 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Với lượng code nhỏ và một số thư viện hữu ích của LangChain và OpenAPI, bạn có thể xây dựng công cụ phân tích tài liệu mạnh mẽ. Dưới đây là hướng dẫn chi tiết.

Việc trích xuất thông tin chi tiết từ tài liệu và dữ liệu góp phần quan trọng trong việc đưa ra những quyết định sáng suốt.. Tuy nhiên, mối lo ngại về tính riêng tư phát sinh khi xử lý thông tin nhạy cảm. LangChain, kết hợp với OpenAI API, cho phép bạn phân tích tài liệu cục bộ mà không cần phải upload chúng online.
Chúng giúp bạn đạt được điều này bằng cách lưu giữ dữ liệu cục bộ, sử dụng các phần nhúng và vector hóa để phân tích, đồng thời triển khai các quá trình trong môi trường của bạn. OpenAI không dùng dữ liệu do khách hàng gửi qua API để đào tạo mô hình hay cải thiện dịch vụ của họ.
Thiết lập môi trường
Tạo môi trường ảo Python mới. Điều này sẽ đảm bảo không có xung đột phiên bản thư viện. Sau đó, chạy lệnh terminal sau để cài các library được yêu cầu.
pip install langchain openai tiktoken faiss-cpu pypdfCụ thể cách dùng từng library như sau:
- LangChain: Bạn sẽ dùng nó để tạo và quản lý các chuỗi ngôn ngữ cho việc phân tích và xử lý văn bản. Nó sẽ cung cấp mô đun cho việc tải tài liệu, chia tách văn bản, nhúng và lưu trữ vector.
- OpenAI: Bạn sẽ dùng nó cho việc chạy các truy vấn và thu kết quả từ một mô hình ngôn ngữ.
- Tiktoken: Bạn sẽ dùng nó để đếm số token (đơn vị text) trong một văn bản cụ thể. Điều này giúp bạn theo dõi số lượng token khi tương tác với OpenAPI mà tính phí dựa trên số lượng token bạn sử dụng.
- FAISS: Bạn sẽ dùng nso để tạo và quản lý cửa hàng vector, cho phép truy xuất nhanh các vector tương tự dựa trên phần nhúng của chúng.
- PyPDF: Library truy xuất văn bản từ PDF. Nó giúp tải file PDF và truy xuất nội dung của chúng để xử lý sâu hơn.
Sau khi tất cả thư viện đã được cài đặt, môi trường của bạn giờ đã sẵn sàng.
Lấy khóa OpenAI API
Khi tạo truy vấn cho OpenAI API, bạn cần bao gồm một khóa API như một phần của truy vấn này. Khóa này cho phép nhà cung cấp API xác minh rằng các truy vấn đến từ một nguồn hợp pháp và bạn có quyền cần thiết để truy cập những tính năng đó.
Để lấy khóa OpenAI API, hãy chuyển sang nền tảng OpenAI.
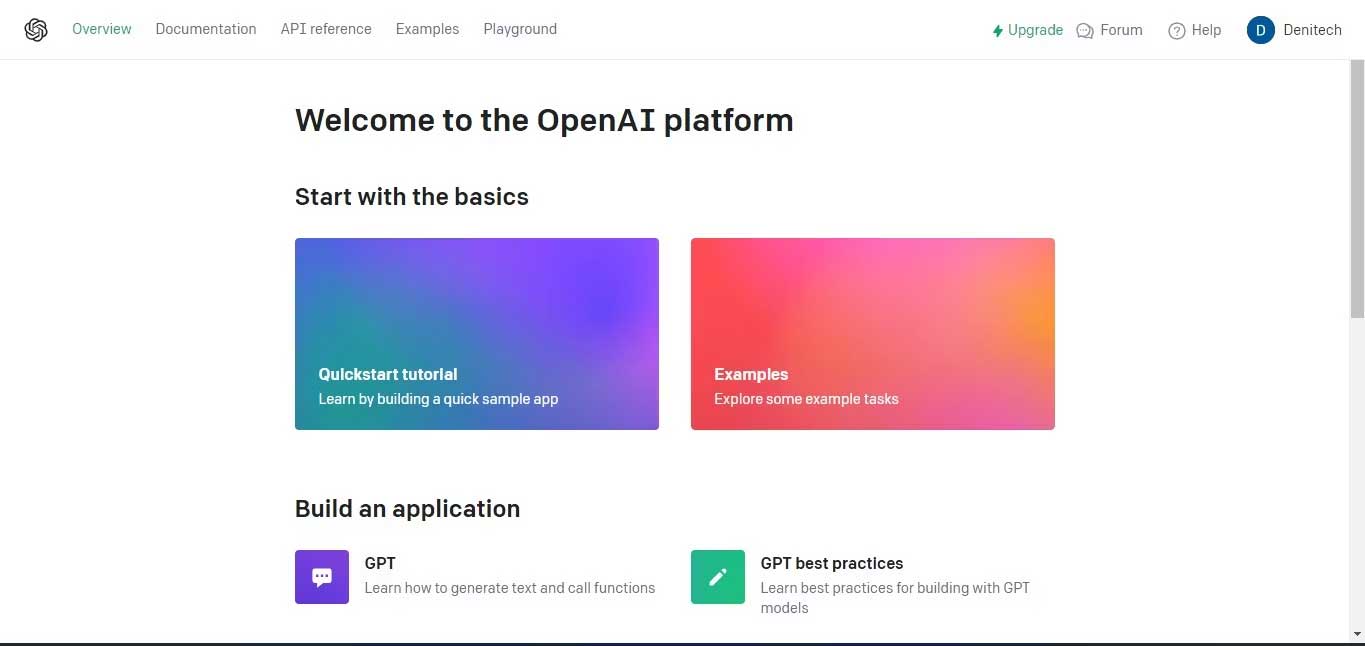
Sau đó, bên dưới profile của tài khoản ở góc phải phía trên cùng, click các khóa View API. Trang khóa API này sẽ hiện.
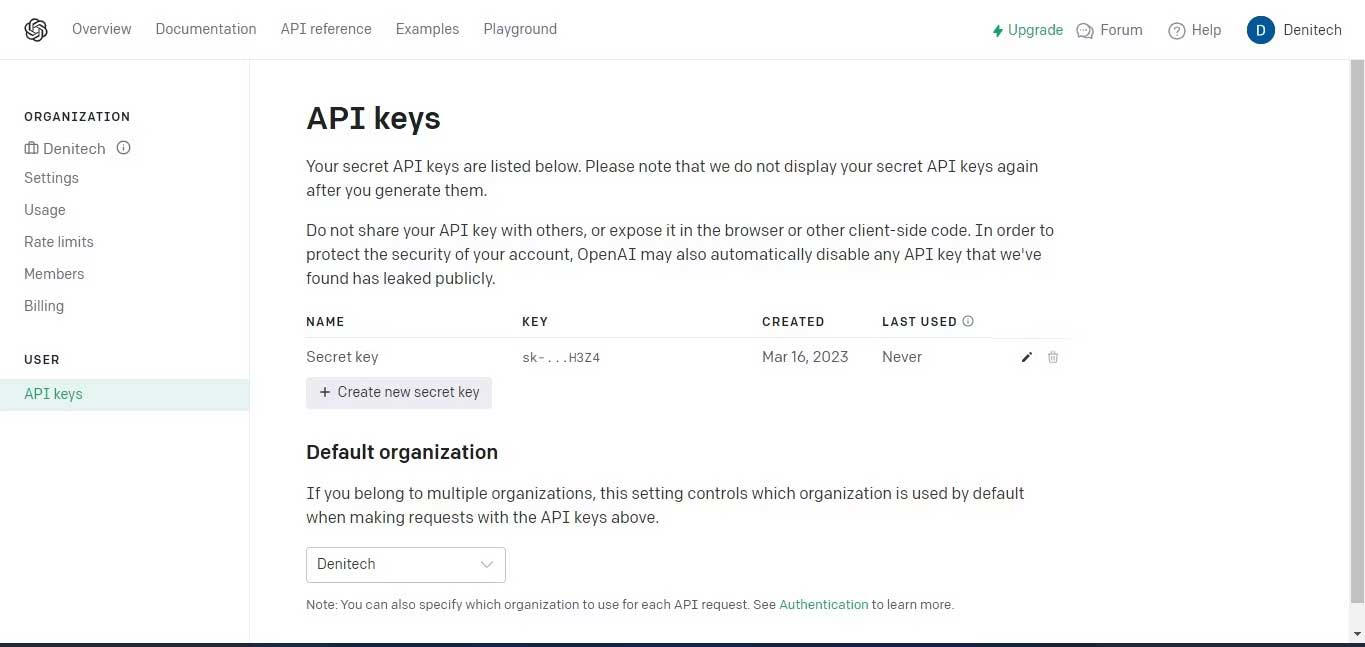
Click nút Create new secret key. Đặt tên khóa và click Create new secret key. OpenAI sẽ tạo khóa API mà bạn nên sao chép và lưu giữ chúng ở một nơi an toàn. Vì mục đích bảo mật, bạn sẽ không thể xem lại nó qua tài khoản OpenAI. Nếu mất khóa bí mật này, bạn cần tạo mới.
Nhập các thư viện cần thiết
Để có thể dùng những library được cài trong môi trường ảo, bạn cần nhập chúng.
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.llms import OpenAILưu ý rằng bạn nhập các library phụ thuộc từ LangChain. Điều này cho phép bạn dùng các tính năng cụ thể của framework LangChain.
Tải tài liệu để phân tích
Bắt đầu bằng cách tạo một biến chứa khóa API. Bạn sẽ dùng biến này sau, trong code xác thực.
# Hardcoded API key
openai_api_key = "Your API key"Bạn không nên hard code khóa API nếu định lên kế hoạch chia sẻ code với bên thứ ba. Đối với code sản xuất nhằm mục đích phân phối, hãy dùng một biến môi trường thay thế.
Tiếp theo, tạo một hàm tải tài liệu. Hàm này cần tải một PDF hoặc file văn bản. Nếu không có tài liệu, hàm này sẽ hiện ValueError.
def load_document(filename):
if filename.endswith(".pdf"):
loader = PyPDFLoader(filename)
documents = loader.load()
elif filename.endswith(".txt"):
loader = TextLoader(filename)
documents = loader.load()
else:
raise ValueError("Invalid file type")Sau khi tải tài liệu, tạo CharacterTextSplitter. Nó sẽ chia tài liệu được tải thành các phần nhỏ hơn dựa trên ký tự.
text_splitter = CharacterTextSplitter(chunk_size=1000,
chunk_overlap=30, separator="\n")
return text_splitter.split_documents(documents=documents)
Chia nhỏ tài liệu đảm bảo các phần có kích thước dễ quản lý và vẫn được kết nối với một số bối cảnh chồng chéo. Điều này hữu ích với những nhiệm vụ như phân tích văn bản và truy xuất thông tin.
Truy vấn tài liệu
Bạn cần một cách truy vấn tài liệu đã upload để lấy chi tiết từ nó. Làm việc này bằng cách tạo hàm nhận một chuỗi query và retriever làm đầu vào. Sau đó, nó sẽ tạo phiên bản RetrievalQA bằng retriever cùng một phiên bản của mô hình ngôn ngữ OpenAI.
def query_pdf(query, retriever):
qa = RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),
chain_type="stuff", retriever=retriever)
result = qa.run(query)
print(result)Hàm này dùng phiên bản QA đã tạo để chạy truy vấn và in kết quả.
Tạo hàm chính
Hàm chính sẽ kiểm soát luồng chương trình tổng thể. Nó sẽ lấy thông tin đầu vào người dùng cho một filename tài liệu và tải tài liệu đó. Sau đó, tạo phiên bản OpenAIEmbeddings cho việc nhúng và xây dựng một vector store dựa trên tài liệu đã tải và embeddings. Lưu kho vector vào một file cục bộ.
Tiếp theo, tải vector store liên tục từ file cục bộ. Sau đó, nhập một loop tại nơi người dùng có thể nhập các truy vấn. Hàm main chuyển những truy vấn này vào hàm query_pdf cùng với trình truy vấn của vector store được duy trì. Vòng lặp này sẽ tiếp tục cho tới khi người dùng nhập “exit”.
def main():
filename = input("Enter the name of the document (.pdf or .txt):\n")
docs = load_document(filename)
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectorstore = FAISS.from_documents(docs, embeddings)
vectorstore.save_local("faiss_index_constitution")
persisted_vectorstore = FAISS.load_local("faiss_index_constitution", embeddings)
query = input("Type in your query (type 'exit' to quit):\n")
while query != "exit":
query_pdf(query, persisted_vectorstore.as_retriever())
query = input("Type in your query (type 'exit' to quit):\n")Phương pháp nhúng ghi lại các mối quan hệ ngữ nghĩa giữa các từ. Vector là một hình thức mà bạn có thể trình bày những đoạn văn bản.
Code này chuyển đổi dữ liệu text trong tài liệu thành các vector bằng việc nhúng được bởi OpenAIEmbeddings. Sau đó, nó đánh chỉ mục những vector này bằng FAISS, dành cho việc truy xuất và so sánh những vector giống nhau. Đây là những gì cho phép phân tích tài liệu được upload.
Cuối cùng, dùng the __name__ == "__main__" construct để gọi hàm chính nếu một người dùng chạy độc lập chương trình này:
if __name__ == "__main__":
main()App này là một ứng dụng dòng lệnh. Là một extension, bạn có thể dùng Streamlit để thêm giao diện web vào ứng dụng.
Triển khai phân tích tài liệu
Để triển khai phân tích tài liệu, lưu trữ tài liệu bạn muốn phân tích trong cùng thư mục với dự án của bạn, sau đó chạy chương trình này. Nó sẽ hỏi tên của tài liệu bạn muốn phân tích. Nhập tên đầy đủ, rồi nhập truy vấn cho chương trình phân tích.
Ảnh chụp màn hình bên dưới hiện kết quả phân tích một PDF:
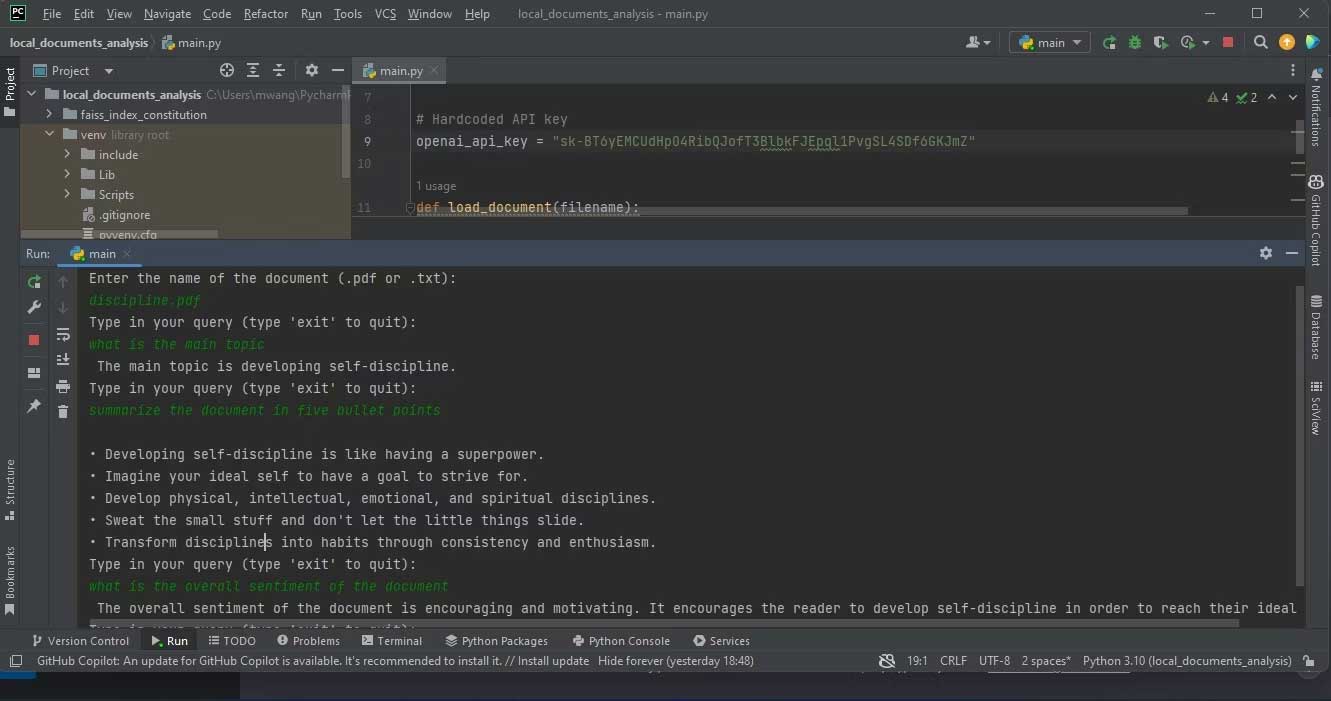
Ảnh dưới hiện kết quả phân tích file văn bản chứa code nguồn.
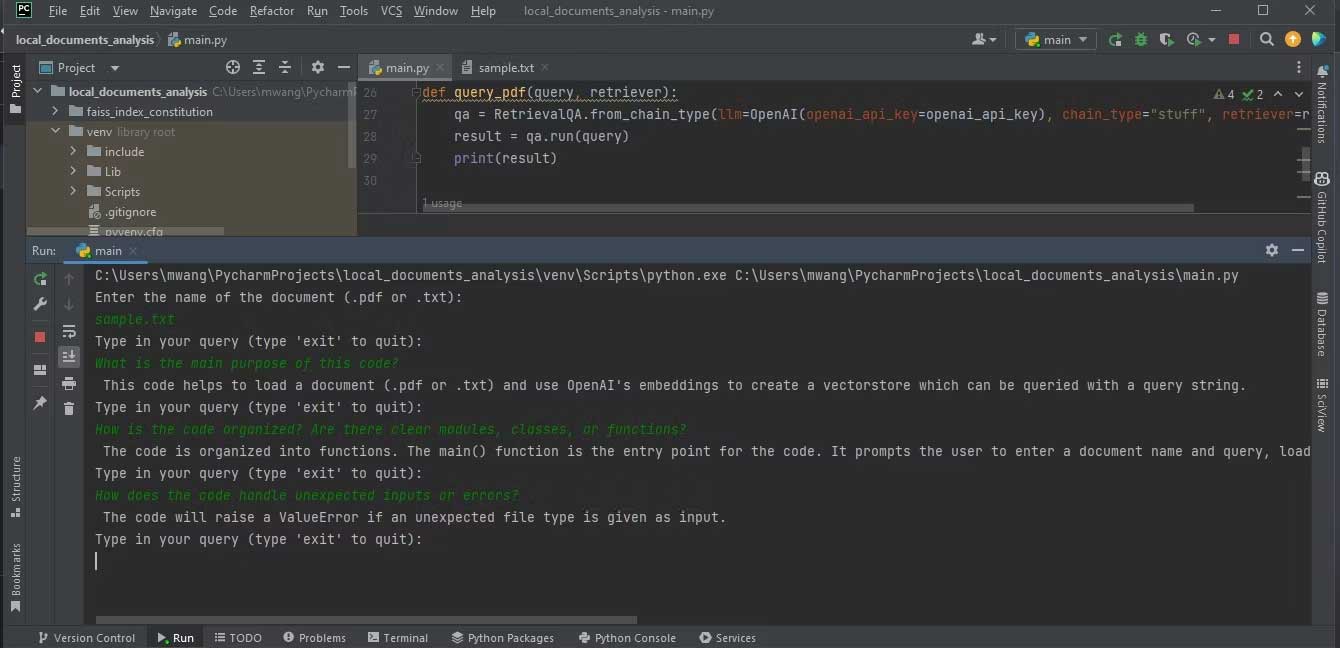
Đảm bảo file bạn muốn phân tích có định dạng PDF hoặc text. Nếu tài liệu ở định dạng khác, bạn có thể chuyển đổi chúng sang định dạng PDF bằng công cụ online.




 Lập trình
Lập trình
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học