 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Từ thời điểm OpenAI tung ra GPT-3 vào năm 2022 – nền tảng đứng sau ChatGPT – các mô hình ngôn ngữ lớn (LLM) đã nhanh chóng gây bão toàn cầu. Chúng được ứng dụng rộng rãi trong nhiều lĩnh vực, từ viết code cho đến tìm kiếm. Tuy nhiên, quá trình sinh phản hồi (gọi là inference ) lại khá chậm và tốn kém về chi phí tính toán. Khi ngày càng có nhiều người dùng LLM, việc tăng tốc, giảm chi phí nhưng vẫn đảm bảo chất lượng trở thành một bài toán sống còn với các nhà phát triển.
Hiện tại có hai phương pháp từng được kỳ vọng sẽ giải quyết vấn đề này: cascades và speculative decoding .
- Cascades: dùng một mô hình nhỏ, chạy nhanh hơn để xử lý trước, sau đó mới chuyển sang mô hình lớn nếu cần. Cách này tiết kiệm chi phí tính toán nhưng lại có nhược điểm là phải “chờ đợi” mô hình nhỏ quyết định. Nếu nó không chắc chắn, thời gian phản hồi vẫn bị kéo dài và chất lượng câu trả lời dễ dao động.
- Speculative decoding: một mô hình nhỏ sẽ đóng vai trò “dự thảo”, dự đoán trước các token theo kiểu song song. Sau đó mô hình lớn kiểm chứng nhanh kết quả. Cách này ưu tiên tốc độ nhưng khá khắt khe: chỉ cần 1 token sai, cả bản nháp bị loại bỏ, dù phần lớn câu trả lời vẫn đúng. Điều này khiến lợi thế về tốc độ đôi khi bị mất đi và chi phí tính toán không giảm như mong đợi.
Rõ ràng, cả hai hướng đi trên đều có hạn chế. Vì thế Google Research đã phát triển một phương pháp lai mới, mang tên speculative cascades. Cốt lõi ở đây là một quy tắc trì hoãn linh hoạt, có thể quyết định chấp nhận kết quả của mô hình nhỏ hoặc chuyển sang mô hình lớn tuỳ tình huống. Nhờ vậy, hệ thống tránh được điểm nghẽn “chờ đợi” của cascades và thoát khỏi sự khắt khe “loại cả bản nháp” của speculative decoding.
Nói cách khác, ngay cả khi mô hình nhỏ đưa ra đáp án không trùng khớp với mô hình lớn, hệ thống vẫn có thể chấp nhận nếu đó là câu trả lời hợp lý.
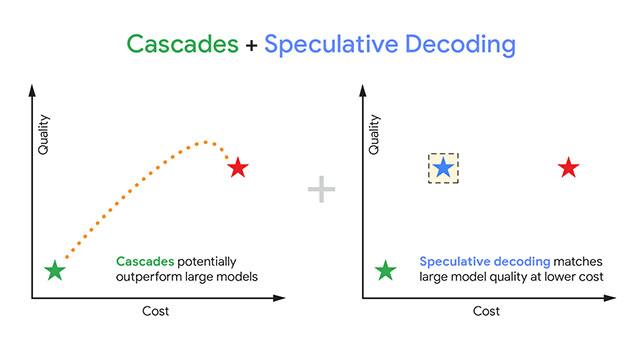
Google Research đã thử nghiệm phương pháp này trên các mô hình như Gemma và T5 với nhiều tác vụ ngôn ngữ khác nhau: tóm tắt văn bản, suy luận và viết code. Kết quả cho thấy speculative cascades đạt hiệu quả tốt hơn cả về chi phí – chất lượng, đồng thời tăng tốc độ xử lý so với các phương pháp truyền thống. Đặc biệt, trong nhiều trường hợp nó còn tạo ra đáp án chính xác nhanh hơn so với speculative decoding.
Hiện tại, đây mới chỉ là nghiên cứu trong phòng thí nghiệm. Nhưng nếu thành công và được triển khai thực tế, người dùng sẽ có cơ hội trải nghiệm LLM nhanh hơn, mạnh hơn và rẻ hơn đáng kể.







 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học