 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích
Gabriel Torres
Trong hướng dẫn này, chúng tôi sẽ giới thiệu đến các bạn cách CPU Pentium M làm việc như thế nào dưới cách dễ hiểu nhất. Từ khi tất cả các CPU mới của Intel sử dụng kiến trúc Pentium M, việc nghiên cứu kiến trúc này là một việc quan trọng để từ đó bạn có thể hiểu sâu được kiến trúc của các CPU Core Solo hay Core Duo (Yonah) và cũng hiểu được lớp nền tảng cho việc tiến tới kiến trúc lõi siêu nhỏ (Core microarchitecture), được sử dụng bởi các CPU Merom, Conroe và Woodcrest. Trong hướng dẫn này, bạn sẽ biết được kiến trúc của nó làm việc thế nào để từ đó có thể so sánh được với các bộ vi xử lý khác đến từ Intel cũng như từ các đối thủ cạnh tranh khác như AMD.
Pentium M được xây dựng dựa trên kiến trúc thế hệ thứ 6 của Intel, cùng được sử dụng trong các CPU Pentium Pro, Pentium II và Pentium III, tuy nhiên lại không trên Pentium 4 như nhiều bạn nghĩ, mục đích của nó nhằm vào các máy tính di động. Bạn có thể nghĩ Pentium M như một Pentium III được nâng cao. Nhưng cần chú ý để không nhầm lẫn Pentium M với Pentium III. Trong một bài khác chúng tôi sẽ giới thiệu cho các bạn về tất cả các Model của Pentium M đã được phát hành cho đến thời điểm hiện nay.
Đôi khi Pentium M còn được gọi là Centrino. Quả thực nó có thể được gọi như vậy khi bạn có một laptop CPU Pentium M, chipset Intel 855 hay 915 và Intel/PRO wireless LAN. Chính vì vậy nếu bạn có một laptop được xây dựng trên Pentium M mà không có những điều kiện bổ sung như trên thì không thể được coi là Centrino.
Trong hướng dẫn này chúng tôi sẽ giới thiệu cơ bản cho các bạn về cách kiến trúc P6 làm việc như thế nào và những điểm gì mới khi so sánh Pentium M với Pentium III. Cũng vì vậy mà trong hướng dẫn này bạn sẽ biết thêm được về cách làm việc của các CPU Pentium Pro, Pentium II, Pentium III và Celeron (chúng cũng chính là các mô hình dựa trên P6, nghĩa là slot 1 và socket 370).
Trong bài này, chúng tôi sẽ không giới thiệu một cách cơ bản về cách làm việc của các CPU, để tìm hiểu thêm bạn có thể đọc bài này. Trong hướng dẫn này, chúng tôi thừa nhận rằng bạn đã có một chút kiến thức về cách làm việc của các CPU.
Trước khi tiếp tục, chúng ta hãy xem xét đến sự khác nhau giữa các CPU Pentium M và Pentium III:
Nhìn bên ngoài, Pentium M làm việc giống như Pentium 4, truyền tải 4 dữ liệu trên một chu kỳ clock. Kỹ thuật này được gọi là QDR (Quad Data Rate – Gấp bốn lần tốc độ dữ liệu) và làm cho bus nội bộ có hiệu suất tăng gấp 4 lần với tốc độ clock thực của nó, bạn có thể xem bảng dưới đây.
| Clock thực | Hiệu suất | Tốc độ truyền |
|
100 MHz |
400 MHz |
3.2 GB/s |
|
133 MHz |
533 MHz |
4.2 GB/s |
-
L1 memory cache: Hai L1 memory cache 32 KB, một cho dữ liệu và một cho chỉ lệnh (Pentium III có hai L1 memory cache16 KB).
-
L2 memory cache: 1 MB trên các mô hình 130 nm (lõi “Banias”) hay 2 MB trên các mô hình 90 nm (lõi “Dothan”). Pentium II chỉ có đến 512 KB. Celeron M, phiên bản rẻ tiền nhất của Pentium M cũng có 512 KB L2 memory cache. Hỗ trợ cho các chỉ lệnh SSE2.
-
Dự báo nhánh cao cấp: Dự báo nhánh đã được thiết kế lại (và được dựa trên mạch của Pentium 4) để cải thiện hiệu suất.
-
Sự hợp nhất nhiều hoạt động nhỏ: Bộ giải mã chỉ lệnh hợp nhất được hai hành động nhỏ thành một để có thể tiết kiệm được năng lượng và cải thiện hiệu suất. Chúng ta sẽ nói kỹ hơn về vấn đề này ở phần dưới.
-
Công nghệ SpeedStep nâng cao, đây là công nghệ cho phép các CPU có thể giảm được clock trong chế độ nhàn rỗi để tiết kiệm thời gian sống của pin. Một số tính năng nhằm tiết kiệm cho pin cũng đã được bổ sung vào kiến trúc siêu nhỏ của Pentium M, vì mục đích của các CPU này ban đầu được thiết kế cho máy tính di động.
Bây giờ chúng ta hãy đi xem xét sâu hơn về kiến trúc của Pentium M.
Nguyên lý của Pentium M
Nguyên lý là một danh sách tất cả các tầng mà chỉ lệnh đã cho phải được thực thi theo đúng thuật toán. Intel đã không tiết lộ các nguyên lý của Pentium M, chính vì vậy chúng tôi sẽ nói về nguyên lý của Pentium III. Nguyên lý của Pentium M có thể sẽ có nhiều tầng hơn so với Pentium III nhưng việc phân tích nó sẽ cho chúng ta có được ý tưởng về kiến trúc của Pentium M làm việc như thế nào.
Hãy nhớ rằng, nguyên lý làm việc của Pentium 4 có đến 20 tầng và nguyên lý làm việc của các CPU Pentium 4 mới hơn được dựa trên lõi “Prescott” có đến 31 tầng.
Trên hình 1 bạn có thể thấy được nguyên lý 11 tầng của Pentium III
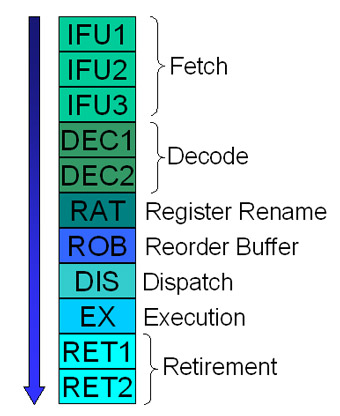
Hình 1: Nguyên lý của Pentium III
Dưới đây chúng tôi sẽ giải thích một cách cơ bản về mỗi tầng, giải thích sẽ làm sáng tỏ cách mỗi chỉ lệnh được gán được thực hiện như thế nào bởi các bộ vi xử lý lớp P6. Điều này sẽ không quá phức tạp như bạn nghĩ. Đây chỉ là tóm tắt và những giải thích cụ thể dễ hiểu sẽ được chúng tôi đưa ra bên dưới.
-
IFU1: Nạp một dòng (32 byte tương đương với 256 bit) từ chỉ lệnh L1 cache và lưu nó vào trong bộ đệm luồng chỉ lệnh (Instruction Streaming Buffer).
-
IFU2: Nhận dạng các chỉ lệnh đường biên (16byte tương đương với 128bit). Vì các chỉ lệnh x86 không có một chiều dài cố định nên tầng này đánh dấu vị trí mà mỗi chỉ lệnh bắt đầu và kết thúc bên trong 16byte đã được nạp. Nếu có bất kỳ nhánh nào bên trong 16byte thì địa chỉ có nó sẽ được lưu tại Branch Target Buffer (BTB), chính vì vậy CPU có thể sử dụng những thông tin này sau trên mạnh tiên đoán nhánh của nó.
-
IFU3: Đánh dấu đơn vị giải mã chỉ lệnh của mỗi chỉ lệnh phải được gửi. Có ba khối giải mã chỉ lệnh khác nhau mà chúng ta sẽ đề cập đến chúng trong phần dưới.
-
DEC1: Giải mã chỉ lệnh x86 thành những chỉ lệnh nhỏ RISC (các hoạt động nhỏ). Vì CPU có đến 3 bộ giải mã chỉ lệnh nên nó có thể giải mã được đến 3 chỉ lệnh cùng lúc.
-
DEC2: Gửi các chỉ lệnh nhỏ vừa được giải mã vào hàng đợi chỉ lệnh đã giải mã (Decoded Instruction Queue), hàng đợi này có khả năng lưu trữ được đến 6 chỉ lệnh nhỏ. Nếu chỉ lệnh đã được chuyển đổi nhiều hơn 6 chỉ lệnh nhỏ thì tầng này cần phải được lặp lại để không bỏ sót chúng.
-
RAT: Vì kiến trúc P6 thực hiện việc thi hành out-of-order (không tuân theo thứ tự, viết tắt là OOO), nên giá trị của thanh ghi đã cho có thể được thay đổi bởi một chỉ lệnh được thực thi trước vị trí chương trình diễn ra, sửa dữ liệu cần thiết cho chỉ lệnh khác. Chính vì vậy để giải quyết được kiểu xung đột này, tại tầng này, thanh ghi gốc được sử dụng bởi chỉ lệnh sẽ được thay đổi thành 40 thanh ghi bên trong mà kiến trúc siêu nhỏ mà P6 có.
-
ROB: Tại tầng này, ba chỉ lệnh nhỏ được giải mã sẽ nạp vào Reorder Buffer (ROB). Nếu tất cả dữ liệu đều cần thiết cho việc thực thi của một chỉ lệnh nhỏ đã được cung cấp và nếu có một khe mở tại hàng đợi chỉ lệnh đã giải mã Reservation Station thì chỉ lệnh này sẽ được chuyển vào hàng đợi này.
-
DIS: Nếu chỉ lệnh đã giải mã này lại không được gửi đến hàng đợi trên thì nó có thể được thực hiện tại tầng này. Chỉ lệnh giải mã sẽ được gửi đến khối thực thi thích hợp.
-
EX: Chỉ lệnh được giải mã sẽ được thực thi tại khối thực thi này. Mỗi một chỉ lệnh đã giải mã này chỉ cần một chu kỳ xung nhịp để được thực thi.
-
RET1: Kiểm tra tại bộ đệm Reorder Buffer xem có bất kỳ chỉ lệnh đã giải mã nào được đánh dấu như “đã thực thi” không.
-
RET2: Khi tất cả các chỉ lệnh đã giải mã có liên quan đến chỉ lệnh x86 thực sự đã được xóa hết khỏi bộ đệm Reorder Buffer và tất cả các chỉ lệnh nhỏ (đã được giải mã) có liên quan với chỉ lệnh x86 hiện hành đã được thực thi, thì các chỉ lệnh này sẽ được xóa khỏi bộ đệm Reorder Buffer và các thanh ghi x86 sẽ được nâng cấp (tiến trình được quay trở về tầng RAT). Tiến trình trở lại làm việc phải được thực hiện theo thứ tự. Ba chỉ lệnh đã giải mã có thể được xóa khỏi bộ đệm Reorder Buffer trong mỗi một chu kỳ clock.
Dưới đây chúng tôi sẽ giới thệu các thông tin chi tiết hơn để các bạn dễ hiểu được hoạt động của nó.
Memory Cache và Khối tìm nạp
Nhưng chúng tôi đã đề cập từ trước, L2 memory cache của Pentium M có thể là 1 MB trên các mô hình 130 nm (lõi “Banias”) hay 2 MB trên các mô hình 90 nm (lõi “Dothan”). Trong khi đó nó có hai memory cache L1, một cái là 32KB cho chỉ lệnh và cái kia là 32KB cho dữ liệu.
Như đã giải thích ở phần trước, khối tìm nạp được chia thành 3 tầng. Trong hình 2, bạn có thể xem được cách khối tìm nạp làm việc như thế nào.
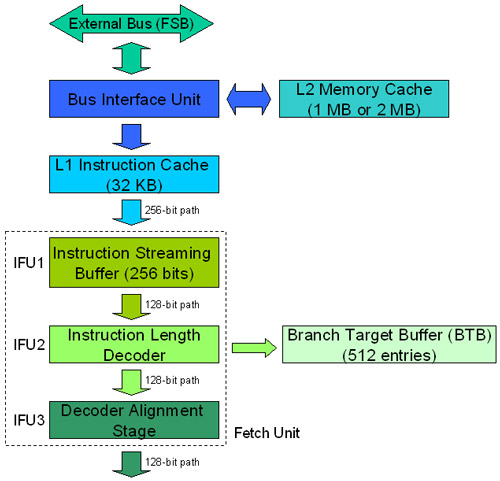
Hình 2: Khối tìm nạp
Khối tìm nạp nạp dòng thứ nhất (32 bytes = 256 bits) vào bộ đệm luồng chỉ lệnh của nó (Instruction Streaming Buffer). Sau đó bộ giải mã chiều dài chỉ lệnh sẽ nhận ra các ranh giới chỉ lệnh bên trong mỗi 16byte. Vì chỉ lệnh x86 không có chiều dài cố định nên tầng này sẽ đánh dấu vị trí mỗi chỉ lệnh bắt đầu và kết thúc bên trong 128bit đã được nạp. Nếu có một chỉ lệnh nhánh nào đó bên trong 128 bit đó thì địa chỉ sẽ được lưu vào Branch Target Buffer (BTB), chính vì vậy CPU của bạn có thể sử dụng các thông tin này sau trên mạnh dự báo nhánh của nó. BTB có 512 đầu vào.
Sau khi tầng Decoder Alignment Stage đánh dấu khối giải mã chỉ lệnh nào thì mỗi chỉ lệnh sẽ được gửi đi. Có 3 khối giải mã chỉ lệnh khác nhau mà chúng tôi sẽ giới thiệu ở phần dưới đây.
Giải mã chỉ lệnh và thay đổi tên cho thanh ghi
Vì kiến trúc P6 sử dụng cho các bộ vi xử lý Pentium Pro kiến trúc CISC/RISC lai nên bộ vi xử lý phải chấp nhận các chỉ lệnh CISC và cũng được biết đến với tư cách là các chỉ lệnh x86, điều này là do tất cả các phần mềm cung cấp ngày nay đều được viết bằng kiểu chỉ lệnh này. CPU chỉ sử dụng RISC không phải là tạo ra cho máy tính, vì nó không chạy phần mềm hiện nay như Windows và Office.
Vì vậy, giải pháp được sử dụng bởi tất cả các bộ vi xử lý hiện đang cung cấp trên thị trường ngay nay từ cả Intel và AMD là đều sử dụng giải mã CISC/RISC. Bên trong, CPU xử lý các chỉ lệnh RISC nhưng front-end của nó lại chỉ chấp nhận các chỉ lệnh CISC x86.
Các chỉ lệnh CISC x86 được đề cập đến như chỉ lệnh thông thường còn các chỉ lệnh RISC bên trong được đề cập đến như các chỉ lệnh đã được giải mã.
Mặc dù vậy, các chỉ lệnh đã được giải mã RISC không thể được truy cập một cách trực tiếp, do đó chúng ta không thể tạo phần mềm dựa trên các chỉ lệnh này để vòng tránh qua bộ giải mã. Cũng vậy, mỗi CPU sử dụng các chỉ lệnh RISC của riêng nó, các chỉ lệnh này không được công bố và không tương thích với chỉ lệnh đã giải mã từ các CPU khác. Điều đó có nghĩa là các chỉ lệnh đã giải mã của Pentium M khác hoàn toàn với chỉ lệnh đã giải mã của Pentium 4, sự khác biệt này chính là từ các chỉ lệnh giải mã Athlon 64.
Phụ thuộc vào độ phức tạp của chỉ lệnh x86 mà nó phải được chuyển thành các chỉ lệnh giải mã RISC.
Bộ giải mã chỉ lệnh Pentium M làm việc giống như trên hình 3. Như những gì bạn có thể quan sát thấy, có ba bộ giải mã và một bộ xếp dãy chỉ lệnh đã giải mã (MIS). Hai bộ giải mã được tối ưu hóa cho các chỉ lệnh đơn giản, trong đó các chỉ lệnh đơn giản là chỉ lệnh thường chỉ là một chỉ lệnh giải mã. Kiểu chỉ lệnh này được chuyển đổi như một chỉ lệnh giải mã. Một bộ giải mã được tối ưu hóa cho các chỉ lệnh x86 phức tạp, chỉ lệnh này có thể được chuyển đổi thành 4 chỉ lệnh đã giải mã. Nếu chỉ lệnh x86 quá phức tạp, có nghĩa là nó chuyển đổi tới hơn bốn chỉ lệnh giải mã thì nó sẽ được gửi đến MIS là bộ nhớ ROM, gồm có một danh sách các chỉ lệnh có thể được dùng để thay thế cho x86 trên.
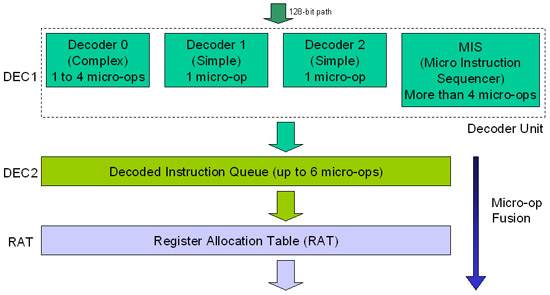
Hình 3: Bộ giải mã và đổi tên thanh ghi
Bộ giải mã chỉ lệnh có thể chuyển đổi lên đến 3 chỉ lệnh x86 trên mỗi một chu kỳ clock, một bộ giải mã phức tạp Decoder 0 và hai bộ giải mã đơn giản 1 và 2, điều này làm cho chúng ta có cảm giác hàng đợi chỉ lệnh đã được giải mã (Decoded Instruction Queue) có thể lên đến 6 chỉ lệnh giải mã trên mỗi chu kỳ clock, kịch bản có thể khi Decoder 0 gửi 4 chỉ lệnh đã giải mã và hai bộ giải mã kia gửi mỗi bộ một chỉ lệnh đã được giải mã – hoặc khi MIS được sử dụng. Các chỉ lệnh x86 phức tạp sử dụng (MIS) Micro Instruction Sequencer có thể dữ chậm một số chu kỳ clock khi giải mã, điều đó phụ thuộc vào số lượng chỉ lệnh được giải mã sẽ tạo ra từ sự chuyển đổi. Bạn cần nên lưu ý rằng Decoded Instruction Queue chỉ có thể giữ được đến 6 chỉ lệnh đã giải mã, chính vì vậy nếu có hơn 6 chỉ lệnh giải mã được sinh ra bởi bộ giải mã cộng với MIS thì một chu kỳ khác sẽ được sử dụng để gửi các chỉ lệnh hiện hành trong hàng đợi tới Register Allocation Table (RAT), làm trống hàng đợi và chấp nhận các chỉ lệnh đã giải mã mà không phù hợp với nó trước đó.
Pentium M sử dụng một khái niệm mới đối với kiến trúc P6, khái niệm này được gọi là hợp nhất chỉ lệnh giải mã. Trên Pentium M, mỗi một bộ giải mã nối hai chỉ lệnh đã giải mã thành một. Chúng sẽ chỉ được tách ra khi được thực thi, tại tầng thực thi.
Trên kiến trúc P6, mỗi chỉ lệnh có chiều dài 118 bit. Pentium M thay vì làm việc với các chỉ lệnh 118bit, nó làm việc với các chỉ lệnh có chiều dài 236bit mà chính là kích thước nối của hai chỉ lệnh 118bit.
Bạn cần phải lưu ý rằng các chỉ lệnh đã giải mã liên tục có chiều dài là 118bit, còn những gì được thay đổi là chúng được truyền tải thành một nhóm gồm hai chỉ lệnh cơ bản này.
Ý tưởng đằng sau phương pháp này là để tiết kiệm năng lượng và tăng hiệu suất. Việc gửi một chỉ lệnh có kích thước 236bit dài sẽ nhanh hơn việc gửi hai chỉ lệnh 118bit. Thêm vào đó, CPU sẽ tiêu tốn ít nguồn điện hơn vì sẽ có ít chỉ lệnh đã giải mã lưu thông bên trong nó.
Các chỉ lệnh được gắn sau đó sẽ gửi đến bảng Register Allocation Table (RAT). Kiến trúc CISC x86 chỉ có 8 thanh ghi 32bit đó là EAX, EBX, ECX, EDX, EBP, ESI, EDI và ESP. Số lượng này là quá thấp vì các CPU hiện đại có thể thực thi mã out-of-order, và nó sẽ “phá hỏng” nội dung bên trong thanh ghi đã có, từ đó gây ra hỏng các chương trình.
Chính vì vậy, tại tầng này, bộ vi xử lý thay đổi tên và nội dung của các thanh ghi đã được sử dụng bởi chương trình thành một trong 40 thanh ghi bên trong đã có (mỗi một thanh ghi này có 80 bit rộng, như vậy việc chấp nhận cả dữ liệu nguyên và dữ liệu thay đổi), cho phép chỉ lệnh có thể chạy tại cùng một thời điểm với chỉ lệnh khác mà sử dụng cũng cùng một thanh ghi chuẩn, hoặc thậm chí out-of-order, có nghĩa là cho phép chỉ lệnh thứ hai có thể chạy trước chỉ lệnh thứ nhất dù là chúng cùng chung trên một thanh ghi.
Bộ đệm Reorder Buffer
Khi các chỉ lệnh x86 và chỉ lệnh đã được giải mã có kết quả truyền tải giữ các tầng CPU theo cùng một thứ tự thì chúng sẽ xuất hiện trên chương trình đang chạy.
Khi vào ROB, các chỉ lệnh đã giải mã có thể được nạp và thực thi out-of-order bởi các khối thực thi. Sau khi thực thi, các chỉ lệnh được gửi trở lại về Reorder Buffer. Sau đó tại tầng cuối cùng (Retirement), các chỉ lệnh đã thực thi được xuất ra khỏi bộ đệm Reorder Buffer với cùng thứ tự mà chúng đã nạp vào, có nghĩa là chúng được chuyển theo thứ tự. Trên hình 4, bạn có thể có được ý tưởng vè cách chúng làm việc như thế nào.
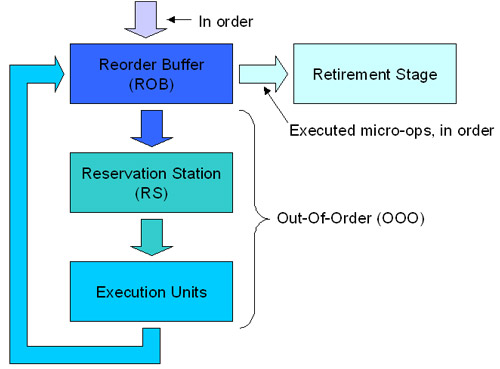
Hình 4: Cách làm việc của bộ đệm Reorder
Trên hình 4, chúng ta đã đơn giản hóa trạm dành riêng (Reservation Station) và các khối thực thi để có thể tạo sự dễ hiểu cho bộ đệm này. Chúng ta sẽ nói về hai tầng này sâu hơn nữa ở phần dưới.
Reservation Station và các khối thực thi
Như chúng ta đã đề cập từ trước, Pentium M sử dụng các chỉ lệnh được nối (thường là hai chỉ lệnh được nối với nhau) từ khối giải mã đến vị trí các cổng gửi đi được đặt trên Reservation Station. Reservation Station gửi đi các chỉ lệnh giải mã một cách riêng biệt (đã tách ghép đôi).
Pentium M có 5 cổng như vậy, các cổng này được đánh số từ 0 đến 4 trên Reservation Station. Mỗi cổng được kết nối đến một hoặc nhiều khối thực thi, các bạn có thể xem trên hình 5.
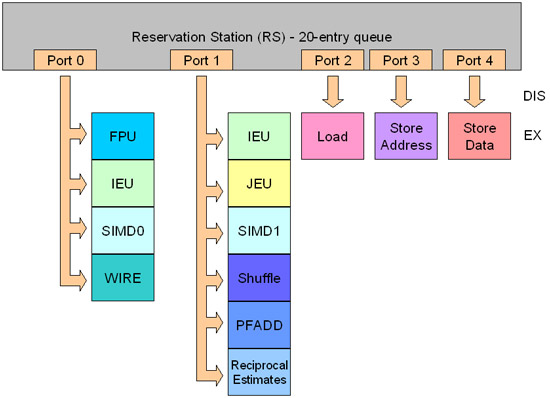
Hình 5: Reservation Station và các khối thực thi
Dưới đây là giải thích vắn tắt về mỗi khối thực thi có trên CPU này:
-
IEU: Instruction Execution Unit – Khối thực thi chỉ lệnh là nơi các chỉ lệnh thường được thực thi. Cũng được biết đến trong các sách giới thiệu về cấu trúc máy tính với tên ALU (Khối logic số học - Arithmetic and Logic Unit). Các chỉ lệnh thông thường này cũng được hiểu là các chỉ lệnh “integer”.
-
FPU: Floating Point Unit là nơi các chỉ lệnh toán học phức tạp được thực thi. Trước kia, khối này cũng có tên gọi là “math co-processor” – khối đồng xử lý toán học.
-
SIMD: là nơi các chỉ lệnh SIMD được thực thi, nghĩa là MMX, SSE và SSE2.
-
WIRE: Các hàm phức tạp
-
JEU: Jump Execution Unit xử lý các nhánh và cũng được biết đến là Branch Unit.
-
Shuffle: Khối này thực thi một loại chỉ lệnh của SSE có tên gọi là “shuffle”.
-
PFADD: Thực thi một chỉ lệnh SSE có tên gọi PFADD (Packed FP Add) và cả các chỉ lệnh COMPARE, SUBTRACT, MIN/MAX và CONVERT. Khối này được cung cấp riêng, chính vì vậy nó có thể bắt đầu việc thực thi một chỉ lệnh giải mã mới mỗi chu kỳ clock dù là nó không hoàn tất được sự thực thi của chỉ lệnh đã giải mã trước. Khối này có một độ trễ ba chu kỳ clock, nghĩa là nó sẽ giữ chậm 3 chu kỳ clock đối với mỗi chỉ lệnh đã được xử lý.
-
Reciprocal Estimates: Thực thi hai chỉ lệnh SSE, một được gọi là RCP (Reciprocal.Estimate) và một gọi là RSQRT (Reciprocal Square Root Estimate).
-
Load: Khối này dùng để xử lý các lệnh hỏi dữ liệu để được đọc từ bộ nhớ RAM.
-
Store Address: Khối xử lý các chỉ lệnh hỏi dữ liệu để được ghi tại bộ nhớ RAM. Khối này cũng có tên gọi là AGU, Address Generator Unit. Kiểu chỉ lệnh này sử dụng cả hai khối Store Address và Store Data tại cùng một thời điểm.
-
Store Data: Xử lý các chỉ lệnh hỏi dữ liệu để ghi vào bộ nhơ RAM. Loại chỉ lệnh này sử dụng cả hai khối Store Address và Store Data tại cùng một thời điểm.
Bạn cần phải nhớ rằng các chỉ lệnh phức tạp có thể mất đến vào chu kỳ clock để được xử lý. Chúng ta hãy lấy một ví dụ của cổng 0, nơi mà khối floating point unit (FPU) có mặt ở đó. Trong khi khối này đang xử lý một chỉ lệnh rất phức tạp, mất đến vài clock để thực thi thì cổng 0 sẽ không ngừng hoạt động: nó luôn luôn gửi các chỉ lệnh đơn giản đến IEU mặc dù khi đó FPU lại đang rất bận.
Chính vì vậy, mặc dù tốc độ gửi đi lớn nhất là 5 chỉ lệnh giải mã trên mỗi một chu kỳ clock, nhưng thực tế CPU có thể tăng lên đến 12 chỉ lệnh giải mã tại cùng một thời điểm.
Như chúng tôi đã đề cập từ trước, các chỉ lệnh yêu cầu CPU để có thể đọc dữ liệu được lưu trữ tại địa chỉ RAM đã cho, Khối lưu trữ địa chỉ (Store Address Unit) và lưu trữ dữ liệu (Store Data Unit) được sử dụng tại cùng một thời điểm, một dùng cho định địa chỉ và một dùng cho đọc dữ liệu.
Đây là lý do tại sao cổng 0 và cổng 1 có nhiều khối thực thi. Nếu chú ý một chút thì bạn sẽ thấy được Intel đã đặt trên cùng một cổng cả khối “nhanh” và ít nhất cùng với một khối “chậm” (phức tạp). Chính vì vậy, trong khi khối phức tạp đang bận xử lý dữ liệu thì các khối khác có thể vẫn nhận các chỉ lệnh đã giải mã từ cổng gửi đi tương ứng của nó. Như chúng tôi đã đề cập trước, ý tưởng này là để giữ tất cả các khối thực thi luôn làm việc.
Như đã giải thích, sau mỗi một chỉ lệnh đã giải mã được thực thi, nó lại trở về bộ đệm Reorder Buffer, đây chính là nơi cờ của nó được thiết lập chế độ thực thi. Sau đó tại tầng cuối (Retirement Stage), các chỉ lệnh đã giải mã có cờ “thực thi” của chúng sẽ được xóa khỏi bộ đệm Reorder Buffer theo thứ tự ban đầu của nó (nghĩa là theo thứ tự mà chúng đã được giải mã) và sau đó các thanh ghi x86 được cập nhật (ngược lại bước của tầng đặt lại tên của thanh ghi). Có thể có đến 3 chỉ lệnh giải mã được xóa bỏ từ bộ đệm Reorder Buffer trên mỗi một chu kỳ clock. Sau đó, mỗi chỉ lệnh này được thực thi hoàn toàn.
Công nghệ SpeedStep nâng cao
Công nghệ SpeedStep đã được tạo ra để tăng thời gian sống của pin và nó đã được giới thiệu đầu tiên trong các bộ vi xử lý của Pentium III M. Phiên bản đầu tiên của công nghệ này cho phép các CPU có thể chuyển giữa hai tần số clock một cách động. Chế độ tần số thấp (LFM), chế độ cho phép thời lượng sống của pin lớn nhất, và chế độ tần số cao (HFM), chế độ cho phép chạy CPU tại tốc độ lớn nhất. CPU có hai tỉ lệ nhân clock. Tỉ lệnh LFM là tỉ lệnh factory-lock và bạn không thể thay đổi được tỉ lệ này.
Pentium M đã giới thiệu công nghệ SpeedStep nâng cao (Enhanced SpeedStep Technology), công nghệ này là công nghệ có một vài cấu hình clock và điện áp khác giữa LFM (cố định là 600 MHz) và HFM.
Một ví dụ để các bạn có thể dễ hiểu hơn trong trường hợp này, bảng cấu hình clock và điện áp cho 1.6 GHz Pentium M dựa trên công nghệ 130nm:
| Điện áp | Clock |
| 1.484 V | 1.6 GHz |
| 1.42 V | 1.4 GHz |
| 1.276 V | 1.2 GHz |
| 1.164 V | 1 GHz |
| 1.036 V | 800 MHz |
| 0.956 V | 600 MHz |
Mỗi một mô hình của Pentium M lại có một bảng điện áp/clock của riêng nó. Bạn cần phải chú ý một điều rằng khi không cần tốn nhiều năng lương đối với laptop thì không những chỉ giảm tốc độ clock mà còn giảm cả điện áp, việc giảm điện áp sẽ giúp giảm tiêu tốn rất nhiều pin máy.
Công nghệ Enhanced SpeedStep làm việc bằng cách kiểm tra các thanh ghi model cụ thể MSR (Model Specific Registers) của CPU, thành phần này được gọi là Performance Counter. Với thông tin thu nhận từ bộ phận này, CPU có thể giảm hoặc tăng clock/điện áp của nó phụ thuộc vào khả năng sử dụng của CPU. Đơn giản nếu bạn tăng yêu cầu sử dụng CPU thì nó sẽ tăng clock/điện áp còn nếu bạn giảm hiệu suất sử dụng CPU thì nó sẽ giảm clock/điện áp.
Enhanced SpeedStep chỉ là một trong những nâng cao đã được thực hiện với kiến trúc siêu nhỏ Pentium M nhằm mục đích tăng thời lượng sử dụng của pin.






 Làng Công nghệ
Làng Công nghệ
 Chuyện công nghệ
Chuyện công nghệ
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học