 AI
AI  ChatGPT
ChatGPT  Gemini
Gemini  Thư viện Prompt
Thư viện Prompt  Công nghệ
Công nghệ  Học IT
Học IT  Tiện ích
Tiện ích 
Anthropic đã phát hành mô hình Sonnet Claude 3.5 mới nhất của mình gần đây và tuyên bố rằng nó đánh bại ChatGPT 4o và Gemini 1.5 Pro trên nhiều benchmark. Vì vậy, để kiểm tra tuyên bố này, bài so sánh chi tiết này đã được thực hiện. Giống như so sánh trước đây giữa Claude 3 Opus, GPT-4 và Gemini 1.5 Pro, bài so sánh đã đánh giá khả năng lý luận, lý luận đa phương thức, tạo code, v.v... Cùng tìm hiểu chi tiết ngay sau đây nhé!
1. Tìm thời gian làm khô
Mặc dù đây có vẻ là một câu hỏi cơ bản nhưng hãy bắt đầu bài kiểm tra bằng câu hỏi lý luận khó này. LLM có xu hướng mắc sai lầm thường xuyên. Claude 3.5 Sonnet cũng mắc lỗi tương tự và tiếp cận câu hỏi bằng toán học. Mô hình cho biết sẽ mất 1 giờ 20 phút để làm khô 20 chiếc khăn, điều này không chính xác. ChatGPT 4o và Gemini 1.5 Pro đã có câu trả lời đúng khi nói rằng vẫn sẽ mất 1 giờ để làm khô 20 chiếc khăn.
If it takes 1 hour to dry 15 towels under the Sun, how long will it take to dry 20 towels?
Tạm dịch: Nếu phơi 15 chiếc khăn dưới ánh mặt trời trong 1 giờ thì phơi 20 chiếc khăn mất bao lâu?
Tùy chọn chiến thắng: ChatGPT 4o và Gemini 1.5 Pro

2. Đánh giá cân nặng
Tiếp theo, trong câu hỏi lý luận kinh điển này, rất vui là cả 3 mô hình gồm Claude 3.5 Sonnet, ChatGPT 4o và Gemini 1.5 Pro đều có câu trả lời đúng. Một kg lông vũ hay bất cứ thứ gì sẽ luôn nặng hơn một pound thép hoặc các vật liệu khác.
What's heavier, a kilo of feathers or a pound of steel?
Tạm dịch: Cái gì nặng hơn, một cân lông vũ hay một pound thép?
Tùy chọn chiến thắng: Claude 3.5 Sonnet, ChatGPT 4o và Gemini 1.5 Pro

3. Câu đố chữ
Trong bài kiểm tra lý luận tiếp theo, Claude 3.5 Sonnet trả lời đúng rằng David không có anh em và anh là người nam duy nhất trong số các anh chị em. ChatGPT 4o và Gemini 1.5 Pro đã có câu trả lời đúng.
David has three sisters. Each of them have one brother. How many brothers does David have?
Tạm dịch: David có ba chị gái. Mỗi người trong số họ có một em trai. David có bao nhiêu anh em?
Tùy chọn chiến thắng: Claude 3.5 Sonnet, ChatGPT 4o và Gemini 1.5 Pro
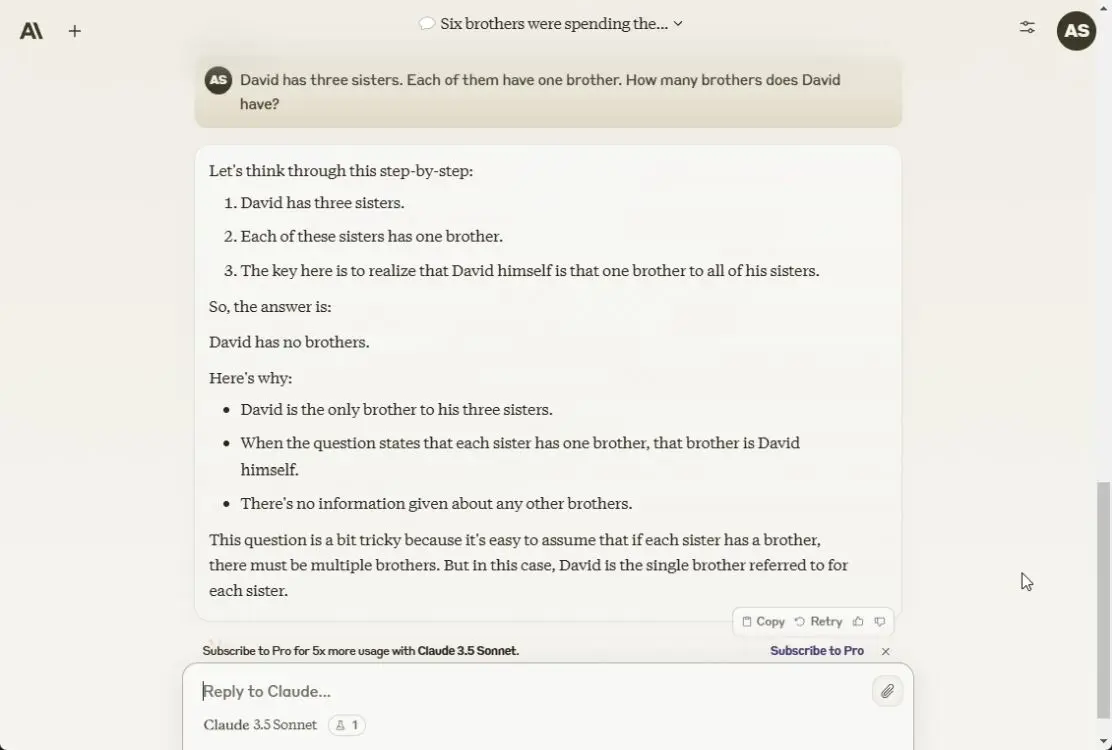
4. Sắp xếp các mục
Sau đó, tác giả bài viết yêu cầu cả 3 mô hình sắp xếp các đồ vật này sao cho ổn định. Rất tiếc cả ba đều sai. Các mô hình thực hiện một cách tiếp cận giống hệt nhau: Đầu tiên đặt máy tính xách tay, sau đó là cuốn sách, cái chai, cuối cùng là 9 quả trứng ở đáy chai, điều này là không thể. Mô hình GPT-4 cũ hơn đã có câu trả lời đúng.
Here we have a book, 9 eggs, a laptop, a bottle and a nail. Please tell me how to stack them onto each other in a stable manner.
Tạm dịch: Ở đây chúng ta có một cuốn sách, 9 quả trứng, một chiếc máy tính xách tay, một cái chai và một cái đinh. Cho tôi biết làm thế nào để xếp chồng chúng lên nhau để không bị đổ.
Tùy chọn chiến thắng: Không có
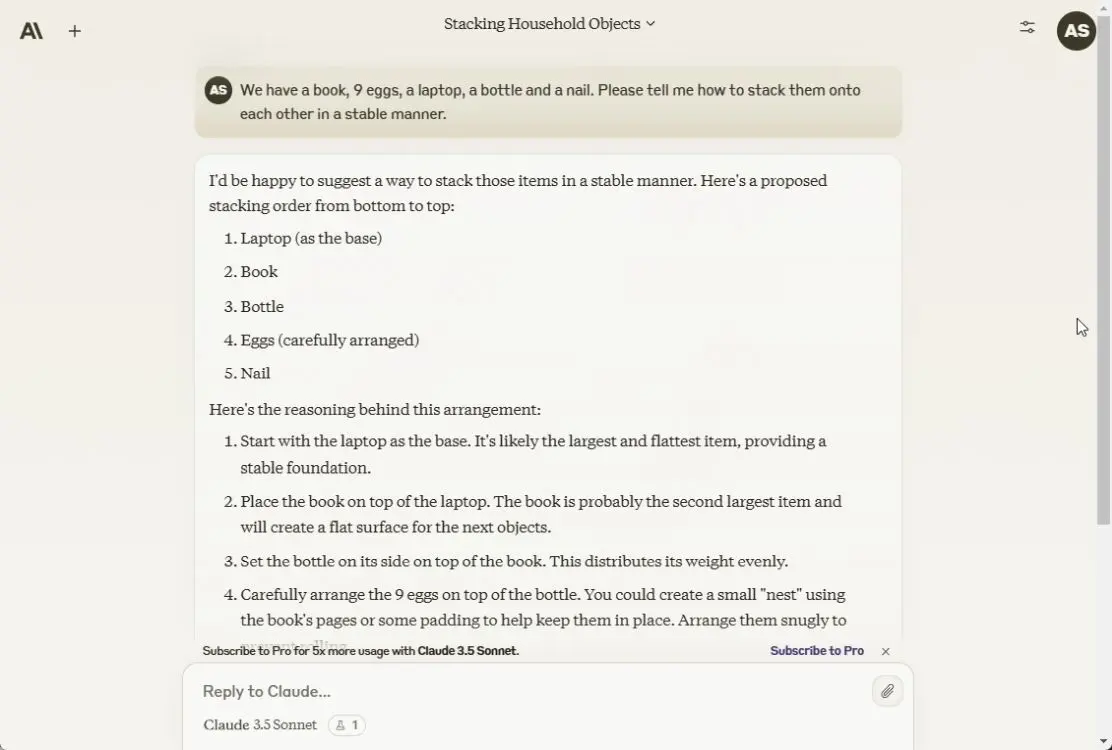
5. Làm theo hướng dẫn
Trong bài đăng trên blog của mình, Anthropic đã đề cập rằng Claude 3.5 Sonnet rất xuất sắc trong việc làm theo hướng dẫn và điều đó có vẻ đúng. Nó tạo ra tất cả 10 câu kết thúc bằng từ “AI”. ChatGPT 4o cũng làm đúng 10/10. Tuy nhiên, Gemini 1.5 Pro chỉ có thể tạo ra 5 câu đúng trong số 10 câu. Google phải định hướng mô hình để có hướng dẫn tốt hơn.
Generate 10 sentences that end with the word "AI"
Tạm dịch: Tạo 10 câu kết thúc bằng từ "AI"
Tùy chọn chiến thắng: Claude 3.5 Sonnet và ChatGPT 4o
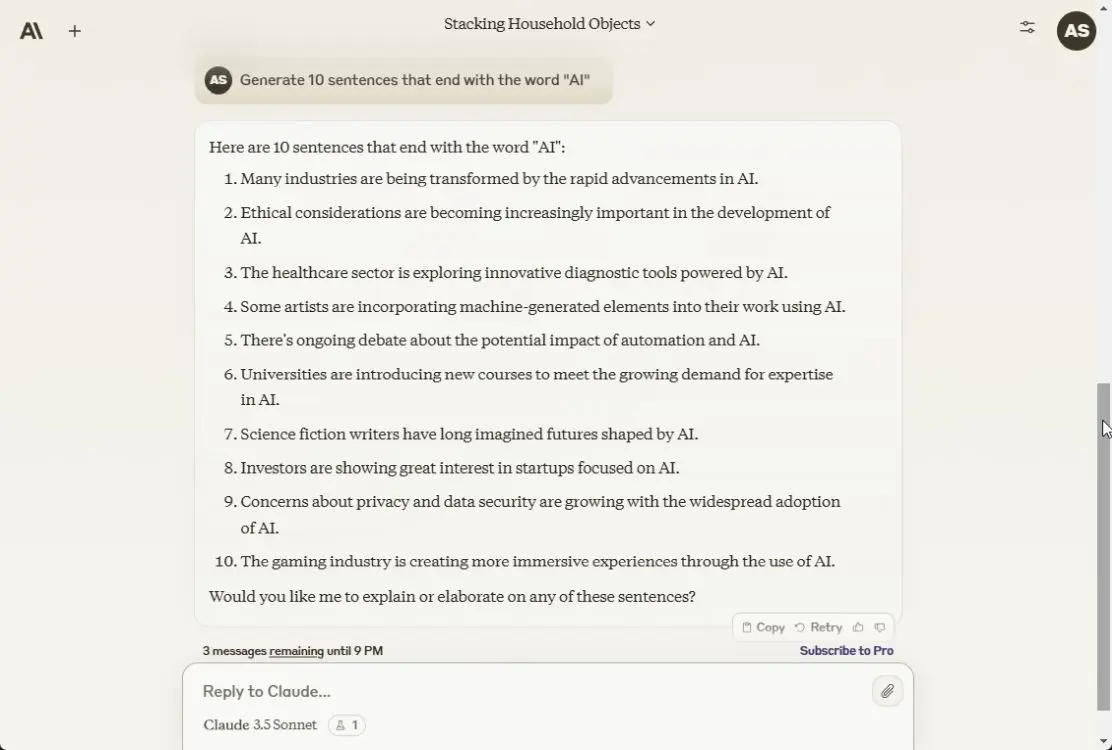
6. Tìm chi tiết
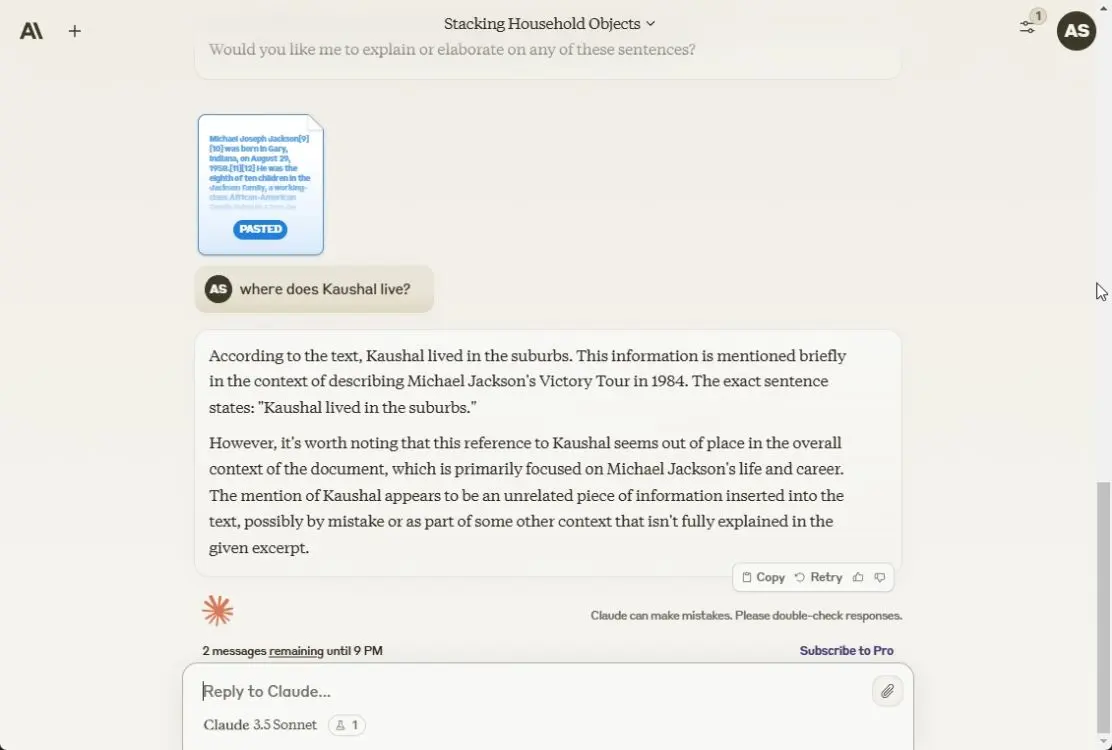
Anthropic là một trong những công ty đầu tiên cung cấp độ dài ngữ cảnh lớn, bắt đầu từ 100K token cho đến cửa sổ ngữ cảnh hiện nay là 200K. Vì vậy, đối với thử nghiệm này, tác giả bài viêst đã cung cấp một văn bản lớn có 25K ký tự và khoảng 6K token. Tác giả đã thêm một chi tiết vào đâu đó ở giữa văn bản.
Tác giả đã hỏi cả ba mô hình về chi tiết nhưng chỉ có Claude 3.5 Sonnet tìm ra được câu trả lời, còn ChatGPT 4o và Gemini 1.5 Pro không tìm thấy. Vì vậy, để xử lý các tài liệu lớn, Claude 3.5 Sonnet là mô hình tốt hơn.
Tùy chọn chiến thắng: Claude 3.5 Sonnet
7. Kiểm tra thị lực
Để kiểm tra khả năng thị giác, tác giả đã upload lên hình ảnh chữ viết khó đọc để xem các mô hình có thể phát hiện những ký tự và trích xuất chúng tốt đến mức nào. Thật ngạc nhiên, cả ba mô hình đều làm rất tốt và xác định chính xác các văn bản. Về OCR, cả ba mô hình đều có khả năng khá tốt.
Tùy chọn chiến thắng: Claude 3.5 Sonnet, ChatGPT 4o và Gemini 1.5 Pro

8. Tạo game
Trong thử nghiệm này, tác giả đã upload lên hình ảnh của game Tetris cổ điển mà không tiết lộ tên và chỉ yêu cầu mô hình tạo một game như thế này bằng Python. Cả ba mô hình đều đoán đúng game, nhưng chỉ có code do Sonnet tạo là chạy thành công. Cả ChatGPT 4o và Gemini 1.5 Pro đều không tạo được code không có lỗi.

Chỉ trong một lần, game đã chạy thành công bằng code của Sonnet. Nhiều lập trình viên sử dụng ChatGPT 4o để hỗ trợ viết code, nhưng có vẻ như mô hình của Anthropic có thể trở thành mô hình mới được các lập trình viên yêu thích.
Claude 3.5 Sonnet đã đạt 92% benchmark HumanEval để đánh giá khả năng lập trình. Trong benchmark này, GPT-4o đạt mức 90,2% và Gemini 1.5 Pro ở mức 84,1%. Rõ ràng, để lập trình, có một mô hình SOTA mới và đó là Claude 3.5 Sonnet.
Tùy chọn chiến thắng: Claude 3.5 Sonnet
Sau khi chạy nhiều thử nghiệm khác nhau trên cả ba mô hình, Claude 3.5 Sonnet tốt ngang với mô hình ChatGPT 4o, nếu không muốn nói là xuất sắc hơn. Đặc biệt trong lĩnh vực lập trình, mô hình mới của Anthropic thực sự rất ấn tượng. Điều đáng chú ý là mô hình Sonnet mới nhất thậm chí còn chưa phải là mô hình lớn nhất của Anthropic.
Công ty cho biết Claude 3.5 Opus sẽ ra mắt vào cuối năm nay và thậm chí còn hoạt động tốt hơn nữa. Gemini 1.5 Pro của Google cũng hoạt động tốt hơn các thử nghiệm trước đây, điều đó có nghĩa là nó đã được cải thiện đáng kể. Nhìn chung, có thể nói rằng OpenAI không phải là AI duy nhất hoạt động tốt trong lĩnh vực LLM. Claude 3.5 Sonnet của Anthropic là một minh chứng cho điều đó.














 AI
AI  Hướng dẫn AI
Hướng dẫn AI  Ứng dụng
Ứng dụng  Hệ thống
Hệ thống  Game - Trò chơi
Game - Trò chơi  iPhone
iPhone  Android
Android  Hàm Excel
Hàm Excel  Download
Download  Khoa học
Khoa học  Cuộc sống
Cuộc sống  Làng Công nghệ
Làng Công nghệ