 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Đã qua rồi cái thời các doanh nghiệp/tổ chức chỉ sử dụng giấy tờ để lưu trữ thông tin khách hàng (như tên, ảnh, chữ ký mẫu…). Nghĩ lại, đó là thời kỳ mà những cuốn sổ với đủ loại thông tin dữ liệu dày cồm cộp lên ngôi và luôn có mặt trong các văn phòng, để mỗi khi cần cập nhật bất kỳ chi tiết nào, nhân viên sẽ mất trọn ngày làm việc để tìm kiếm và chỉnh sửa. Các khách hàng cũng phải chờ hàng giờ đến vài ngày chỉ để giải quyết những vấn đề nhỏ như vậy.
Ngoài sự tẻ nhạt trong việc tìm kiếm dữ liệu từ các sổ cái, các tập tin giấy cũng đó có thể bị mất bất cứ lúc nào do các thảm họa như lũ lụt hay hỏa hoạn, chưa kể đến sự xuống cấp của chất liệu giấy tờ được sử dụng.
Quay lại câu chuyện hiện đại ngày nay, thật tuyệt vời là hầu như các công việc từ bình thường đến quan trọng đều đang dần được tự động hóa. Việc tự động hóa cốt yếu là để thu ngắn thời gian thực hiện công việc, vậy nên đòi hỏi dữ liệu phải được xử lý với tốc độ nhanh, càng nhanh càng tốt. Thuật ngữ "Big Data" xuất hiện từ đây.

Big data nhìn chung liên quan đến các tập dữ liệu có khối lượng lớn và phức tạp đến mức các phần mềm xử lý dữ liệu truyền thống không có khả năng thu thập, quản lý và xử lý dữ liệu trong một khoảng thời gian hợp lý.
Hiện nay có rất nhiều công cụ tuyệt vời được sử dụng cho quản lý Big Data và thật khó để đánh giá công cụ nào là tốt nhất. Ở bài viết này, Quantrimang xin đưa ra 5 cái tên được các chuyên gia đánh giá cao nhất cho các giải pháp Big Data được đề cập từ đầu. Vậy đó là những công cụ nào?
1. Apache Hadoop

Apache Hadoop là công cụ nổi bật và được sử dụng nhiều nhất trong lĩnh vực Big Data với khả năng xử lý dữ liệu quy mô lớn. Đây là framework mã nguồn mở 100%, cho phép xử lý phân tán (distributed processing) các tập dữ liệu lớn trên các cụm máy tính (clusters of computers) thông qua mô hình lập trình đơn giản. Hadoop được thiết kế để mở rộng quy mô từ một máy chủ đơn sang hàng ngàn máy tính khác có tính toán và lưu trữ cục bộ (local computation and storage). Hơn nữa, nó có thể chạy trên cơ sở hạ tầng đám mây. Hadoop bao gồm bốn phần:
- Hadoop Distributed File System: Thường được gọi là HDFS, là một hệ thống file phân tán cung cấp truy cập băng thông cao cho ứng dụng khai thác dữ liệu.
- MapReduce: Một mô hình lập trình để xử lý dữ liệu lớn.
- YARN: Đây là một nền tảng được sử dụng để quản lý và lên lịch các tài nguyên Hadoop, trong cơ sở hạ tầng Hadoop.
- Các thư viện: Giúp các module khác hoạt động với Hadoop.
2. Apache Storm
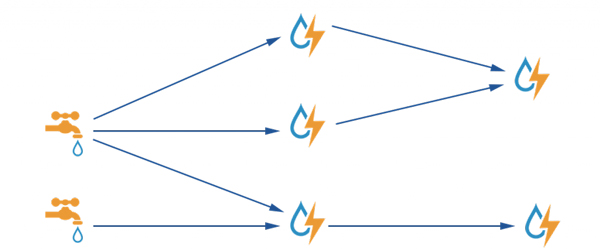
Apache Storm là framework xử lý luồng tập trung vào độ trễ cực thấp và có lẽ là tùy chọn tốt nhất cho các công việc cần xử lý gần thời gian thực. Các tính năng độc đáo của Apache Storm là:
- Khả năng mở rộng lớn.
- Khả năng không gây ra sự gián đoạn cho hệ thống.
- Cách tiếp cận "fail fast, auto restart".
- Quá trình đảm bảo của mọi tuple.
- Viết bằng Clojure.
- Chạy trên máy ảo Java.
- Hỗ trợ cấu trúc liên kết đồ thị acrylic trực tiếp (Direct Acrylic Graph - DAG).
- Hỗ trợ nhiều ngôn ngữ.
- Hỗ trợ các giao thức như JSON.
Công việc của Storm tương tự như MapReduce, tuy nhiên Storm xử lý dữ liệu luồng thời gian thực thay vì xử lý dữ liệu hàng loạt. Dựa trên cấu hình cấu trúc liên kết, Storm phân phối khối lượng công việc cho các node. Ngoài ra nó cũng có thể tương tác với HDFS của Hadoop thông qua các bộ điều hợp nếu cần, đó là một điểm khác biệt làm Storm trở thành một công cụ Big Data mã nguồn mở cực kỳ hữu ích.
3. Cassandra

Apache Cassandra là cơ sở dữ liệu kiểu phân tán, quản lý một tập hợp dữ liệu lớn trên các máy chủ riêng biệt. Đây là một trong những công cụ Big Data tốt nhất, chủ yếu xử lý các tập dữ liệu có cấu trúc. Ngoài ra, nó có một số khả năng nhất định mà không cơ sở dữ liệu quan hệ và cơ sở dữ liệu phi quan hệ nào có thể cung cấp. Những khả năng này là:
- Sẵn có liên tục như một nguồn dữ liệu.
- Hiệu suất mở rộng tuyến tính.
- Thao tác đơn giản.
- Dễ dàng phân phối dữ liệu trên nhiều trung tâm dữ liệu.
- Khả dụng trên đám mây.
- Khả năng mở rộng.
- Hiệu suất tốt.
Apache Cassandra không tuân theo kiến trúc Master-Slave mà tất cả các node có vai trò như nhau. Nó có thể xử lý nhiều thao tác đồng thời trên các trung tâm dữ liệu. Do đó, việc thêm một node mới sẽ không ảnh hưởng đến cụm hiện có ngay cả tại thời điểm làm việc.
4. KNIME

KNIME tên đầy đủ là Konstanz Information Miner, là một nền tảng phân tích, tích hợp và báo cáo dữ liệu mã nguồn mở. Nó tích hợp các thành phần khác nhau của data mining và machine learning thông qua khái niệm module data pipeline. Giao diện người dùng đồ họa cho phép lắp ráp các node để xử lý trước dữ liệu (bao gồm trích xuất, chuyển đổi và tải), mô hình hóa dữ liệu, trực quan hóa và phân tích dữ liệu. Từ năm 2006, KNIME đã được sử dụng rộng rãi trong nghiên cứu dược phẩm và hiện tại mở rộng sang các lĩnh vực như phân tích dữ liệu khách hàng trong CRM, phân tích dữ liệu tài chính và kinh doanh thông minh.
Tính năng, đặc điểm:
- KNIME được viết bằng Java và dựa trên Eclipse, sử dụng khả năng mở rộng để thêm plugin và cung cấp chức năng bổ sung.
- Phiên bản core của KNIME bao gồm các module để tích hợp dữ liệu, chuyển đổi dữ liệu và các phương pháp thường được sử dụng để trực quan hóa, phân tích dữ liệu.
- KNIME cho phép người dùng tạo các luồng dữ liệu và thực hiện có chọn lọc một hoặc tất cả chúng.
- Luồng công việc KNIME cũng có thể được sử dụng làm tập dữ liệu để tạo mẫu báo cáo, có thể được xuất sang các định dạng tài liệu khác nhau như doc, PPT...
Kiến trúc cốt lõi của KNIME cho phép xử lý khối lượng dữ liệu lớn và chỉ bị giới hạn bởi không gian đĩa cứng có sẵn. - Các plugin bổ sung cho phép tích hợp các phương pháp khác nhau để khai thác hình ảnh, khai thác văn bản cũng như phân tích chuỗi thời gian.
5. Công cụ lập trình R

Đây là một trong những công cụ mã nguồn mở được sử dụng rộng rãi trong lĩnh vực Big Data để phân tích thống kê dữ liệu. Điều quan trọng khiến R cực kỳ được yêu thích là mặc dù được sử dụng để phân tích thống kê nhưng người dùng không cần phải là một chuyên gia thống kê thực thụ. R có thư viện công khai CRAN (Comprehensive R Archive Network) bao gồm hơn 9000 module và thuật toán để phục vụ cho công việc phân tích thống kê dữ liệu của mình.
R có thể chạy trên máy chủ Windows và Linux cũng như bên trong máy chủ SQL, nó cũng hỗ trợ các công cụ khác như Hadoop và Spark. Người ta có thể sử dung công cụ R để làm việc trên những dữ liệu rời rạc hay thử phân tích một thuật toán phân tích mới. Có thể đánh giá R là ngôn ngữ cực kỳ linh hoạt, một mô hình R được xây dựng và thử nghiệm trên nguồn dữ liệu cục bộ có thể dễ dàng được thực hiện trong các máy chủ khác.
Đó là tất cả. Nếu bạn nghĩ rằng Quantrimang đã bỏ lỡ một công cụ quan trọng nào trong danh sách này thì hãy bình luận bên dưới để Quantrimang bổ sung nhé.
Xem thêm:







 Làng Công nghệ
Làng Công nghệ
 Chuyện công nghệ
Chuyện công nghệ
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học