 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Google đã bước vào "kỷ nguyên Gemini" được vài năm nay, và trong khi việc đổi tên gây nhầm lẫn đã chậm lại, mọi thứ khác vẫn tiếp tục được cải thiện với tốc độ nhanh chóng. Gemini là tên mà Google đặt cho thế hệ mô hình AI đa phương thức hiện tại của mình, nhưng theo phong cách điển hình của Google, nó cũng áp dụng cho hầu hết mọi thứ khác liên quan đến AI.
Google có:
- Google Gemini, một dòng mô hình AI đa phương thức. Phiên bản mới nhất là Gemini 3 Pro, mặc dù một số mô hình cũ hơn vẫn còn được sử dụng. Đây là những gì Google sử dụng trong các ứng dụng của riêng mình và để cung cấp năng lượng cho những tính năng AI trên thiết bị của họ, nhưng các nhà phát triển cũng có thể tích hợp nó vào ứng dụng của họ.
- Google Gemini, một chatbot chạy trên dòng mô hình Gemini. (Chatbot này trước đây có tên là Bard).
- Google Gemini, một sự thay thế cho Google Assistant đang được triển khai trên điện thoại thông minh Android, đồng hồ Android Wear, Android Auto và Google TV.
- Gemini for Google Workspace, các tính năng AI được tích hợp trên Gmail, Google Docs và những ứng dụng Workspace khác dành cho người dùng trả phí.
Tất cả các sản phẩm Gemini mới này đều dựa trên nền tảng cốt lõi của những mô hình AI đa phương thức, vậy nên hãy bắt đầu từ đó!
Google Gemini là gì?
Google Gemini là một họ các mô hình AI, giống như GPT của OpenAI. Chúng đều là các mô hình đa phương thức, nghĩa là chúng có thể hiểu và tạo ra văn bản giống như một mô hình ngôn ngữ lớn (LLM) thông thường, nhưng chúng cũng có thể hiểu, xử lý và kết hợp các loại thông tin khác như hình ảnh, âm thanh, video và code.

Ví dụ, bạn có thể đưa cho Gemini một câu hỏi như "Điều gì đang xảy ra trong bức ảnh này?" và đính kèm một hình ảnh, nó sẽ mô tả hình ảnh và phản hồi các câu hỏi tiếp theo yêu cầu thông tin phức tạp hơn. Tương tự, nếu bạn cung cấp cho nó một lượng lớn dữ liệu, nó có thể tạo ra biểu đồ hoặc hình ảnh trực quan khác; hoặc nó có thể giúp bạn giải thích biểu đồ, đọc biển báo hoặc dịch thực đơn.
Vì hiện nay chúng ta đang ở trong kỷ nguyên cạnh tranh khốc liệt của AI trong doanh nghiệp, hầu hết các công ty đều khá kín tiếng về những chi tiết cụ thể về cách thức hoạt động và sự khác biệt trong các mô hình của họ. Tuy nhiên, Google đã xác nhận rằng các mô hình Gemini sử dụng kiến trúc Transformer và dựa vào những chiến lược như huấn luyện trước và tinh chỉnh, giống như các mô hình AI lớn khác. Các mô hình Gemini lớn hơn cũng đã chuyển sang phương pháp Mixture-of-Experts, cho phép chúng hoạt động hiệu quả hơn với số lượng tham số lớn hơn.
Các mô hình Gemini mới nhất đáp ứng đầy đủ những tiêu chuẩn hiện đại. Mặc dù các dòng mô hình khác đã bắt kịp, Google đã tiên phong trong việc tạo ra cửa sổ ngữ cảnh dài với Gemini. Điều này nghĩa là một câu hỏi có thể bao gồm nhiều thông tin hơn để định hình tốt hơn các phản hồi mà mô hình có thể đưa ra và các tài nguyên mà nó có để làm việc. Hiện tại, mọi mô hình hiện tại trong dòng Gemini đều có ít nhất một triệu token trong cửa sổ ngữ cảnh. Điều đó đủ cho nhiều tài liệu dài, cơ sở tri thức lớn và các tài nguyên nặng về văn bản khác. Nếu phải phân tích một hợp đồng phức tạp, bạn có thể upload toàn bộ tài liệu lên Gemini và đặt câu hỏi về nó - bất kể độ dài ra sao. Điều này cũng hữu ích nếu bạn đang xây dựng một pipeline RAG, mặc dù chi phí API sẽ rất cao nếu bạn thực sự sử dụng toàn bộ cửa sổ ngữ cảnh trong môi trường sản xuất.
Tương tự, Google đã thêm khả năng suy luận vào các mô hình Gemini mới nhất, Gemini 3 Pro và Gemini 2.5 Flash. Điều này giúp chúng có khả năng giải quyết các vấn đề logic phức tạp, hiểu chính xác thông tin khoa học và tạo ra code lập trình. Điểm cuối cùng này đặc biệt quan trọng trong bối cảnh Vibe Coding đang ngày càng phổ biến. Trong thông báo về Gemini 3, Google nhấn mạnh cách Gemini 3 Pro và Gemini 3 Deep Think có thể được sử dụng để lập trình ứng dụng, tính năng và trực quan hóa dữ liệu.
Việc sử dụng công cụ và các tính năng agentic cũng là một phần quan trọng của những mô hình Gemini mới nhất. Điều này có phần khác biệt so với cách người dùng thông thường sử dụng những mô hình này trong chatbot, nhưng đối với các nhà phát triển và người dùng chuyên nghiệp, nó cho phép họ tạo ra những ứng dụng AI có thể thực hiện hành động độc lập.
Các mô hình Google Gemini có nhiều kích thước khác nhau
Các mô hình Gemini khác nhau được thiết kế để chạy trên hầu hết mọi thiết bị, đó là lý do tại sao Google tích hợp nó ở khắp mọi nơi. Google tuyên bố rằng các phiên bản khác nhau của họ có khả năng hoạt động hiệu quả trên mọi thứ, từ trung tâm dữ liệu đến điện thoại thông minh.
Mỗi mô hình Gemini khác nhau về số lượng tham số và do đó, khả năng xử lý các truy vấn phức tạp cũng như sức mạnh xử lý cần thiết để hoạt động cũng khác nhau. Thật không may, các thông số như số lượng tham số của bất kỳ phiên bản nào thường được giữ bí mật - trừ khi có lý do để công ty đó khoe khoang.
Hiện tại, Google có các mô hình Gemini sau - mặc dù điều này đang thay đổi nhanh chóng.
Gemini 3.5 Flash
Gemini 3.5 Flash là phiên bản Gemini mới nhất, và mặc dù mang nhãn hiệu "Flash", nó không nhằm mục đích trở thành một lựa chọn thay thế nhanh và rẻ cho phiên bản Pro. Nó là một phiên bản tiên tiến theo đúng nghĩa của nó. Nó có cửa sổ ngữ cảnh 1 triệu token, hỗ trợ suy luận và đạt điểm cao hơn 3.1 Pro trên một số benchmark agentic, lập trình và các điểm chuẩn khác trong khi hoạt động nhanh hơn nhiều.
Hiện tại, nó có sẵn thông qua API, chatbot Gemini, Gemini cho Google Workspace và nhiều tính năng khác.
Gemini 3.1 Pro
Gemini 3.1 Pro là mô hình flagship tiên tiến nhất của Google. Nó có cửa sổ ngữ cảnh 1 triệu token và có khả năng suy luận. Nó đặc biệt giỏi trong việc lập trình và phản hồi các yêu cầu phức tạp. Hiện tại, nó có sẵn thông qua API, chatbot Gemini, Google AI Search, Gemini cho Google Workspace và các công cụ khác của Google. Nó có thể sẽ sớm được thay thế bằng Gemini 3.5 Pro, hiện đang trong giai đoạn thử nghiệm.
Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite được thiết kế để tiết kiệm chi phí và đạt thông lượng cao. Nó có sẵn thông qua API. Có thể nó sẽ được thay thế bằng Gemini 3.5 Flash-Lite trong những tháng tới.
Gemini Omni Flash
Gemini Omni Flash là sản phẩm đầu tiên trong dòng sản phẩm Gemini mới. Hiện tại, tính năng này cho phép bạn tạo và chỉnh sửa video với các prompt văn bản, hình ảnh, video và âm thanh, nhưng trong tương lai sẽ được cập nhật để hỗ trợ cả việc tạo hình ảnh và âm thanh. Tính năng này đang được triển khai trên Gemini, Google Flow và YouTube.
Các mô hình Gemini cũ hơn
Ngoài các mô hình Gemini 3.5 và 3.1 hiện đại, còn có một vài mô hình Gemini khác đáng chú ý:
- Gemini 3 Pro. Mô hình flagship trước đây; nó đã bị ngừng phát triển để nhường chỗ cho 3.1 Pro.
- Gemini 2.5 Pro, Flash và Flash-Lite. Thế hệ trước đó; tất cả đều đã được thay thế bởi các phiên bản Gemini 3.
- Gemini 2.0 Flash. Trước đây là mô hình được bán rộng rãi nhất của Google, Gemini 2.0 Flash hiện đã được thay thế bởi các phiên bản sau này.
- Gemini 1.0 Ultra. Gemini Ultra là mô hình Gemini lớn nhất và mạnh nhất khi được công bố. Nó chưa bao giờ được phát hành rộng rãi, mặc dù có những tin đồn dai dẳng rằng nó sẽ được nâng cấp.
- Gemini 1.0 Nano. Một mô hình nhỏ được thiết kế cho các thao tác trên thiết bị, dường như nó đã bị thay thế bởi Flash nhưng rất có thể sẽ được đưa trở lại vào một thời điểm nào đó.
Google sử dụng Gemini như thế nào?

Hai năm kể từ khi Kỷ nguyên Gemini bắt đầu, Google đã tích hợp (hoặc có kế hoạch tích hợp) trí tuệ nhân tạo (AI) vào hầu hết mọi nơi có thể. Danh sách này chưa đầy đủ vì Google vẫn đang tiếp tục triển khai các tính năng mới, nhưng hãy cùng điểm qua những công cụ chính được hỗ trợ bởi Gemini:
- Google Gemini (chatbot). Nơi rõ ràng nhất mà Google triển khai Gemini là với chatbot - trước đây được gọi là Bard. Nó cũng được gọi là Gemini và là đối thủ cạnh tranh trực tiếp của ChatGPT hơn là thay thế cho Tìm kiếm. Nó có chế độ nghiên cứu chuyên sâu, có thể tìm kiếm trên web và tích hợp với các ứng dụng khác. Bạn thậm chí có thể tùy chỉnh nó với một tính năng gọi là Gems. Nếu bạn đang sử dụng sâu rộng hệ sinh thái của Google, đây là một công cụ tuyệt vời.
- Google Workspace. Lĩnh vực khác mà Gemini nổi bật đáng kể là các ứng dụng Workspace của Google như Gmail, Docs và Sheets. Bạn cần phải là người đăng ký Business Standard (16,80 USD/người dùng/tháng) để có được toàn bộ sức mạnh của Gemini trên tất cả các ứng dụng khác nhau, nhưng nó có thể làm được rất nhiều việc.
- Google One. Đối với người dùng không phải doanh nghiệp, gói Google One AI Pro với giá 20 USD/tháng cho phép truy cập vào nhiều mô hình và tính năng tiên tiến nhất của Gemini trong chatbot cũng như Gemini trong Gmail, Docs và các ứng dụng Google khác. Ngoài ra còn có gói AI Ultra với giá 250 USD/tháng, nhưng gói này chỉ đáng giá đối với một số ít người dùng.
- Google Search. Tìm kiếm sẽ tiếp tục nhận được nhiều bản cập nhật được hỗ trợ bởi Gemini. AI Overviews về cơ bản là các hộp trả lời nhanh cho những truy vấn phức tạp hơn. Và Chế độ AI (có sẵn cho một số người dùng trong Labs) cung cấp một công cụ tìm kiếm AI thực sự hơn, giống như Perplexity.
- Android Auto và Gemini cho Google TV. Cả hai sản phẩm đều nhận được bản cập nhật Gemini trong năm nay.
- Android. Việc tích hợp Gemini tiếp tục được triển khai cho hệ điều hành điện thoại thông minh của Google.
- Mọi nơi khác. Google đã đầu tư mạnh vào trí tuệ nhân tạo (AI), và sau vài năm khó khăn, cuối cùng họ cũng bắt kịp các đối thủ. Hãy chuẩn bị tinh thần để thấy Gemini xuất hiện trong mọi ứng dụng mà Google có thể tích hợp nó vào – ít nhất là cho đến khi có một sự thay đổi tên gọi khác. Nó thậm chí còn sắp có mặt trên Chrome (tính năng này đã được hé lộ từ lâu và cuối cùng dường như sắp được ra mắt).
Cách truy cập Google Gemini
Cách dễ nhất để tìm hiểu về Gemini là thông qua chatbot cùng tên. Nếu đăng ký gói Gemini, bạn cũng có thể sử dụng nó trong nhiều ứng dụng khác nhau của Google.
Một trong những tính năng tốt nhất của Gemini hiện miễn phí cho tất cả mọi người
Không phải câu hỏi nào cũng cần câu trả lời ngay lập tức. Đôi khi, tốt hơn hết là nên dành chút thời gian suy nghĩ kỹ vấn đề trước khi trả lời. Đó chính xác là những gì tính năng Extended Thinking của Gemini thực hiện, và giờ đây mọi người đều có thể sử dụng nó, ngay cả khi không có gói đăng ký.
Bản nâng cấp thông minh nhất của Gemini giờ đây dễ tiếp cận hơn
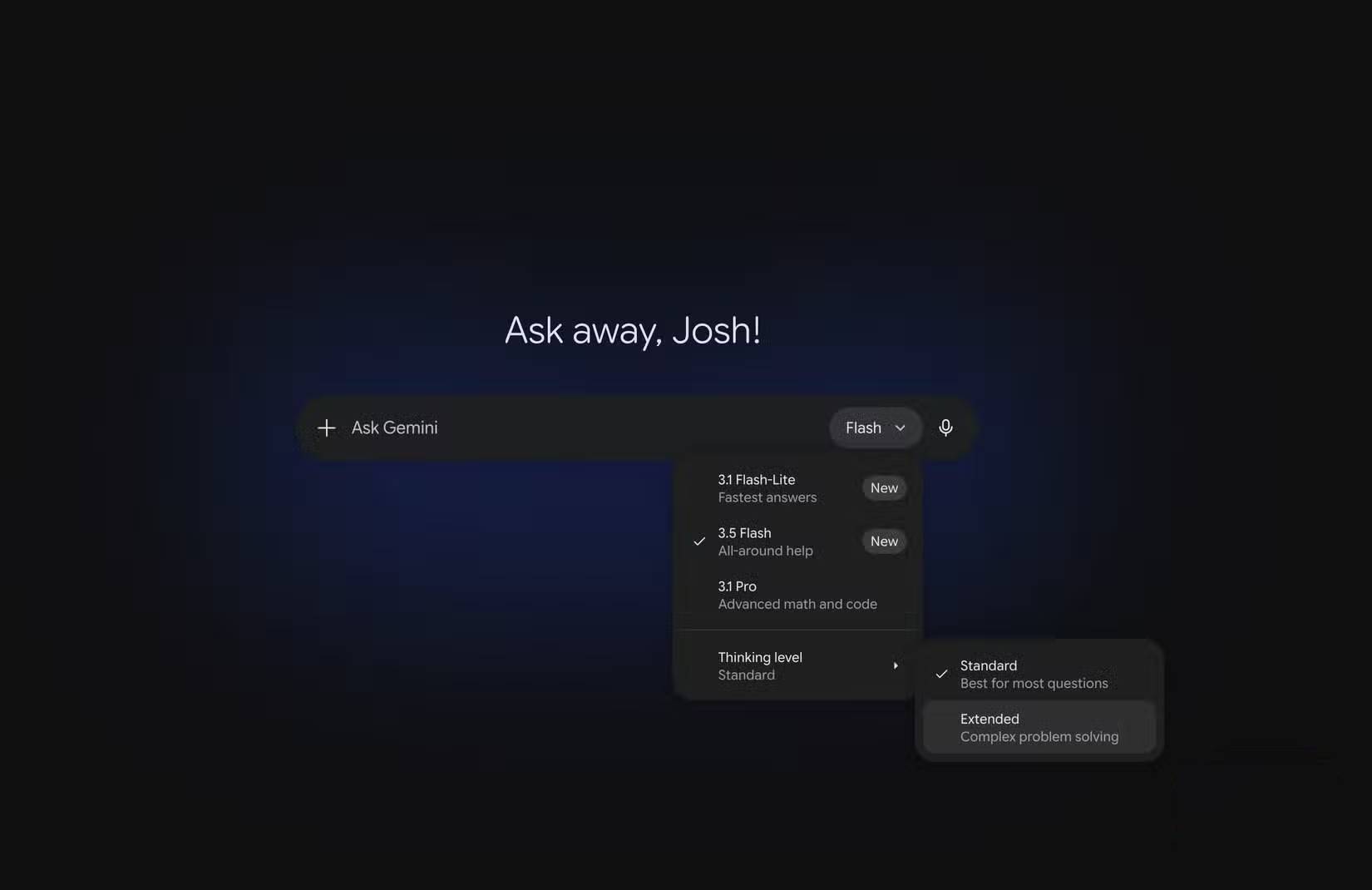
Google ban đầu giới thiệu các mô hình Extended Thinking như một phần trong nỗ lực rộng lớn hơn của họ vào lĩnh vực suy luận AI. Thay vì tạo ra câu trả lời ngay lập tức, các mô hình Extended Thinking và suy luận dành thêm thời gian để xử lý vấn đề trước khi trả lời, điều này thường dẫn đến kết quả chính xác và chi tiết hơn cho các câu hỏi phức tạp. Có rất nhiều yếu tố ảnh hưởng đến cách hoạt động của các mô hình suy luận so với những mô hình không suy luận, nhưng điểm mấu chốt nằm ở mức độ nỗ lực được đầu tư vào giai đoạn nghiên cứu.
Tính năng suy luận mạnh mẽ hơn hiện có thể được kích hoạt khi sử dụng Gemini 3.5 Flash hoặc Gemini 3.5 Flash-lite, cho phép người dùng miễn phí truy cập vào một công cụ trước đây chỉ có trong các trải nghiệm AI cao cấp. Sự khác biệt sẽ dễ nhận thấy nhất khi bạn yêu cầu Gemini thực hiện những việc phức tạp hơn. Nếu bạn đang nghiên cứu một chủ đề, so sánh sản phẩm, khắc phục sự cố kỹ thuật hoặc cố gắng học một kỹ năng mới, thì Extended Thinking sẽ cho phép AI có thêm thời gian để suy luận yêu cầu trước khi phản hồi (theo Android Authority).
Đây là loại tính năng AI nên được miễn phí!
Một trong những lý do lớn nhất khiến sự thay đổi này thú vị là nó mang đến cho những người không có đăng ký Gemini trả phí cơ hội để xem mô hình AI có khả năng làm được gì. Vì việc tìm kiếm chatbot AI tốt nhất cho nhu cầu của bạn có thể khó khăn, động thái này mở ra cánh cửa cho Gemini có thể thu hút thêm nhiều người dùng. Tuy nhiên, bạn cần đảm bảo rằng mình không lãng phí thời gian sử dụng hàng ngày. Bởi vì mặc dù Extended Thinking có thể rất hữu ích, nhưng nó không cần thiết cho nhiều chức năng mà bạn có thể sử dụng trong Gemini. Điều đó có nghĩa là bạn nên tránh sử dụng chế độ này trong các cuộc trò chuyện không thực sự cần suy luận sâu sắc — vì vậy, nếu bạn chỉ yêu cầu Gemini thiết lập bộ hẹn giờ hoặc bất kỳ việc đơn giản nào khác, hãy đảm bảo bạn đã đặt nó ở chế độ Standard Thinking.
Để kích hoạt và bắt đầu sử dụng Extended Thinking, trước tiên bạn cần truy cập Gemini thông qua ứng dụng hoặc trên trang web. Sau đó, chọn mục hiển thị mô hình Gemini hiện tại ở góc dưới bên phải cửa sổ trò chuyện. Tìm mục Thinking và mở rộng nó để xem các tùy chọn Standard và Extended.
Hãy nhớ rằng việc chọn một trong hai tùy chọn sẽ giữ nguyên tùy chọn đó cho phần còn lại của cuộc trò chuyện, vì vậy nếu không muốn sử dụng hết dung lượng của mình cùng một lúc, hãy nhớ tắt chế độ Extended khi bạn không còn cần đến nó nữa. Bài viết cũng không khuyến khích sử dụng chế độ Extended để tạo bất kỳ hình ảnh hoặc video nào, vì cả hai chức năng đó cũng sẽ tiêu tốn dung lượng sử dụng của bạn.








 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học