhân viên sử dụng AI - một chiến lược chắc chắn sẽ khiến doanh nghiệp tụt lại trong cuộc đua năng suất, đồng thời đẩy nhân viên quay lại dùng "chui" các công cụ cá nhân một cách lén lút, càng khó kiểm soát hơn. Bài học thực sự là chuyển từ tư duy "ngăn chặn" sang tư duy "kiểm soát và tạo môi trường an toàn".
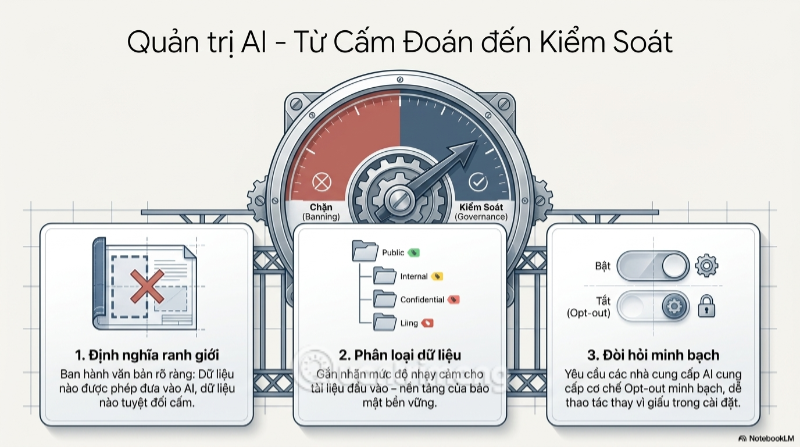
Với các nhà quản lý doanh nghiệp, hành động cụ thể cần bắt đầu từ việc xây dựng một chính sách AI Governance (quản trị AI) rõ ràng - văn bản không cần dài dòng, nhưng phải trả lời được câu hỏi: loại dữ liệu nào được phép đưa vào AI, loại nào tuyệt đối cấm, và công cụ AI nào đã được phê duyệt sử dụng chính thức. Song song đó là việc phân loại dữ liệu đầu vào theo cấp độ nhạy cảm - một bước tưởng đơn giản nhưng lại là nền tảng của mọi chiến lược bảo mật AI bền vững.
Với các nhà phát triển AI, áp lực minh bạch hóa đang ngày càng lớn. Việc tối ưu hóa các tùy chọn "Opt-out" (từ chối tham gia huấn luyện) sao cho dễ tìm thấy, dễ kích hoạt hơn - chứ không bị giấu sâu trong menu cài đặt - không chỉ là vấn đề đạo đức mà đang trở thành một lợi thế cạnh tranh thực sự, khi ngày càng nhiều doanh nghiệp đặt yếu tố bảo mật dữ liệu lên hàng đầu khi lựa chọn nhà cung cấp AI.

Nút "Upload" sẽ không biến mất. Nhưng cách chúng ta hiểu về nó - như một cánh cửa hai chiều, vừa mở ra năng suất, vừa có thể mở toang bí mật kinh doanh - chính là ranh giới mong manh quyết định doanh nghiệp nào sẽ tồn tại an toàn trong kỷ nguyên AI, và doanh nghiệp nào sẽ trở thành case-study cảnh báo tiếp theo.
Check-list cho nhà quản lý: 3 câu hỏi trước khi cho phép nhân viên upload file lên AI
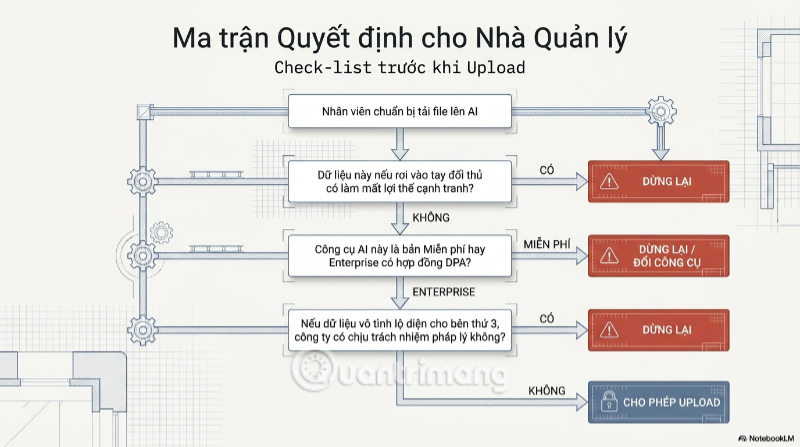
Dữ liệu này nếu rơi vào tay đối thủ, hậu quả lớn đến mức nào?
- Nếu câu trả lời là "có thể ảnh hưởng đến lợi thế cạnh tranh", đó là dấu hiệu đầu tiên cần dừng lại.
Công cụ AI đang dùng là bản miễn phí cá nhân hay bản Enterprise có hợp đồng bảo mật?
- Hai cấp độ này khác nhau hoàn toàn về quyền sử dụng dữ liệu.
Nếu dữ liệu này vô tình xuất hiện trong câu trả lời AI cho một người dùng khác, công ty có chịu trách nhiệm pháp lý gì không?
- Câu hỏi này buộc nhà quản lý nhìn nhận rủi ro không chỉ ở góc độ kỹ thuật mà cả góc độ pháp lý.
Thuật ngữ chuyên ngành đại chúng
Context Window: Hiểu đơn giản là "bộ nhớ tạm" của AI trong một cuộc hội thoại - toàn bộ nội dung bạn đã nhập vào, bao gồm file tải lên, đều nằm trong "vùng nhớ" này để AI tham chiếu khi trả lời.
Data Leakage: Tình trạng dữ liệu nội bộ, nhạy cảm bị "thoát" ra ngoài phạm vi kiểm soát của tổ chức - không nhất thiết do hacker tấn công, mà thường xuất phát từ chính hành vi sử dụng công cụ thường ngày của nhân viên.
On-premise AI: Mô hình AI được cài đặt và vận hành ngay tại hạ tầng vật lý của doanh nghiệp (máy chủ riêng, trung tâm dữ liệu nội bộ), trái ngược với việc gửi dữ liệu lên cloud của một công ty AI bên ngoài.
Docker Container: Một "hộp đóng gói" phần mềm gọn nhẹ, giúp đóng gói toàn bộ một ứng dụng AI cùng mọi thứ nó cần để chạy, từ đó dễ dàng triển khai trên server nội bộ mà không cần cấu hình phức tạp hay phụ thuộc vào hạ tầng cloud bên ngoài.






 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học