 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Jq là một chương trình phân tích cú pháp mạnh mẽ và có tính linh hoạt cao, có thể truyền và lọc dữ liệu JSON ra khỏi các file và đường dẫn UNIX. Bài viết này sẽ hướng dẫn bạn những kiến thức cơ bản về jq, trình bày các ví dụ cũng như một số cách triển khai thay thế mà bạn có thể áp dụng ngay hôm nay.
Mục lục bài viết
jq được sử dụng để làm gì?
Cách sử dụng phổ biến nhất của jq là để xử lý và thao tác các phản hồi JSON từ API Software-as-a-Service (SaaS). Ví dụ, bạn có thể sử dụng jq cùng với cURL để khai thác các điểm cuối API của Digitalocean nhằm lấy thông tin chi tiết về tài khoản.
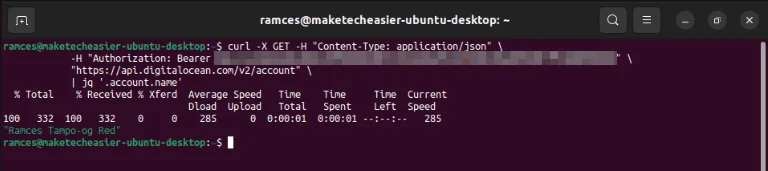
Ngoài ra, jq còn là một tiện ích mạnh mẽ để quản lý các file JSON lớn. Một số chương trình cơ sở dữ liệu phổ biến nhất hiện nay như MongoDB, PostgreSQL và MySQL hỗ trợ JSON như một cách để lưu trữ dữ liệu. Như vậy, việc học jq mang lại lợi thế trong việc hiểu cách các hệ thống cơ sở dữ liệu đó hoạt động.
Cài đặt và sử dụng jq
Để bắt đầu với jq, hãy cài đặt gói nhị phân của nó vào hệ thống:
sudo apt install jqTìm điểm cuối API mở mà bạn có thể kiểm tra jq. Trường hợp ví dụ sẽ sử dụng API kiểm tra IP của ipinfo.io.

Bộ lọc cơ bản nhất cho jq là bộ lọc dấu chấm (.). Lệnh sau sẽ xuất phản hồi JSON khi jq nhận được nó từ đầu vào tiêu chuẩn:
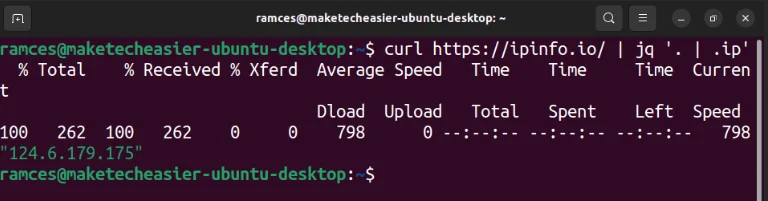
curl https://ipinfo.io/ | jq '.'Một bộ lọc cơ bản khác là ký hiệu (|). Đây là một bộ lọc đặc biệt chuyển đầu ra của một bộ lọc làm đầu vào của bộ lọc khác:
curl https://ipinfo.io/ | jq '. | .ip'Giá trị sau toán tử | là “Object Identifier-Index”. Thao tác này sẽ tìm kiếm đầu vào JSON để phát hiện bất kỳ biến nào khớp với văn bản của nó và in giá trị của nó trên terminal. Trường hợp ví dụ sau đang tìm giá trị của key “ip:”.
Với những điều cơ bản đã được thực hiện, các phần sau sẽ chỉ cho bạn một số thủ thuật có thể thực hiện khi sử dụng jq.
1. Tạo trình đọc nguồn cấp dữ liệu cơ bản với jq
Hầu hết các trang web hiện đại ngày nay đều cung cấp điểm cuối API mở để đọc dữ liệu bên trong nền tảng của họ. Ví dụ, mọi kho lưu trữ Github đều có URL API riêng để truy xuất các cam kết và vấn đề mới nhất cho dự án đó.
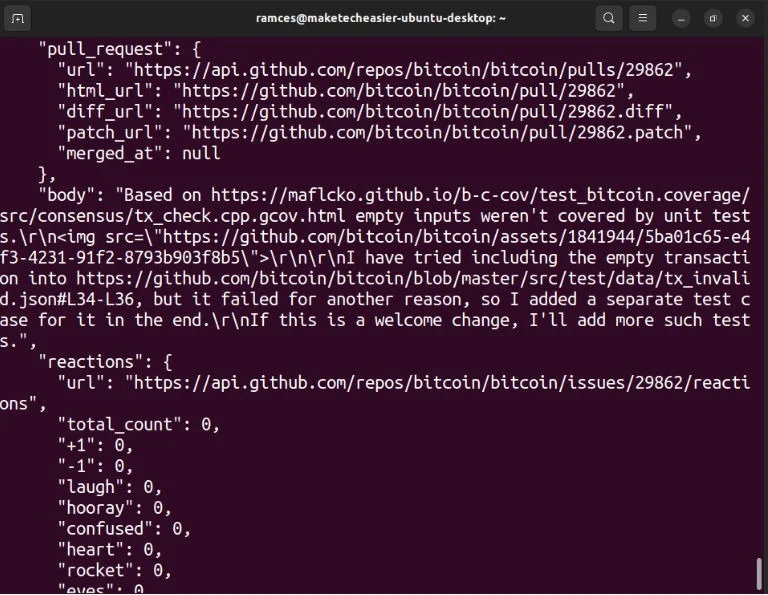
Bạn có thể sử dụng điểm cuối API như thế này với jq để tạo nguồn cấp dữ liệu “giống RSS” đơn giản của riêng mình. Để bắt đầu, hãy sử dụng cURL để kiểm tra xem điểm cuối có hoạt động tốt không:
curl https://api.github.com/repos/bitcoin/bitcoin/issuesChạy lệnh sau để in mục nhập đầu tiên trong nguồn cấp dữ liệu:
curl https://api.github.com/repos/bitcoin/bitcoin/issues | jq '.[0]'Điều này sẽ hiển thị các trường khác nhau mà API Github gửi tới jq. Bạn có thể sử dụng những thứ này để tạo đối tượng JSON tùy chỉnh của riêng mình bằng cách chuyển đầu vào tới bộ lọc dấu ngoặc nhọn ({}):
curl https://api.github.com/repos/bitcoin/bitcoin/issues | jq '.[0] | { title: .title }'Việc thêm bộ lọc dấu phẩy (,) bên trong dấu ngoặc nhọn cho phép thêm nhiều trường vào đối tượng tùy chỉnh:
curl https://api.github.com/repos/bitcoin/bitcoin/issues | jq '.[0] | {title: .title, url: .html_url, author: .user.login}'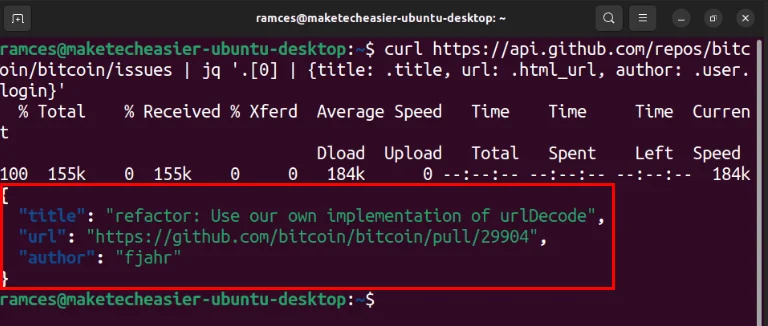
Việc xóa “0” bên trong dấu ngoặc vuông sẽ áp dụng bộ lọc jq cho toàn bộ nguồn cấp dữ liệu:
curl https://api.github.com/repos/bitcoin/bitcoin/issues | jq '.[] | {title: .title, url: .html_url, author: .user.login}'Bạn cũng có thể tạo một script Bash nhỏ để hiển thị các vấn đề mới nhất từ dự án Github yêu thích của mình. Dán block code sau vào trong file script shell trống:
#!/bin/bash<br><br># usage: ./script.sh [0 ... 29]<br><br>REPO="https://api.github.com/repos/bitcoin/bitcoin/issues"<br><br>curl $REPO | jq ".[$1] | {title: .title, url: .html_url, author: .user.login}"Lưu file, sau đó chạy lệnh sau để làm cho nó có thể thực thi được:
chmod u+x ./script.shKiểm tra trình đọc nguồn cấp dữ liệu mới bằng cách liệt kê vấn đề mới nhất trong kho lưu trữ Github yêu thích:
./script.sh 0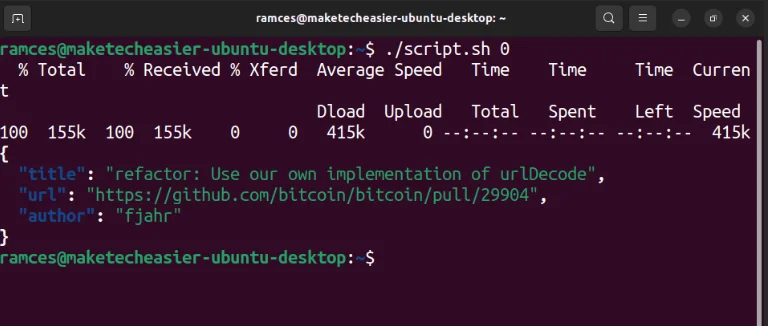
2. Đọc và tìm kiếm thông qua cơ sở dữ liệu JSON
Ngoài việc đọc dữ liệu từ API, bạn cũng có thể sử dụng jq để quản lý các file JSON trong máy cục bộ của mình. Bắt đầu bằng cách tạo một file cơ sở dữ liệu JSON đơn giản bằng trình soạn thảo văn bản yêu thích:
nano ./database.jsonDán khối dữ liệu sau vào file, sau đó lưu nó:
[<br> {"id": 1, "name": "Ramces", "balance": 20},<br> {"id": 2, "name": "Alice", "balance": 30},<br> {"id": 3, "name": "Bob", "balance": 10},<br> {"id": 4, "name": "Charlie", "balance": 20},<br> {"id": 5, "name": "Maria", "balance": 50}<br>]Kiểm tra xem jq có đọc đúng file JSON hay không bằng cách in đối tượng đầu tiên trong mảng cơ sở dữ liệu:
jq '.[0]' database.json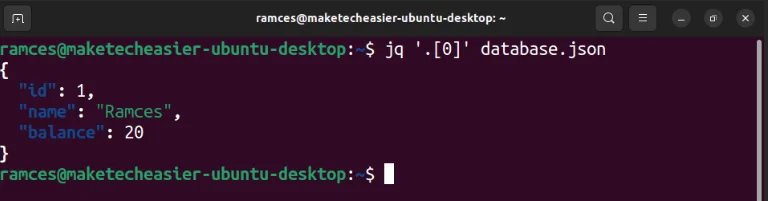
Thực hiện truy vấn trên cơ sở dữ liệu JSON bằng bộ lọc “Object Identifier-Index”. Trong trường hợp này, tác giả bài viết đang tìm kiếm giá trị của key “.name” trên mọi mục nhập trong cơ sở dữ liệu:
jq '.[] | .name' database.jsonBạn cũng có thể sử dụng một số hàm tích hợp của jq để lọc các truy vấn dựa trên những đặc tính nhất định. Ví dụ, có thể tìm kiếm và in tất cả các đối tượng JSON có giá trị “.name” nhiều hơn 6 ký tự:
jq '.[] | select((.name|length)>6)' database.json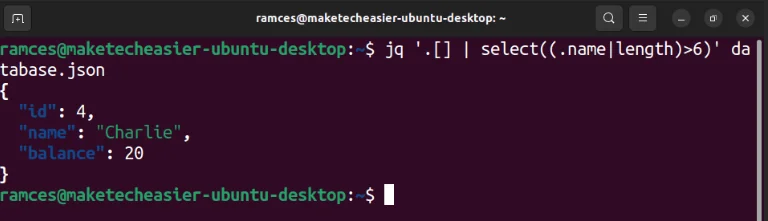
Hoạt động trên cơ sở dữ liệu JSON với jq
Ngoài ra, jq có thể hoạt động trên cơ sở dữ liệu JSON tương tự như bảng tính cơ bản. Ví dụ, lệnh sau in tổng của key “.balance” cho mọi đối tượng trong cơ sở dữ liệu:
jq '[.[] | .balance] | add' database.jsonBạn thậm chí có thể mở rộng điều này bằng cách thêm câu lệnh có điều kiện vào truy vấn của mình. Phần sau đây sẽ chỉ thêm “.balance” nếu giá trị “.name” của đối tượng thứ hai là “Alice”:
jq 'if .[1].name == "Alice" then [ .[] | .balance ] | add else "Second name is not Alice" end' database.json
Có thể tạm thời xóa các biến khỏi cơ sở dữ liệu JSON. Điều này có thể hữu ích nếu bạn đang kiểm tra bộ lọc và muốn đảm bảo rằng bộ lọc vẫn có thể xử lý tập dữ liệu:
jq 'del(.[1].name) | .[]' database.json
Bạn cũng có thể chèn các biến mới vào cơ sở dữ liệu bằng toán tử “+”. Ví dụ, dòng sau thêm biến “active: true” vào đối tượng đầu tiên trong cơ sở dữ liệu:
jq '.[0] + {active: true}' database.json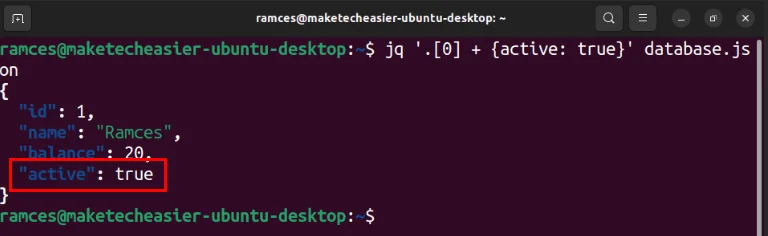
Lưu ý: Bạn có thể thực hiện các thay đổi vĩnh viễn bằng cách chuyển đầu ra của lệnh jq sang file cơ sở dữ liệu gốc:
jq '.[0] + {active: true}' database.json > database.json3. Chuyển đổi dữ liệu không phải JSON trong jq
Một tính năng tuyệt vời khác của jq là nó có thể chấp nhận và hoạt động với dữ liệu không phải JSON. Để đạt được điều đó, chương trình sử dụng một “slurp mode thay thế, trong đó nó chuyển đổi bất kỳ dữ liệu được phân tách bằng dấu cách và dòng mới nào thành một mảng JSON.
Bạn có thể kích hoạt tính năng này bằng cách chuyển dữ liệu vào jq bằng flag -s:
echo '1 2' | jq -s .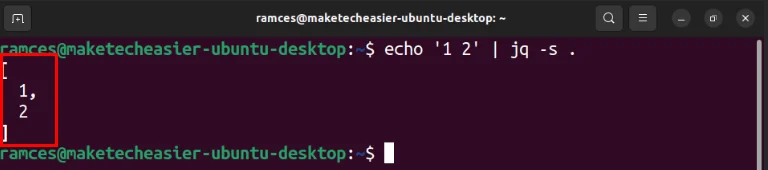
Một lợi thế của việc chuyển đổi dữ liệu thô thành một mảng là bạn có thể xử lý chúng bằng cách sử dụng số chỉ mục mảng. Lệnh sau thêm hai giá trị bằng cách tham chiếu đến vị trí mảng được chuyển đổi của chúng:
echo '1 2' | jq -s '.[0] + .[1]'Bạn có thể phát triển vị trí mảng này hơn nữa và xây dựng code JSON mới xung quanh nó. Chẳng hạn, code này chuyển đổi văn bản từ lệnh echo thành đối tượng JSON thông qua bộ lọc dấu ngoặc nhọn:
echo '6 "Mallory" 10' | jq -s '{"id": .[0], "name": .[1], "balance": .[2]}'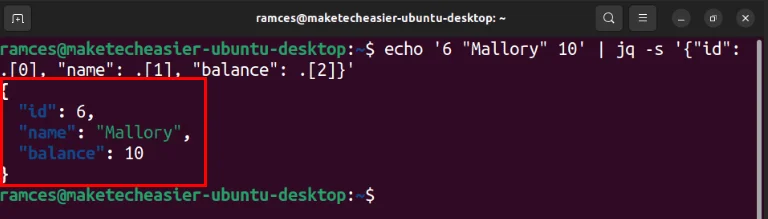
Ngoài việc lấy dữ liệu thô, jq còn có thể trả về dữ liệu không phải JSON làm đầu ra. Điều này hữu ích nếu bạn đang sử dụng jq như một phần của script shell lớn hơn và chỉ cần kết quả từ các bộ lọc của nó.
Để làm điều đó, hãy chạy jq theo sau là flag -r. Ví dụ, lệnh sau đọc tất cả tên từ file cơ sở dữ liệu và trả về dưới dạng dữ liệu plain text:
jq -r '.[] | .name' database.json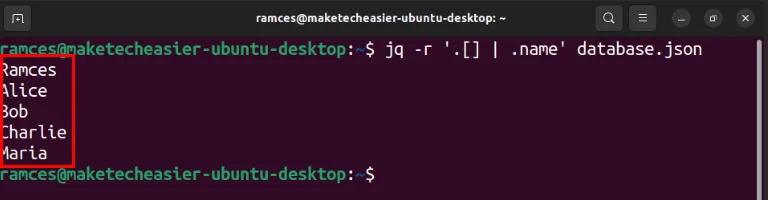
Trình phân tích cú pháp JSON thay thế cho jq
Vì code cho jq là mã nguồn mở nên nhiều nhà phát triển khác nhau đã tạo các phiên bản trình phân tích cú pháp JSON của riêng mình. Mỗi phiên bản trong số này đều có ưu điểm riêng nhằm cải thiện hoặc thay đổi phần cốt lõi của jq.
1. jaq
Jaq là một trình phân tích cú pháp JSON mạnh mẽ cung cấp tính năng gần giống hệt được đặt thành jq.
Được viết bằng Rust, một trong những ưu điểm lớn nhất của Jaq là nó có thể chạy ngôn ngữ jq nhanh hơn tới 30 lần so với trình phân tích cú pháp gốc, trong khi vẫn giữ được khả năng tương thích ngược. Chỉ riêng điều này đã khiến nó có giá trị khi chạy các bộ lọc jq lớn và muốn tối đa hóa hiệu suất của máy.
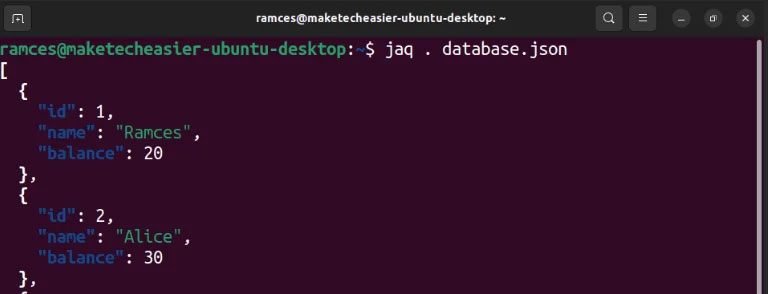
Tuy nhiên, một nhược điểm của jaq là nó hiện không có sẵn trên các kho Debian, Ubuntu và Fedora. Cách duy nhất để có được nó là tải xuống Homebrew hoặc biên dịch nó từ nguồn.
2. gojq
Gojq là một trình phân tích cú pháp JSON thay thế được viết hoàn toàn bằng Go. Nó cung cấp một phiên bản jq dễ sử dụng và tiếp cận mà bạn có thể cài đặt trên hầu hết mọi nền tảng.
Chương trình jq ban đầu có thể có các thông báo lỗi hết sức ngắn gọn. Do đó, việc gỡ lỗi các script jq đặc biệt khó khăn đối với người dùng jq mới. Gojq giải quyết vấn đề này bằng cách cho bạn biết lỗi nằm ở đâu trong script cũng như cung cấp thông báo chi tiết về loại lỗi đã xảy ra.
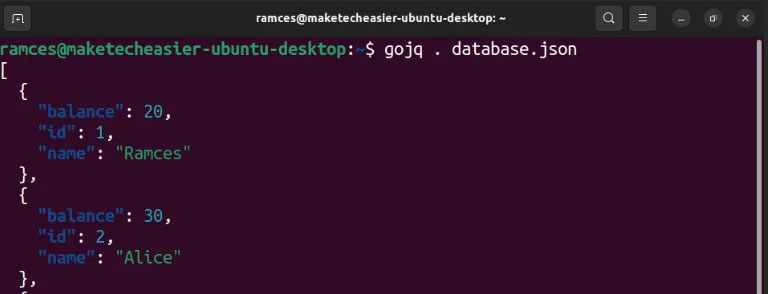
Một điểm hấp dẫn khác của gojq là nó có thể đọc và xử lý cả file JSON và YAML. Điều này có thể đặc biệt hữu ích nếu bạn là người dùng Docker và Docker Compose, muốn tự động hóa quy trình triển khai của mình.
Vấn đề lớn nhất của Gojq là nó đã loại bỏ một số tính năng mặc định trên trình phân tích cú pháp jq gốc. Ví dụ, các tùy chọn như --ascii-output, --seq và --sort-keys không tồn tại trên gojq.
3. fq
Không giống như jaq và gojq, fq là bộ công cụ phần mềm toàn diện có thể phân tích cú pháp cả dữ liệu văn bản và nhị phân. Nó có thể hoạt động với nhiều định dạng phổ biến như JSON, YAML, HTML và thậm chí FLAC.
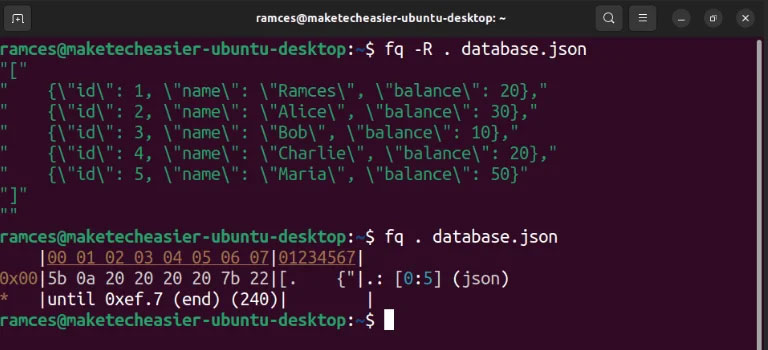
Tính năng lớn nhất của fq là nó chứa trình đọc hex tích hợp cho các file. Điều này khiến việc xem xét cấu trúc bên trong của file để xác định cách thức tạo ra file và liệu có điều gì sai sót với nó không là điều đơn giản. Ngoài ra, fq cũng sử dụng cú pháp tương tự cho jq khi xử lý văn bản, điều này giúp bất kỳ ai đã quen thuộc với jq đều dễ dàng tìm hiểu.
Một nhược điểm là fq vẫn đang được phát triển mạnh mẽ. Do đó, một số tính năng và hành vi của chương trình vẫn có thể thay đổi sâu rộng.
Khám phá jq, cách thức hoạt động và điều gì khiến nó trở nên đặc biệt chỉ là bước đầu tiên trong việc học cách tạo chương trình trên máy tính. Hãy đi sâu vào thế giới mã hóa tuyệt vời bằng cách đọc những điều cơ bản về lập trình shell.









 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học