 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Các thuật toán nén video hiện đại không giống như các thuật toán nén hình ảnh mà bạn đã quen thuộc trước đây. Việc tăng thêm kích thước và thời gian có nghĩa là các kỹ thuật toán học và logic khác nhau được áp dụng cho file video để giảm kích thước nhưng vẫn duy trì chất lượng video.
Bài viết này đã sử dụng H.264 làm tiêu chuẩn nén nguyên mẫu. Mặc dù nó không còn là định dạng nén video mới nhất, nhưng vẫn là một ví dụ đủ chi tiết để giải thích các khái niệm chính về nén video.
Tìm hiểu về hoạt động của các thuật toán nén video
Nén video là gì?
Các thuật toán nén video tìm kiếm thời gian và không gian dư thừa. Bằng cách mã hóa dữ liệu dư thừa một số lần tối thiểu, kích thước file có thể được giảm. Ví dụ, bạn cần nén một cảnh quay nhấn mạnh sự thay đổi biểu cảm từ từ trên khuôn mặt của nhân vật, kéo dài trong 1 phút. Nén không có ý nghĩa là mã hóa hình ảnh trên mọi khung hình (frame), mà thay vào đó, bạn có thể mã hóa 1 khung hình, sau đó tham chiếu đến khung hình mã hóa đó cho đến khi video thay đổi. Mã hóa dự đoán liên khung này chịu trách nhiệm về những thành phần lạ, không đáng tin cậy xuất hiện trong quá trình nén video: những phần của hình ảnh cũ chuyển động không chính xác vì có yếu tố nào đó trong quá trình mã hóa bị hỏng.
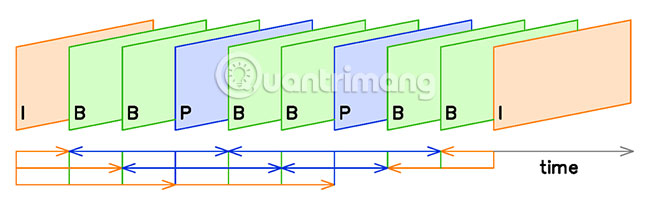
I-frame, P-frame và B-frame

I-frame là hình ảnh được mã hóa đầy đủ. Mỗi I-frame chứa tất cả dữ liệu cần thiết để thể hiện một hình ảnh. P-frame được dự đoán dựa trên cách thay đổi hình ảnh từ I-frame cuối cùng. B-frame được dự đoán theo hai chiều, sử dụng dữ liệu từ cả P-frame cuối cùng và I-frame tiếp theo. P-frame chỉ cần lưu trữ thông tin hình ảnh duy nhất cho chính nó. Trong ví dụ trên, P-frame cần theo dõi cách các chấm di chuyển trên khung hình, còn Pac-Man có thể giữ nguyên vị trí của mình.
B-frame nhìn vào P-frame, I-frame tiếp theo và chuyển động trung bình trên các frame đó. Thuật toán biết nơi hình ảnh bắt đầu (I-frame đầu tiên) và kết thúc (I-frame thứ hai) và nó sử dụng dữ liệu từng phần để mã hóa dự đoán, loại bỏ tất cả các pixel tĩnh không cần thiết để tạo hình ảnh.
Mã hóa Intraframe (I-frame)
I-frame được nén độc lập, giống như cách hình ảnh tĩnh được lưu. Do I-frame không sử dụng dữ liệu dự đoán, hình ảnh nén chứa tất cả dữ liệu được sử dụng để hiển thị I-frame. Các I-frame vẫn được nén bởi một thuật toán nén hình ảnh như JPEG. Mã hóa này thường diễn ra trong không gian màu YCbCr, phân tách dữ liệu độ sáng khỏi dữ liệu màu, cho phép chuyển động và những thay đổi về màu sắc được mã hóa riêng biệt.
Đối với các non-predictive codec như DV và Motion JPEG, mọi thứ sẽ dừng lại tại đó. Do không có predictive frame, nên việc duy nhất có thể làm được là nén hình ảnh trong một frame duy nhất. Phương pháp kém hiệu quả hơn nhưng tạo ra một file hình ảnh thô (raw) chất lượng cao hơn.
Trong các codec sử dụng predictive frame như H.264, predictive frame được định kỳ hiển thị để làm mới luồng dữ liệu, bằng cách đặt frame tham chiếu mới. Các I-frame càng xa nhau, file video càng nhỏ. Tuy nhiên, nếu các I-frame cách nhau quá xa, độ chính xác của các predictive frame trong video sẽ từ từ giảm xuống mức không thể hiểu được. Một ứng dụng được tối ưu hóa băng thông sẽ chèn các I-frame ít nhất có thể mà không phá vỡ luồng video. Tần suất của các I-frame thường được xác định một cách gián tiếp bởi cài đặt “chất lượng” trong phần mềm mã hóa. Phần mềm nén video chuyên nghiệp như ffmpeg cho phép kiểm soát rõ ràng vấn đề này.
Interframe Prediction (P-frame và B-frame)
Các bộ mã hóa video cố gắng để “dự đoán” thay đổi từ một frame này sang frame tiếp theo. Dự đoán của bộ mã hóa càng chính xác, thuật toán nén càng hiệu quả. Đây là những gì tạo ra P-frame và B-frame. Số lượng, tần suất và thứ tự chính xác của các predictive frame, cũng như thuật toán cụ thể được sử dụng để mã hóa và tái tạo chúng, được xác định bởi thuật toán cụ thể bạn sử dụng.

Hãy xem xét cách thức hoạt động của H.264. Frame được chia thành các phần gọi là macroblock, thường bao gồm những sample 16 x 16. Thuật toán không mã hóa các giá trị pixel thô cho mỗi block (khối). Thay vào đó, bộ mã hóa tìm kiếm một block tương tự trong một frame cũ, được gọi là frame tham chiếu. Nếu tìm thấy frame tham chiếu hợp lệ, block sẽ được mã hóa bằng biểu thức toán học gọi là vectơ chuyển động, mô tả bản chất chính xác của thay đổi từ block tham chiếu sang block hiện tại. Khi video được phát, trình phát video sẽ diễn giải các vectơ chuyển động đó một cách chính xác để “dịch lại” video. Nếu block không thay đổi, thì không cần đến vector.

Sau khi dữ liệu được sắp xếp vào các frame, nó sẽ được mã hóa thành biểu thức toán học với bộ mã hóa biến đổi (transform encoder). H.264 sử dụng một DCT (discrete-cosine transform) để thay đổi dữ liệu trực quan thành biểu thức toán học (cụ thể là tổng các hàm cosin dao động ở những tần số khác nhau). Thuật toán nén được chọn xác định bộ mã hóa biến đổi. Sau đó, dữ liệu được “làm tròn” bởi bộ định lượng. Cuối cùng, các bit được chạy thông qua thuật toán nén không mất dữ liệu để thu nhỏ kích thước file thêm một lần nữa. Việc này không làm thay đổi dữ liệu. Nó chỉ tổ chức dữ liệu ở dạng nhỏ gọn nhất có thể. Sau đó, video được nén, kích thước nhỏ hơn trước và sẵn sàng để xem.







 Ứng dụng
Ứng dụng
 Thương mại Điện tử
Thương mại Điện tử
 Nhạc, phim, truyện online
Nhạc, phim, truyện online
 Phần mềm học tập
Phần mềm học tập
 Hướng dẫn AI
Hướng dẫn AI
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học