 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Microsoft Research mới đây đã khiến giới nghiên cứu trí tuệ nhân tạo (AI) xôn xao khi công bố phát triển thành công DeepSpeed, một thư viện tối ưu hóa deep learning có thể được sử dụng để đào tạo các mô hình AI khổng lồ với quy mô lên tới 100 tỷ tham số.
Trong đào tạo AI, nếu bạn sở hữu các mô hình ngôn ngữ tự nhiên càng lớn thì độ chính xác sẽ càng cao. Tuy nhiên việc đào tạo các mô hình ngôn ngữ tự nhiên lớn tiêu tốn cực nhiều thời gian, và chi phí liên quan cũng không hề nhỏ. DeepSpeed được ra đời để khắc phục toàn bộ những khó khăn trên: Cải thiện tốc độ, chi phí, quy mô đào tạo và khả năng sử dụng.
Ngoài ra, Microsoft cũng đề cập đến việc DeepSpeed còn bao gồm cả ZeRO (Zero Redundancy Optimizer), một kỹ thuật tối ưu hóa song song giúp giảm thiểu lượng tài nguyên cần thiết cho các mô hình, trong khi vẫn giúp nâng cao lượng tham số có thể được đào tạo. Bằng việc sử dụng kết hợp giữa DeepSpeed và ZeRO, các nhà nghiên cứu của Microsoft đã có thể phát triển thành công mô hình Turing Natural Language Generation (Turing-NLG) mới - mô hình ngôn ngữ lớn nhất hiện nay với 17 tỷ tham số.
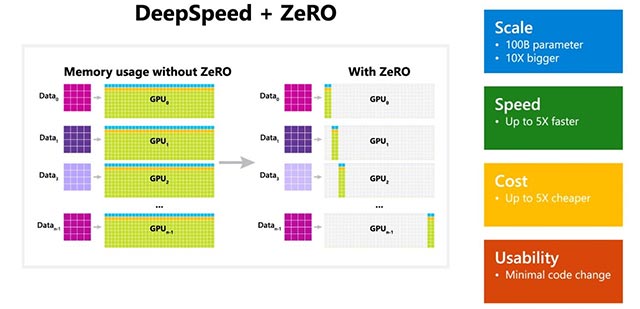
Một số điểm nổi bật của DeepSpeed:
- Quy mô: Các mô hình AI lớn, tiên tiến hiện nay như OpenAI GPT-2, NVIDIA Megatron-LM và Google T5 có quy mô lần lượt là 1,5 tỷ, 8,3 tỷ và 11 tỷ tham số. ZeRO giai đoạn 1 trong DeepSpeed có thể cung cấp khả năng hỗ trợ hệ thống để chạy các mô hình lên tới 100 tỷ tham số, tức là lớn hơn 10 lần so với mô hình lớn nhất của Google.
- Tốc độ: Thông lượng được ghi nhận sẽ có mức tăng khác nhau tùy theo cấu hình phần cứng. Trên các cụm GPU NVIDIA có kết nối băng thông thấp (không có NVIDIA NVLink hoặc Infiniband), DeepSpeed đạt được sự cải thiện thông lượng gấp 3,75 lần so với chỉ sử dụng Megatron-LM cho mô hình GPT-2 tiêu chuẩn với 1,5 tỷ tham số. Trên cụm NVIDIA DGX-2 có kết nối băng thông cao, đối với các mẫu sở hữu từ 20 đến 80 tỷ tham số, DeepSpeed nhanh hơn từ 3 đến 5 lần.
- Chi phí: Từ những cải thiện về tốc độ, chi phí đào tạo cũng được tối ưu đáng kể. Ví dụ, để đào tạo một mô hình với 20 tỷ tham số, DeepSpeed yêu cầu lượng tài nguyên ít hơn 3 lần so với thông thường.
- Tính khả dụng: Chỉ cần một vài thay đổi nhỏ liên quan đến code để là các mô hình hiện hành có thể chuyển sang sử dụng DeepSpeed và ZeRO. DeepSpeed không yêu cầu thiết kế lại code hoặc tái cấu trúc mô hình.
Microsoft đang mở nguồn cho cả DeepSpeed và ZeRO trên GitHub, mời bạn tham khảo.






 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học