 AI
AI  ChatGPT
ChatGPT  Gemini
Gemini  Thư viện Prompt
Thư viện Prompt  Công nghệ
Công nghệ  Học IT
Học IT  Tiện ích
Tiện ích 
DeepMind, một công ty của Google có trụ sở tại Anh mới đây đã phát triển ra Generative Query Network (GQN) - một mạng neural network được thiết kế để dạy trí tuệ nhân tạo (AI) cách tưởng tượng ra đồ vật sẽ trông như thế nào từ một phía khác.
Cụ thể, AI sẽ phân tích hình ảnh 2D rồi có thể kết xuất được toàn cảnh 3D. Điều đáng nói là trí thông minh nhân tạo của DeepMind chỉ xem qua ít nhất 3 tấm hình chứ không hề sử dụng các dữ liệu nhập hay kho kiến thức nào cả, rồi có thể ngay lập tức dự đoán phiên bản 3D của hình ảnh đó sẽ ra sao.
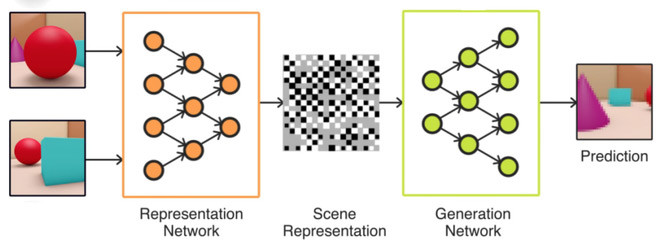
Các nhà nghiên cứu AI đang nỗ lực để dạy cho máy móc cách nhận thức được như con người, đưa ra các giả định sau khi quan sát môi trường xung quanh mà cụ thể là đoán hình dáng của đồ đạc, cảnh vật ở khía cạnh mà nó chưa được "chiêm ngưỡng".
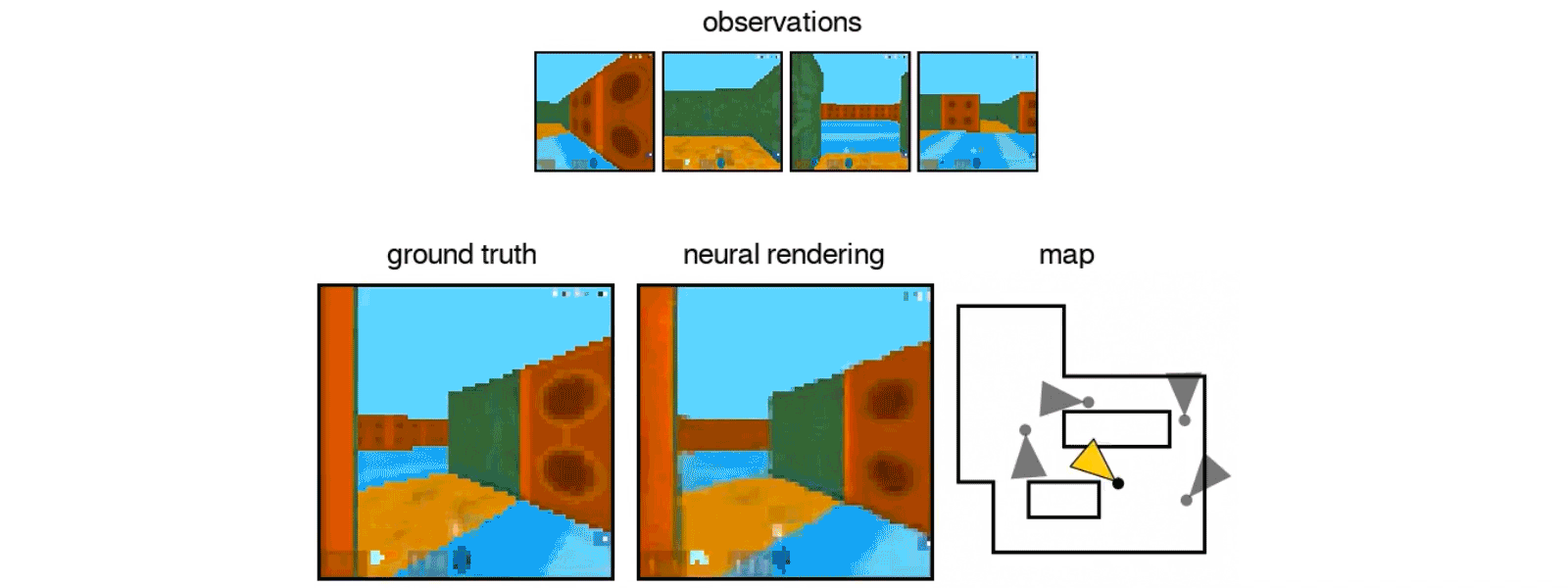
Ví dụ, bạn chụp bức ảnh một khối rubic và yêu cầu Ai tái tạo lại tấm hình từ một góc độ khác. Trí tuệ nhân tạo – nhờ sử dụng GQN, phải tự hình dung ra khối rubic (ánh sáng, đổ bóng, các đường thẳng của khối) sẽ như thế nào ở các mặt còn lại để có thể kết xuất ra hình ảnh mà ta cần.
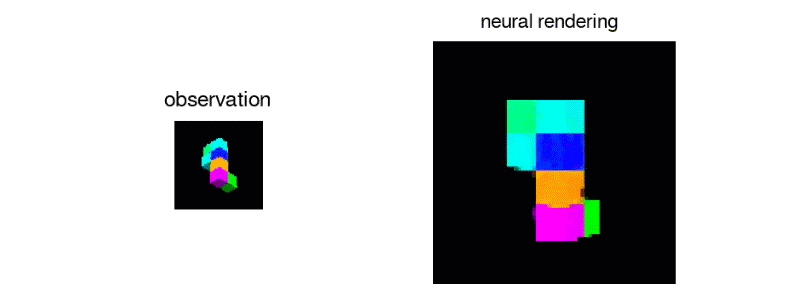
Hiện tại, hệ thống trí tuệ nhân tạo của DeepMind vẫn chưa được luyện tập với hình ảnh của thế giới thật. Tiếp theo các nhà nghiên cứu sẽ cho nó render lại danh lam thắng cảnh đời thật từ ảnh.
Hệ thống sử dụng GQN của Deepmind được kỳ vọng có thể chỉ sử dụng ảnh 2D có thể tạo ra cảnh 3D cực chuẩn xác trong tương lai.
Xem thêm:













 AI
AI  Hướng dẫn AI
Hướng dẫn AI  Ứng dụng
Ứng dụng  Hệ thống
Hệ thống  Game - Trò chơi
Game - Trò chơi  iPhone
iPhone  Android
Android  Hàm Excel
Hàm Excel  Download
Download  Khoa học
Khoa học  Cuộc sống
Cuộc sống  Làng Công nghệ
Làng Công nghệ