 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích
Quản trị mạng – Trong hướng dẫn này chúng tôi sẽ giới thiệu cho các bạn một số phương pháp chuyển đổi các tài liệu XML thành các hàng trong các bảng quan hệ, công việc vẫn được biết đến như việc băm nhỏ hay phân tách các tài liệu XML.
Phương pháp chuyển đổi các tài liệu XML thành các hàng trong các bảng dữ liệu quan hệ hay được biết đến như việc shred (băm nhỏ) hay decompose (phân tách) các tài liệu XML. Một trong những lý do chính cho việc shred là các ứng dụng SQL đang tồn tại vẫn cần truy cập vào dữ liệu dưới định dạng quan hệ. Cho ví dụ, các ứng dụng kế thừa, các ứng dụng doanh nghiệp được đóng gói hoặc phần mềm báo cáo không phải lúc nào cũng làm việc với XML. Chính vì vậy đôi khi bạn sẽ thấy khá hữu dụng trong việc băm nhỏ (shred) tất cả hoặc một số giá trị dữ liệu của một tài liệu XML được chỉ định vào các cột và các hàng nằm trong các bảng dữ liệu quan hệ.
Hướng dẫn này chúng tôi sẽ giới thiệu cho các bạn về:
- Những ưu điểm và nhược điểm của việc băm nhỏ và các phương pháp băm nhỏ khác.
- Cách băm nhỏ dữ liệu XML thành các bảng quan hệ bằng lệnh INSERT có chứa hàm XMLTABLE.
- Cách sử dụng các chú thích XML Schema để bản đồ và băm nhỏ các tài liệu XML thành các bảng quan hệ.
Ưu điểm và nhược điểm của việc băm nhỏ
Khái niệm của việc băm nhỏ được minh chứng trong hình 1. Trong ví dụ này, các tài liệu XML có các thông tin về customer name, address, và phone được bản đồ hóa thành hai bảng quan hệ. Các tài liệu có thể chứa nhiều thành phần phone vì mối quan hệ giữa khách hàng và số điện thoại của họ là mối quan hệ 1-n. Do đó, các số điện thoại sẽ được băm nhỏ vào một bảng riêng. Mỗi một thành phần lặp, chẳng hạn như phone, sẽ dẫn đến một bảng bổ sung trong giản đồ mục tiêu quan hệ. Giả dụ các thông tin khách hàng có thể chứa nhiều địa chỉ email, nhiều tài khoản, danh sách các đơn đặt hàng gần đây, nhiều sản phẩm trong mỗi đơn hàng và các mục lặp lại khác. Khi đó số các bảng được yêu cầu trong giản đồ mục tiêu quan hệ có thể tăng rất nhanh. Tuy nhiên việc băm nhỏ XML thành một số lớn các bảng có thể dẫn đến sự phức tạp của các đối tượng logic doanh nghiệp và làm cho sự phát triển ứng dụng trở nên khó khăn hay rất dễ gây lỗi. Việc truy vấn dữ liệu đã được băm nhỏ hoặc việc lắp ráp lại (reassembling) các tài liệu gốc có thể cần đến nhiều mối ghép (join) phức tạp.
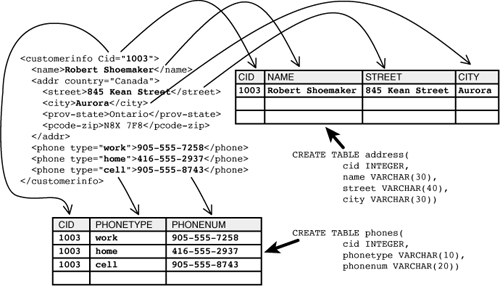
Hình 1: Việc băm nhỏ (shred) một tài liệu XML
Phụ thuộc vào sự phức tạp và khả năng thay đổi, mục đích của các tài liệu XML, việc băm nhỏ (shred) có hoặc không thể là một tùy chọn bắt buộc. Bảng 1 tóm tắt các ưu điểm và nhược điểm của việc băm nhỏ (shred) dữ liệu XML thành các bảng quan hệ.
|
Là lựa chọn thích hợp khi… |
Là lựa chọn không thích hợp khi… |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Bảng 1. Khi việc băm nhỏ là hay không là một lựa chọn thích hợp
Trong nhiều kịch bản ứng dụng XML, cấu trúc và cách sử dụng dữ liệu XML không thích ứng với việc băm nhỏ. Nguyên nhân xảy ra điều này là do DB2 hỗ trợ các cột XML có thể cho phép bạn đánh chỉ số và truy vấn dữ liệu mà không cần đến quá trình chuyển đổi. Đôi khi bạn sẽ thấy các yêu cầu ứng dụng của mình có thể đáp ứng tốt nhất với partial shredding hoặc hybrid XML storage. Ở đây:
- Partial shredding có nghĩa rằng chỉ một tập nhỏ các thành phần hoặc các thuộc tính từ mỗi một tài liệu XML đi vào được băm nhỏ thành các bảng quan hệ. Điều này khá hữu dụng nếu ứng dụng quan hệ không yêu cầu tất cả giá trị dữ liệu từ mỗi tài liệu XML. Trong các trường hợp, nơi việc băm nhỏ toàn bộ mỗi một tài liệu diễn ra khó khăn và yêu cầu một giản đồ quan hệ phức tạp, partial shredding có thể đơn giản hóa việc bản đồ hóa sang giản đồ quan hệ một cách đáng kể.
- Hybrid XML storage có nghĩa trong lúc chèn một tài liệu XML vào một cột XML, thành phần được chọn hoặc các giá trị của thuộc tính được trích rút và thành phần dự trữ được lưu trong các cột quan hệ.
Nếu bạn muốn băm nhỏ các tài liệu XML, toàn bộ hoặc một phần, DB2 cung cấp cho bạn một tập các tính năng phong phú để thực hiện một số hoặc tất cả những vấn đề dưới đây:
- Thực hiện các phép biến đổi giá trị dữ liệu trước khi chèn vào các cột quan hệ.
- Băm nhỏ cùng một giá trị thuộc tính hoặc thành phần vào nhiều cột của các bảng giống hay khác nhau.
- Băm nhỏ nhiều thành phần khác hay thuộc tính khác nhau vào cùng một cột trong một bảng.
- Chỉ định các điều kiện chi phối cho các thành phần nào đó được hay không được băm nhỏ. Cho ví dụ, băm nhỏ địa chỉ của một tài liệu khách hàng chỉ khi country là Canada.
- Hợp lệ hóa các tài liệu XML với một XML Schema trong suốt quá trình băm nhỏ.
- Lưu tài liệu XML đầy đủ cùng với dữ liệu được băm.
DB2 9 cho z/OS và DB2 9.x cho Linux, UNIX, và Windows hỗ trợ hai phương pháp băm nhỏ:
- Các câu lệnh INSERT của SQL sử dụng hàm XMLTABLE. Hàm này sẽ điều hướng vào một tài liệu đầu vào và sinh ra một hoặc nhiều hàng quan hệ dùng để chèn vào bảng quan hệ.
- Phân tách với một XML Schema được chú thích. Do XML Schema định nghĩa cấu trúc của các tài liệu XML nên các chú thích có thể được bổ sung vào giản đồ để định nghĩa cách các thành phần và thuộc tính được bản đồ hóa thành các bảng quan hệ như thế nào.
Bảng 2 và bảng 3 sẽ giới thiệu về những ưu điểm và nhược điểm của phương pháp XMLTABLE và phương pháp giản đồ được chú thích.
|
Ưu điểm của phương pháp XMLTABLE |
Nhược điểm của phương pháp XMLTABLE |
|
|
|
|
|
|
Bảng 2. Phương pháp XMLTABLE
| Ưu điểm của phương pháp | Nhược điểm của phương pháp |
|
|
|
|
|
|
Bảng 3: Phương pháp phân tách giản đồ chú thích
Băm nhỏ với hàm XMLTABLE
Hàm XMLTABLE là một hàm SQL sử dụng các biểu thức XQuery để tạo các hàng quan hệ từ một tài liệu đầu vào XML. Trong phần này chúng tôi sẽ miêu tả cho các bạn cách sử dụng hàm XMLTABLE trong câu lệnh để thực hiện việc băm nhỏ. Chúng ta sử dụng kịch bản băm nhỏ trong hình 1 làm ví dụ.
Bước đầu tiên chúng ta cần thực hiện là tạo một bảng quan hệ mục tiêu, nếu chưa có. Với kịch bản trong hình 1, các bảng mục tiêu được định nghĩa như bên dưới:
CREATE TABLE address(cid INTEGER, name VARCHAR(30),
street VARCHAR(40), city VARCHAR(30))
CREATE TABLE phones(cid INTEGER, phonetype VARCHAR(10),
phonenum VARCHAR(20))
Dựa vào định nghĩa của các bảng mục tiêu bạn có thể xây dựng các câu lệnh INSERT để băm nhỏ các tài liệu XML gửi vào. Các câu lệnh INSERT phải có dạng INSERT INTO ... SELECT ... FROM ... XMLTABLE, như thể hiện trong hình 2. Mỗi một hàm XMLTABLE đều gồm có một bộ marker tham số ("?"), thông qua đó một ứng dụng có thể chuyển qua (pass) tài liệu XML được băm nhỏ. Các rule SQL yêu cầu bộ marker tham số phải biến đổi thành kiểu dữ liệu thích hợp. Mệnh đề SELECT sẽ chọn các cột được tạo ra bởi hàm XMLTABLE nhằm chèn vào các bảng address và phones một cách tương ứng.
INSERT INTO address(cid, name, street, city) SELECT x.custid, x.custname, x.str, x.place FROM XMLTABLE('$i/customerinfo' PASSING CAST(? AS XML) AS "i"
COLUMNS custid INTEGER PATH '@Cid', custname VARCHAR(30) PATH 'name', str VARCHAR(40) PATH 'addr/street', place VARCHAR(30) PATH 'addr/city' ) AS x ; INSERT INTO phones(cid, phonetype, phonenum) SELECT x.custid, x.ptype, x.number FROM XMLTABLE('$i/customerinfo/phone'
PASSING CAST(? AS XML) AS "i" COLUMNS custid INTEGER PATH '../@Cid', number VARCHAR(15) PATH '.', ptype VARCHAR(10) PATH './@type') AS x ; |
Hình 2: Chèn thành phần XML và các giá trị của thuộc tính vào các cột quan hệ
Để cư trú hai bảng mục tiêu như được minh chứng trong hình 1, cả hai câu lệnh INSERT đều phải được thực thi với cùng một tài liệu XML đầu vào. Một phương pháp được thực hiện ở đây là ứng dụng phát cả hai câu lệnh trong một giao dịch (transaction) và đóng kết tài liệu XML giống nhau vào các bộ marker tham số cho cả hai câu lệnh. Phương pháp này làm việc tốt tuy nhiên có thể được tối ưu, vì tài liệu XML giống nhau được gửi từ máy khách đến máy chủ và được phân tách tại máy chủ DB2 hai lần, mỗi lần cho một câu lệnh INSERT. Quá trình này có thể tránh bằng cách kết hợp cả hai câu lệnh INSERT trong một thủ tục lưu trữ. Ứng dụng chỉ tạo một cuộc gọi thủ tục lưu trữ và pass tài liệu đầu vào một lần, và không quan tâm đến số lượng của các câu lệnh trong thủ tục lưu trữ.
Cách khác, các câu lệnh INSERT trong hình 2 có thể đọc một tập các tài liệu đầu vào từ cột XML. Giả dụ các tài liệu được load vào cột XML info trong bảng customer. Sau đó bạn cần thay đổi một dòng trong mỗi câu lệnh INSERT trong hình 2 để đọc tài liệu đầu vào từ bảng customer:
FROM customer, XMLTABLE('$i/customerinfo' PASSING info AS "i"
Việc load các tài liệu đầu vào vào bảng có thể khá thuận lợi nếu bạn phải băm nhỏ nhiều tài liệu. Tiện ích LOAD sẽ hoàn trả song song quá trình phân tách cú pháp XML, làm giảm được thời gian chuyển các tài liệu vào cơ sở dữ liệu. Khi các tài liệu được lưu trong một cột XML dưới định dạng đã được phân tách, hàm XMLTABLE có thể băm nhỏ các tài liệu mà không cần phân tách XML.
Câu lệnh INSERT có thể được làm phong phú hơn các hàm Xquery, SQL hoặc join để thích ứng quá trình băm nhỏ với các yêu cầu cụ thể. Hình 3 cung cấp cho các bạn một ví dụ. Mệnh đề SELECT gồm có hàm RTRIM có nhiệm vụ remove các chỗ trống phía sau khỏi cột x.ptype. Biểu thức tạo hàng của hàm XMLTABLE có chứa thuộc tính dùng để ngăn chặn các số điện thoại gia đình bị băm nhỏ vào bảng mục tiêu. Biểu thức tạo cột cho các số điện thoại sử dụng hàm XQuery normalize-space, dùng để tách phần không gian trắng ở đầu và đuôi và thay thế mỗi một chuỗi bên trong của các ký tự trắng bằng một ký tự trống. Câu lệnh cũng thực hiện một hành động join cho bảng tra cứu areacodes để số điện thoại được chèn vào bảng phones chỉ khi mã vùng của nó được liệt trong bảng areacodes.
INSERT INTO phones(cid, phonetype, phonenum) SELECT x.custid, RTRIM(x.ptype), x.number FROM areacodes a, XMLTABLE('$i/customerinfo/phone[@type != "home"]'
PASSING CAST(? AS XML) AS "i" COLUMNS custid INTEGER PATH '../@Cid', number VARCHAR(15) PATH 'normalize-space(.)', ptype VARCHAR(10) PATH './@type') AS x WHERE SUBSTR(x.number,1,3) = a.code; |
Hình 3: Sử dụng các hàm và join để điều chỉnh quá trình băm
Hybrid XML Storage
Trong nhiều tình huống, sự phức tạp của cấu trúc tài liệu XML có thể làm cho việc băm nhỏ trở nên khó khăn, không hiệu quả và gây phiền phức. Bên cạnh sự bất lợi về mặt hiệu suất của việc băm nhỏ, việc phân tán các giá trị của tài liệu XML trong một số lượng lớn các bảng có thể làm cho chuyên gia phát triển ứng dụng khó khăn trong việc hiểu và truy vấn dữ liệu. Để cải thiện hiệu suất chèn XML và giảm số lượng bảng trong cơ sở dữ liệu, bạn có thể lưu các tài liệu XML dưới dạng Hybrid XML Storage. Phương pháp này sẽ trích rút các giá trị hoặc các thuộc tính của các thành phần XML được chọn và lưu chúng vào các cột quan hệ bên cạnh tài liệu XML.
Ví dụ trong phần trước đã sử dụng hai bảng, address và phones, là các bảng mục tiêu cho việc băm nhỏ các tài liệu khách hàng. Tuy nhiên bạn có thể chỉ sử dụng một bảng có chứa các giá trị cid, name, và city của khách hàng trong các cột quan hệ và tài liệu XML đầy đủ với các thành phần lặp phone, còn các thông tin khác trong một cột XML. Nếu vậy bạn có thể định nghĩa bảng như dưới đây:
CREATE TABLE hybrid(cid INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(30), city VARCHAR(25), info XML)
Hình 4 thể hiện câu lệnh INSERT để cư trú bảng này. Hàm XMLTABLE sử dụng tài liệu XML như một dữ liệu đầu vào thông qua một bộ marker tham số. Định nghĩa cột trong hàm XMLTABLE sẽ sinh 4 cột tương xứng với định nghĩa của bảng mục tiêu hybrid. Biểu thức tạo hàng trong hàm XMLTABLE $i sẽ tạo một tài liệu đầu vào đầy đủ. Biểu thức này là đầu vào cho các biểu thức tạo cột trong mệnh đề COLUMNS của hàm XMLTABLE. Cá biệt, biểu thức cột '.' sẽ trả về tài liệu đầu vào đầy đủ và tạo cột XML doc nhằm chèn vào cột info trong bảng mục tiêu.
INSERT INTO hybrid(cid, name, city, info) SELECT x.custid, x.custname, x.city, x.doc FROM XMLTABLE('$i' PASSING CAST(? AS XML) AS "i"
COLUMNS custid INTEGER PATH 'customerinfo/@Cid', custname VARCHAR(30) PATH 'customerinfo/name', city VARCHAR(25) PATH 'customerinfo/addr/city', doc XML PATH '.' ) AS x; |
Hình 4: Lưu một tài liệu XML theo kiểu hybrid
Hiện tại bạn sẽ không thể định nghĩa các ràng buộc (constraint) trong BD2 để thực thi tính toàn vẹn giữa các cột và các giá trị quan hệ trong một tài liệu XML ở cùng một hàng. Mặc dù vậy bạn lại có thể định nghĩa các bẫy sự kiện (trigger) INSERT và UPDATE trên bảng để cư trú các cột quan hệ một cách tự động bất cứ khi nào một tài liệu được chèn hoặc được cập nhật.
Việc test các câu lệnh INSERT trong DB2 Command Line Processor (CLP) sẽ rất hữu dụng. Với mục đích này, bạn có thể thay thế bộ marker tham số bằng một tài liệu XML thông thường như thể hiện trong hình 5. Tài liệu thường này là một chuỗi được phân biệt bằng dấu ngoặc đơn và được chuyển đổi thành kiểu dữ liệu XML với hàm XMLPARSE. Một cách khác nữa là bạn có thể đọc tài liệu đầu vào từ hệ thống file bằng một trong các UDP, các UDP này được minh chứng trong hình 6.
INSERT INTO hybrid(cid, name, city, info) SELECT x.custid, x.custname, x.city, x.doc FROM XMLTABLE('$i' PASSING
XMLPARSE(document '<customerinfo Cid="1001"> <name>Kathy Smith</name> <addr country="Canada"> <street>25 EastCreek</street> <city>Markham</city> <prov-state>Ontario</prov-state> <pcode-zip>N9C 3T6</pcode-zip> </addr> <phone type="work">905-555-7258</phone> </customerinfo>') AS "i" COLUMNS custid INTEGER PATH 'customerinfo/@Cid', custname VARCHAR(30) PATH 'customerinfo/name', city VARCHAR(25) PATH 'customerinfo/addr/city', doc XML PATH '.' ) AS x; |
Hình 5: Hybrid chèn câu lệnh bằng một tài liệu XML thường
INSERT INTO hybrid(cid, name, city, info) SELECT x.custid, x.custname, x.city, x.doc FROM XMLTABLE('$i' PASSING
XMLPARSE(document blobFromFile('/xml/mydata/cust0037.xml')) AS "i"
COLUMNS custid INTEGER PATH 'customerinfo/@Cid', custname VARCHAR(30) PATH 'customerinfo/name', city VARCHAR(25) PATH 'customerinfo/addr/city', doc XML PATH '.' ) AS x; |
Hình 6: Hybrid chèn câu lệnh bằng một "FromFile" UDF
Logic chèn trong hình 4 và 5 và hình 6 hoàn toàn giống nhau. Chỉ có một sự khác biệt là cách tài liệu đầu vào được cung cấp như thế nào: thông qua bộ marker tham số, như chuỗi thông thường được phân biệt bằng dấu ngoặc đơn hoặc thông qua một UDP đọc tài liệu từ hệ thống file.
Các khung nhìn (View) quan hệ trên dữ liệu XML
Bạn có thể tạo các khung nhìn quan hệ trên dữ liệu XML bằng cách sử dụng các biểu thức XMLTABLE. Điều này cho phép bạn cung cấp các ứng dụng có khung nhìn quan hệ hoặc hybrid đối với dữ liệu XML mà không cần phải lưu dữ liệu dưới định dạng quan hệ hoặc hybrid. Cách thức này rất hữu dụng nếu bạn muốn tránh sự phức tạp trong quá trình chuyển đổi một số lượng lớn dữ liệu XML thành định dạng quan hệ. Cấu trúc cơ bản SELECT ... FROM ... XMLTABLE được sử dụng trong câu lệnh INSERT ở phần trước cũng có thể được sử dụng trong các câu lệnh CREATE VIEW.
Lấy một ví dụ, giả dụ bạn muốn tạo một khung nhìn quan hệ cho các thành phần của các tài liệu XML trong bảng customer để trưng bày ra các giá trị định danh, tên, đường phố và thành phố (identifier, name, street, và city) của khách hàng. Hình 7 thể hiện định nghĩa khung nhìn tương ứng cộng với một truy vấn SQL cho khung nhìn.
CREATE VIEW custview(id, name, street, city) AS SELECT x.custid, x.custname, x.str, x.place FROM customer, XMLTABLE('$i/customerinfo' PASSING info AS "i"
COLUMNS custid INTEGER PATH '@Cid', custname VARCHAR(30) PATH 'name', str VARCHAR(40) PATH 'addr/street', place VARCHAR(30) PATH 'addr/city' ) AS x; SELECT id, name FROM custview WHERE city = 'Aurora'; ID NAME ----------- ------------------------------ 1003 Robert Shoemaker 1 record(s) selected. |
Hình 7: Việc tạo một khung nhìn cho dữ liệu XML
Truy vấn trên khung nhìn trong hình 7 gồm một thuộc tính SQL cho cột city trong khung nhìn. Các giá trị trong cột city đến từ một thành phần XML trong cột XML ở dưới. Bạn có thể tăng tốc cho truy vấn này bằng cách tạo một XML index trên /customerinfo/addr/city cho cột info của bảng customer. DB2 9 cho z/OS và DB2 9.7 cho Linux, UNIX, và Windows có thể chuyển đổi thuộc tính quan hệ city = 'Aurora' thành thuộc tính XML trong cột XML ở dưới để có thể sử dụng XML index. Tuy nhiên điều này không thể thực hiện trong DB2 9.1 và DB2 9.5 cho Linux, UNIX, và Windows. Trong các phần trước của BD2, nhóm cột XML trong định nghĩa khung nhìn và ghi điều kiện tìm kiếm như một thuộc tính XML, xem trong truy vấn dưới đây. Nếu không sẽ không thể sử dụng XML index.
SELECT id, name
FROM custview
WHERE XMLEXISTS('$INFO/customerinfo/addr[city = "Aurora"]')
(Còn nữa)






 Lập trình
Lập trình
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học