 AI
AI  ChatGPT
ChatGPT  Gemini
Gemini  Thư viện Prompt
Thư viện Prompt  Công nghệ
Công nghệ  Học IT
Học IT  Tiện ích
Tiện ích 
Liệu các mô hình trí tuệ nhân tạo có thể giúp điều hướng qua các khu vực (đường phố) mà chúng chưa từng được đào tạo trước đây, hoặc chưa được cung cấp đủ dữ liệu đào tạo hay không? Đó là những gì mà các nhà khoa học tại đội ngũ phát triển trí tuệ nhân tạo DeepMind trăn trở. Và sau bao năm ấp ủ, cuối cùng các nhà khoa học cũng đã gặt hái được thành công trong một công trình nghiên cứu có tên: “Cross-View Policy Learning for Street Navigation“, mới được tiết lộ gần đây trong một bài báo xuất bản trên Arxiv.org.
Trong công trình nghiên cứu này, các nhà khoa học của DeepMind đã mô tả việc phát triển một chính sách AI được đào tạo từ kho dữ liệu phong phú nhiều góc độ (đa số là những hình ảnh được chụp từ trên xuống dưới), nhắm mục tiêu vào các khu vực khác nhau của thành phố, cho hiệu quả quan sát tối ưu hơn. Các nhà nghiên cứu tin rằng cách tiếp cận như vậy sẽ đem lại kết quả tổng quát hóa tốt hơn.
Về bản chất, công trình nghiên cứu này được lấy cảm hứng từ việc con người có thể nhanh chóng thích nghi với bố cục cũng như kết cấu cơ bản của một thành phố mới bằng cách xem xét kỹ lưỡng bản đồ của thành phố đó nhiều lần.
“Khả năng điều hướng từ các quan sát trực quan trong môi trường xa lạ là một thành phần cốt lõi trong việc nghiên cứu khả năng học hỏi điều hướng của các mô hình AI. Khả năng điều hướng đường phố trong các trường hợp thiếu dữ liệu đào tạo của các mô hình AI cho đến nay vẫn còn tương đối hạn chế, và việc dựa vào mô hình mô phỏng không phải là giải pháp có thể đem lại hiệu quả lâu dài. Ý tưởng cốt lõi của chúng tôi là ghép nối chế độ quan sát mặt đất với chế độ quan sát trên không và tìm hiểu các chính sách chung có thể cho phép chuyển đổi qua lại giữa các chế độ xem”, đại diện nhóm nghiên cứu cho biết.
Cụ thể hơn, bước đầu tiên mà các nhà nghiên cứu sẽ phải làm đó là tiến hành thu thập các bản đồ trên không về khu vực mà họ định điều hướng (kết hợp với những chế độ quan sát đường phố dựa trên tọa độ địa lý tương ứng). Tiếp theo, họ bắt tay vào một nhiệm vụ dịch chuyển gồm 3 phần chính, bắt đầu bằng việc đào tạo về dữ liệu và điều chỉnh vùng nguồn bằng cách sử dụng các dữ liệu quan sát khu vực từ trên không, và kết thúc bằng việc chuyển đến khu vực đã nhắm mục tiêu bằng những dữ liệu quan sát từ mặt đất.
Hệ thống học máy của nhóm nghiên cứu chứa đựng bộ 3 mô-đun riêng biệt, bao gồm:
- Mô-đun tích chập (convolutional module), chịu trách nhiệm về nhận thức trực quan.
- Mô-đun bộ nhớ dài-ngắn (long short-term memory - LSTM) có nhiệm vụ thu về các đặc điểm cụ thể theo vị trí.
- Mô-đun mạng nơ-ron hồi quy chính sách (policy recurrent neural module) giúp tạo ra sự phân chia thông qua các hành động.
Mô hình học máy này đã được triển khai trong StreetAir - một môi trường đường phố ngoài trời nhiều góc nhìn - được xây dựng trên cơ sở StreetLearn. (StreetLearn là một bộ sưu tập ảnh góc nhìn toàn cảnh tương tác đầu tiên được trích xuất từ Google Street View và Google Maps).
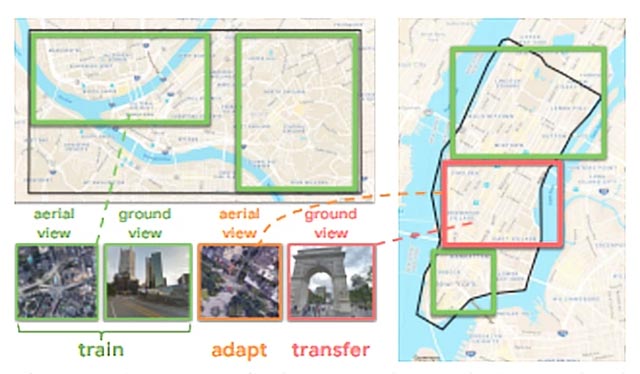
Trong StreetAir và StreetLearn, các hình ảnh trên không chứa đựng toàn cảnh Thành phố New York (bao gồm Downtown NYC và Midtown NYC) và Pittsburgh (khuôn viên của Đại học Allegheny và Carnegie Mellon) được bố trí sao cho ở mỗi tọa độ vĩ độ và kinh độ, môi trường trả về hình ảnh trên không ở kích thước 84 x 84, cùng kích thước với hình ảnh từ mặt đất.
Hệ thống AI, sau khi đã trải qua quá trình đào tạo, sẽ được giao nhiệm vụ học cách cục bộ hóa và điều hướng một biểu đồ hình ảnh toàn cảnh của Street View với những tọa độ kinh độ và vĩ độ của đích đến.
Những bức ảnh toàn cảnh bao phủ các khu vực từ 2-5km một bên, cách nhau khoảng 10m, và các phương tiện (điều khiển bằng AI) sẽ được phép thực hiện 1 trong 5 hành động mỗi lượt: di chuyển về phía trước, rẽ trái hoặc phải 22.5 độ hoặc rẽ trái hoặc phải 67.5 độ.
Khi gần tiếp cận được đến vị trí mục tiêu trong phạm vi 100-200 mét, các phương tiện này sẽ nhận được những “phần thưởng” nhằm khuyến khích cho việc xác định và vượt qua các điểm giao cắt một cách nhanh chóng và chính xác.

Trong các thí nghiệm, những phương tiện khai thác các hình ảnh trên không để thích nghi với môi trường mới đã đạt được số liệu phần thưởng là 190 ở 100 triệu bước và 280 ở 200 triệu bước, cả 2 trường hợp đều cao hơn đáng kể so với các phương tiện chỉ sử dụng dữ liệu quan sát mặt đất (50 ở 100 triệu bước và 200 ở 200 triệu bước). Theo các nhà nghiên cứu, kết quả này đã chỉ ra rằng phương pháp của họ giúp cải thiện đáng kể khả năng của các phương tiện trong việc thu nhận kiến thức về nhiều khu vực của thành phố mục tiêu một cách hiệu quả hơn.














 AI
AI  Hướng dẫn AI
Hướng dẫn AI  Ứng dụng
Ứng dụng  Hệ thống
Hệ thống  Game - Trò chơi
Game - Trò chơi  iPhone
iPhone  Android
Android  Hàm Excel
Hàm Excel  Download
Download  Khoa học
Khoa học  Cuộc sống
Cuộc sống  Làng Công nghệ
Làng Công nghệ