 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Hầu hết các công cụ AI chúng ta sử dụng đều chạy trên đám mây và yêu cầu kết nối Internet. Mặc dù có thể sử dụng các công cụ AI cục bộ được cài đặt trên máy tính, nhưng bạn cần phần cứng mạnh mẽ để làm như vậy.
Ít nhất, đó là những gì mọi người thường nghĩ, cho đến khi họ thử chạy một số công cụ AI cục bộ bằng phần cứng đã gần một thập kỷ của mình và thấy rằng nó thực sự hoạt động.
Tại sao lại sử dụng chatbot AI cục bộ?
Mọi người đã sử dụng vô số chatbot AI trực tuyến, chẳng hạn như ChatGPT, Gemini, Claude, v.v... Chúng hoạt động rất tốt. Nhưng còn những lúc bạn không có kết nối Internet mà vẫn muốn sử dụng chatbot AI thì sao? Hoặc nếu bạn muốn làm việc với thông tin cực kỳ riêng tư hoặc không thể tiết lộ cho công việc hoặc mục đích khác?
Đó là lúc bạn cần một mô hình ngôn ngữ lớn (LLM) cục bộ, ngoại tuyến, lưu trữ tất cả các cuộc trò chuyện và dữ liệu của bạn trên thiết bị.
Quyền riêng tư là một trong những lý do chính để sử dụng LLM cục bộ. Nhưng cũng có những lý do khác, chẳng hạn như tránh kiểm duyệt, sử dụng ngoại tuyến, tiết kiệm chi phí, tùy chỉnh, v.v...
LLM lượng tử hóa là gì?
Vấn đề lớn nhất đối với hầu hết những người muốn sử dụng LLM cục bộ là phần cứng. Các mô hình AI mạnh mẽ nhất yêu cầu phần cứng cực mạnh để chạy. Ngoài sự tiện lợi, hạn chế về phần cứng là một lý do khác khiến hầu hết các chatbot AI được sử dụng trên nền tảng đám mây.
Hạn chế về phần cứng là một lý do khiến nhiều người tin rằng mình không thể chạy LLM cục bộ. Hiện tại, nhiều người có một chiếc máy tính khá khiêm tốn, với CPU AMD Ryzen 5800x (ra mắt năm 2020), RAM DDR4 32GB và GPU GTX 1070 (ra mắt năm 2016). Vì vậy, nó không phải là đỉnh cao của phần cứng, nhưng xét việc ít chơi game (và khi chơi, chỉ chọn các game indie cũ, ít tốn tài nguyên) và GPU hiện đại đắt đỏ như thế nào, hãy hài lòng với những gì mình có.
Tuy nhiên, hóa ra bạn không cần mô hình AI mạnh nhất. LLM lượng tử hóa là các mô hình AI được thu nhỏ và nhanh hơn bằng cách đơn giản hóa dữ liệu mà chúng sử dụng, cụ thể là những số dấu phẩy động.
Thông thường, AI hoạt động với các số có độ chính xác cao (chẳng hạn như số dấu phẩy động 32 bit), tiêu tốn một lượng lớn bộ nhớ và sức mạnh xử lý. Lượng tử hóa làm giảm các giá trị này xuống những số có độ chính xác thấp hơn (như số nguyên 8 bit) mà không làm thay đổi quá nhiều hành vi của mô hình. Điều này có nghĩa là mô hình chạy nhanh hơn, sử dụng ít dung lượng lưu trữ hơn và có thể hoạt động trên các thiết bị nhỏ hơn (như điện thoại thông minh hoặc phần cứng biên), mặc dù đôi khi độ chính xác sẽ giảm nhẹ.
Điều này có nghĩa là mặc dù phần cứng cũ chắc chắn sẽ gặp khó khăn khi chạy một LLM mạnh mẽ như mô hình 205 tỷ tham số của Llama 3.1, nhưng nó có thể chạy 8B lượng tử hóa nhỏ hơn.
Và khi OpenAI công bố các mô hình suy luận trọng số mở, lượng tử hóa hoàn toàn đầu tiên của mình, đã đến lúc xem chúng hoạt động tốt như thế nào trên phần cứng cũ.
Cách sử dụng LLM cục bộ với Nvidia GTX 1070 và LM Studio
Xin lưu ý trong phần này rằng tác giả bài viết không phải là chuyên gia về LLM cục bộ, cũng không phải là chuyên gia về phần mềm được sử dụng để thiết lập và chạy mô hình AI này trên máy của mình. Đây chỉ là những gì đã được thực hiện để chạy chatbot AI cục bộ trên GTX 1070 và nó thực sự hoạt động tốt.
Tải LM Studio
Để chạy LLM cục bộ, bạn cần một số phần mềm. Cụ thể là LM Studio, một công cụ miễn phí cho phép bạn tải xuống và chạy LLM cục bộ trên máy của mình. Truy cập trang chủ LM Studio và chọn Download for [hệ điều hành] (bài viết đang sử dụng Windows 10).
Đây là quy trình cài đặt Windows tiêu chuẩn. Chạy thiết lập và hoàn tất quy trình cài đặt, sau đó khởi chạy LM Studio. Bạn nên chọn tùy chọn Power User vì nó hiển thị một số tùy chọn hữu ích mà bạn có thể muốn sử dụng.
Tải mô hình AI cục bộ đầu tiên
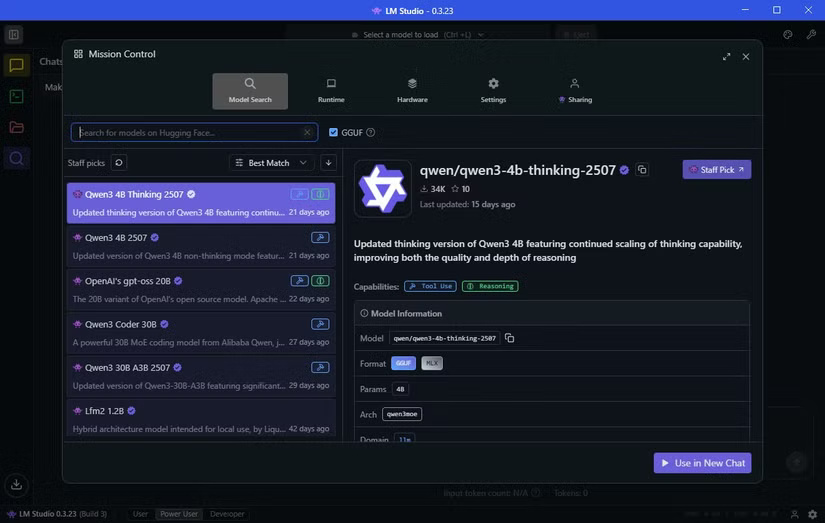
Sau khi cài đặt, bạn có thể tải xuống LLM đầu tiên. Chọn tab Discover (biểu tượng kính lúp). Tiện lợi thay, LM Studio hiển thị các mô hình AI cục bộ hoạt động tốt nhất trên phần cứng của bạn.
Trong trường hợp ví dụ, nó gợi ý tải xuống một mô hình có tên Qwen 3-4b-thinking-2507. Tên mô hình là Qwen (do gã khổng lồ công nghệ Trung Quốc Alibaba phát triển), và đây là phiên bản thứ ba của mô hình này. Giá trị "4b" có nghĩa là mô hình này có 4 tỷ tham số được gọi đến để phản hồi cho bạn, trong khi "thinking" có nghĩa là mô hình này sẽ dành thời gian xem xét câu trả lời của nó trước khi phản hồi. Cuối cùng, 2507 là lần cập nhật cuối cùng của mô hình này, vào ngày 25 tháng 7.
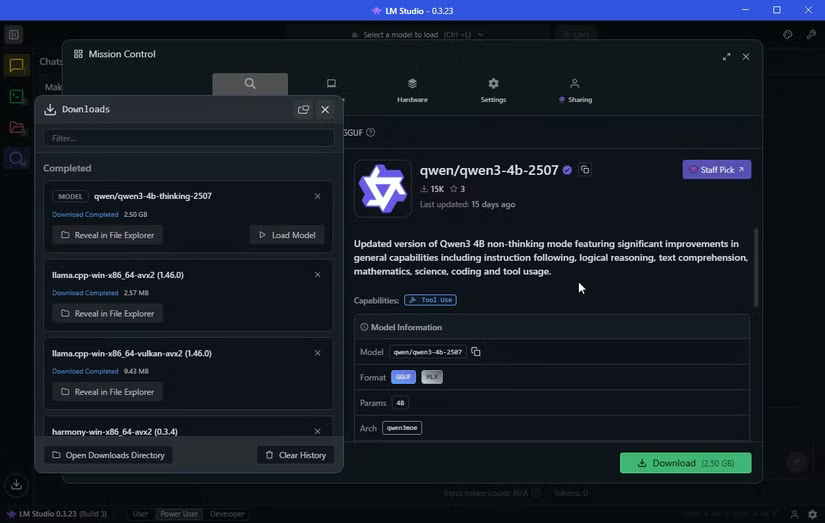
Qwen3-4b-thinking chỉ có dung lượng 2,5GB, vì vậy sẽ không mất nhiều thời gian để tải xuống. Trước đó, tác giả cũng đã tải xuống OpenAI/gpt-oss-20b, lớn hơn với dung lượng 12,11GB. Nó cũng có 20 tỷ tham số, vì vậy nó sẽ cung cấp câu trả lời "tốt hơn", mặc dù sẽ đi kèm với chi phí tài nguyên cao hơn.
Gạt sang một bên sự phức tạp của tên mô hình AI, sau khi tải xuống LLM, bạn gần như đã sẵn sàng để bắt đầu sử dụng nó.
Trước khi khởi động mô hình AI, hãy chuyển sang tab Hardware và đảm bảo LM Studio nhận dạng chính xác hệ thống của bạn. Bạn cũng có thể cuộn xuống và điều chỉnh Guardrails tại đây. Tác giả đã đặt Guardrails trên máy của mình thành Balanced, ngăn bất kỳ mô hình AI nào tiêu thụ quá nhiều tài nguyên, điều này có thể gây quá tải hệ thống.

Trong Guardrails, bạn cũng sẽ thấy mục Resource Monitor. Đây là một cách tiện dụng để xem mô hình AI đang tiêu thụ bao nhiêu tài nguyên hệ thống. Bạn nên chú ý đến mục này nếu đang sử dụng phần cứng hạn chế, vì bạn không muốn hệ thống của mình bị sập bất ngờ.
Load mô hình AI và bắt đầu tạo prompt
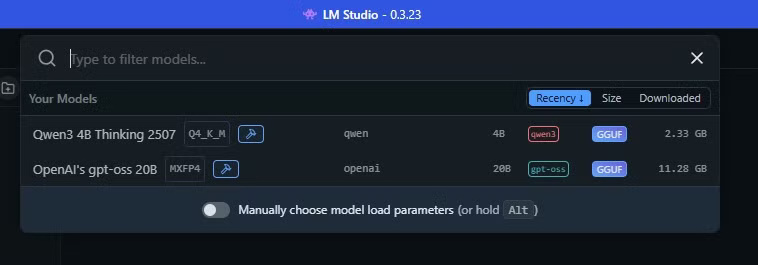
Giờ bạn đã sẵn sàng để bắt đầu sử dụng chatbot AI cục bộ trên máy của mình. Trong LM Studio, hãy chọn thanh trên cùng, có chức năng như một công cụ tìm kiếm. Chọn tên AI sẽ load mô hình AI vào bộ nhớ trên máy tính và bạn có thể bắt đầu tạo prompt.
Phần cứng cũ cũng có thể chạy mô hình AI
Việc chạy một LLM cục bộ trên phần cứng cũ phụ thuộc vào việc chọn đúng mô hình AI cho máy của bạn. Mặc dù phiên bản Qwen hoạt động hoàn hảo và là gợi ý hàng đầu trong LM Studio, nhưng rõ ràng gpt-oss-20b của OpenAI là lựa chọn tốt hơn nhiều.
Điều quan trọng là phải cân bằng kỳ vọng của bạn. Mặc dù gpt-oss đã trả lời chính xác các câu hỏi (và nhanh hơn GPT-5), nhưng nó sẽ không thể xử lý một lượng lớn dữ liệu. Những hạn chế của phần cứng sẽ nhanh chóng bộc lộ.
Trước khi thử, nhiều người đã tin rằng việc chạy một chatbot AI cục bộ trên phần cứng cũ là không thể. Nhưng nhờ các mô hình lượng tử hóa và các công cụ như LM Studio, điều đó không chỉ khả thi mà còn hữu ích một cách đáng ngạc nhiên.
Tuy nhiên, bạn sẽ không có được cùng tốc độ, độ hoàn thiện hoặc độ sâu suy luận như GPT-5 trên đám mây. Chạy cục bộ đòi hỏi phải đánh đổi: Bạn có được quyền riêng tư, quyền truy cập ngoại tuyến và quyền kiểm soát dữ liệu của mình, nhưng sẽ phải hy sinh một số hiệu suất.
Tuy nhiên, việc một GPU 7 năm tuổi và một CPU 4 năm tuổi có thể xử lý AI hiện đại quả là một điều khá thú vị. Nếu bạn còn ngần ngại vì không sở hữu phần cứng tiên tiến, thì đừng lo - các mô hình cục bộ lượng tử hóa có thể là con đường dẫn bạn đến thế giới AI ngoại tuyến.







 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học