 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

SQL Server 2017 được phát hành chính thức vào tháng 10/2017. Những phần đầu tiên của SQL Server 2017 đã được tung ra từ cuối năm 2016, tính đến cuối năm 2017 nó đã có 10 bản phát hành.
Phiên bản SQL Server 2017 chủ yếu kết nối với Linux, mang sức mạnh của SQL lên Linux. Để nói ngắn gọn thì bạn có thể cài SQL Server 2017 trên Linux, sử dụng SQL Server 2017 trên docker container dựa trên Linux. SQL Server 2017 cũng cho phép lựa chọn ngôn ngữ phát triển, phát triển nó tại chỗ (on-premise) hoặc dựa trên đám mây.
Trong bản này, SQL Server 2017 cũng cải thiện hiệu suất, khả năng mở rộng và các tính năng trong từng phần như Database Engine, Integration Services, Master Data Services, Analysis Services, v.v... Trong bài viết này chúng ta sẽ xem xét qua từng phần một.
Tính năng mới của SQL Server 2017
- Tính năng mới trong Database Engine
- Tính năng mới trong Graph DB
- Always Available (truy cập dữ liệu chéo)
- Cải tiến về DTA
- Hàm chuỗi (string) mới
- Có gì mới trong SSRS (Reporting Services) của SQL 2017
- Có gì mới ở SSIS (Dịch vụ tích hợp) trong SQL 2017
- Dịch vụ phân tích trong (SSAS) trong SQL 2017 có gì mới
- Machine Learning
- Hỗ trợ Linux
Tính năng mới trong Database Engine
identity_cache

Tùy chọn này giúp bạn tránh những sai lệch về giá trị của cột ID, trong trường hợp máy chủ tắt đột ngột hoặc tiến hành chuyển đổi dự phòng, hay thậm chí chuyển sang máy chủ phụ. Nó được sử dụng với lệnh ALTER DATABASE SCOPED CONFIGURATION, để kích hoạt các thiết lập cấu hình cơ sở dữ liệu. Cú pháp như sau:
ALTER DATABASE SCOPED CONFIGURATION
{
{ [ FOR SECONDARY] SET <set_options> }
}
| CLEAR PROCEDURE_CACHE
| SET < set_options >
[;]
< set_options > ::=
{
MAXDOP = { <value> | PRIMARY}
| LEGACY_CARDINALITY_ESTIMATION = { ON | OFF | PRIMARY}
| PARAMETER_SNIFFING = { ON | OFF | PRIMARY}
| QUERY_OPTIMIZER_HOTFIXES = { ON | OFF | PRIMARY}
| IDENTITY_CACHE = { ON | OFF }
}
Cải thiện xử lý truy vấn thích ứng
Nếu bạn muốn cải thiện hiệu suất thực thi truy vấn thì tính năng mới này sẽ giúp ích đáng kể. Nó được hỗ trợ trong SQL Server và Azure SQL Database.
Đây là quy trình tối ưu hóa thông thường khi thực thi truy vấn SQL:
- Đầu tiên, trình tối ưu hóa truy vấn sẽ tính toán tất cả các kế hoạch thực hiện truy vấn khả thi cho truy vấn vừa tạo.
- Tiếp theo, nó sẽ đưa ra kế hoạch tối ưu nhất/nhanh nhất.
- Cuối cùng, kế hoạch được ước tính là tối ưu nhất sẽ được chọn để thực thi truy vấn và quá trình thực hiện sau đó sẽ bắt đầu.
Quá trình trên có những nhược điểm sau:
- Nếu ước tính sai kế hoạch tối ưu nhất thì sẽ ảnh hưởng đến hiệu suất.
- Nếu không đủ bộ nhớ được cấp phát cho việc thực thi kế hoạch tối ưu thì sẽ xảy ra lỗi tràn bộ nhớ.
Dưới đây là những tính năng mà SQL Server 2017 đã đưa vào để khắc phục những nhược điểm trên:
Batch Mode Memory Grant Feedback (Phản hồi về việc cấp phát bộ nhớ cho chế độ hàng loạt): Phản hồi này sẽ tính toán lại bộ nhớ được yêu cầu cho việc thực thi kế hoạch và cấp phát bộ nhớ cho nó từ cache.
Batch Mode Adaptive Joins (Join thích ứng với chế độ hàng loạt): Có 2 kiểu join là Hash và vòng lặp lồng nhau. Khi truy kế hoạch thực hiện được nhập vào và quét lần đầu, nó sẽ quyết định xem sẽ áp dụng kiểu join nào để có được output ở tốc độ tối ưu.
Interleaved Execution (Thực thi xen kẽ): Trong quá trình thực thi kế hoạch tối ưu, tính năng này sẽ "pause" khi gặp những hàm kiểu bảng đa lệnh (multi-stament table valued function) để chỉ tính toán hoàn hảo các yếu tố trong bảng này, rồi sau đó mới tiếp tục tối ưu hóa.
Automatic Tuning
Tính năng này kiểm tra các vấn đề trong hiệu suất truy vấn, xác định chúng và khắc phục bằng những giải pháp được đề xuất. Đây là những kỹ thuật automactic tuning (tự động điều chỉnh) có sẵn trong tính năng này:
Automatic Correction (Plan): Kỹ thuật này có trong SQL 2017 Database, nó sẽ tìm những vấn đề về hiệu suất trong kế hoạch truy vấn được đưa ra, sau đó sửa chữa chúng với những giải pháp được đề xuất.
Automatic Management (Index): Kỹ thuật này có trong SQL 2017 Azure DB, nó sẽ xác định và sửa thứ tự các chỉ mục bằng cách xóa chỉ mục chưa chuẩn và thêm chỉ mục đúng vào
Tính năng mới trong Graph DB
Graph DB là gì?
Về cơ bản, Graph DB là một tập hợp các nút và cạnh, cạnh biểu thị cho mối quan hệ giữa các nút, nút là thực thể, một cạnh có thể nối với nhiều nút. Graph DB hoạt động giống như một cơ sở dữ liệu quan hệ, và bạn có thể sử dụng nó trong những trường hợp sau:
- Khi có cơ sở dữ liệu ở định dạng phân cấp (hierarchical) và muốn lưu nhiều parent cho một nút.
- Khi cần kiểm tra và phân tích quan hệ liên kết và dữ liệu.
- Khi có nhiều quan hệ (relationship).
Ở đây, từ khóa MATCH được sử dụng để truy vấn bảng Graph và sắp xếp dữ liệu, với sự trợ giúp của một truy vấn duy nhất, người dùng có thể truy vấn trên biểu đồ và dữ liệu quan hệ.
Always Available (truy cập dữ liệu chéo)
Với sự trợ giúp của tính năng này, giờ đây việc trao đổi chéo các cơ sở dữ liệu giữa các SQL instance khác nhau (một SQL instance có thể kết nối được với cácSQL instance khác) là hoàn toàn khả thi. Nó cũng hỗ trợ cho việc trao đổi các cơ sở dữ liệu phân tán. [SQL 2016 cũng hỗ trợ truy cập cơ sở dữ liệu chéo nhưng chỉ giữa các cá thể trong cùng một SQL Server.]
Cải tiến về DTA
Trong SQL 2017, đã có cải thiện về hiệu suất trong Database tuning advisor (DTA). Cụ thể là các tùy chọn cho DTA đã được bổ sung thêm.
Nếu bạn chưa biết DTA là gì thì:
DTA là công cụ cơ sở dữ liệu thực hiện kiểm tra quá trình truy vấn (đã được xử lý) sau đó đưa ra những cách thức giúp bạn cải thiện hiệu suất hoạt động, có thể là bằng cách thay đổi cấu trúc cơ sở dữ liệu (ví dụ: chỉ mục, khóa). Có thể sử dụng DTA theo hai cách sau đây:
- Sử dụng GUI (giao diện)
- Sử dụng tiện ích lệnh
Hàm chuỗi (string) mới
SQL 2017 mang đến cho người dùng một số hàm chuỗi mới như TRANSLATE, CONCAT_WS, STRING_AGG, TRIM. Hãy cùng tìm hiểu từng hàm một.
TRANSLATE
Về cơ bản hàm này lấy một chuỗi kí tự làm dữ liệu đầu vào và sau đó chuyển các ký tự này sang một số ký tự mới, xem cú pháp dưới đây:
TRANSLATE ( inputString, characters, translations)
Trong cú pháp trên chiều dài của 'characters' phải tương tự như trong 'translations', nếu không hàm trên sẽ trả về giá trị lỗi. Ví dụ:
TRANSLATE ('6*{10+10}/[6-4]','[]{}','()()')
Kết quả trả về của ví dụ trên sẽ là 6 * (10 + 10) / (6-4). Chúng ta có thể thấy các dấu ngoặc nhọn và ngoặc vuông được chuyển thành các dấu ngoặc tròn.
Hàm này có cơ chế hoạt động giống như hàm REPLACE nhưng cách sử dụng đơn giản hơn để thay cho hàm REPLACE. Ví dụ nếu chúng ta muốn có kết quả trả về như trên mà sử dụng hàm REPLACE, thì chúng ta phải viết hàm như sau, mới nhìn thôi đã thấy không hề dễ hiểu chút nào:
SELECT REPLACE(REPLACE(REPLACE(REPLACE('6*{10+10}/[6-4]','{','('), '}', ')'), '[', '('), ']', ')');
CONCATE_WS
Chức năng của hàm này chỉ đơn giản là ghép nối tất cả các đối số đầu vào với các dấu phân cách được chỉ định. Hãy tham khảo cú pháp dưới đây:
CONCAT_WS ( separator, argument1, argument1 [, argumentN]… )
Hàm này tạo ra những chuỗi đơn bằng cách nối tất cả các đối số với nhau nhờ vào sự trợ giúp của các dấu phân tách, do vậy nó cần tối thiểu 2 đối số để tạo ra kết quả đầu ra, nếu không kết quả trả về sẽ lỗi. Ví dụ:
SELECT CONCAT_WS(',','Count numers', 'one', 'two', 'three', 'four' ) AS counter;
Kết quả trả về của lệnh trên sẽ là: one, two, three, four
Bạn cũng có thể sử dụng tên cột cơ sở dữ liệu thay vì các chuỗi được mã hóa.
TRIM
Cuối cùng thì hàm này cũng đã xuất hiện trên SQL 2017. Về cơ bản thì nó hoạt động giống như hàm trim của C#, tức là loại bỏ tất cả các khoảng trống thừa ở phần đầu và cuối chuỗi. Cú pháp như sau:
SELECT TRIM(' trim me ') AS result;
Kết quả trả về của lệnh trên sẽ là: trim me
Hàm này sẽ không loại bỏ các khoảng trống nằm giữa chuỗi.
STRING_AGG
Hàm này nối các giá trị của chuỗi với sự trợ giúp của các dấu phân tách trong khi không thêm dấu phân tách ở cuối chuỗi. Dữ liệu đầu vào có thể là VARCHAR, NVARCHAR, bạn có thể tùy ý chỉ định thứ tự hiển thị của kết quả bằng việc sử dụng mệnh đề WITHIN GROUP.
Xem cú pháp dưới đây:
STRING_AGG ( expression, separator ) [ <order_clause> ]
<order_clause> ::=
WITHIN GROUP ( ORDER BY <order_by_expression_list> [ ASC | DESC ] )
Mời bạn tham khảo ví dụ sau đây:
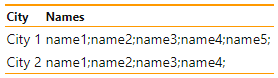
SELECT city,
STRING_AGG (name, ';') WITHIN GROUP (ORDER BY name ASC) AS names
FROM Students GROUP BY city;
Trong ví dụ trên, tất cả tên đã được ghép nối và phân tách bằng dấu chấm phẩy (;). Mệnh đề WITHIN GROUP giúp chúng ta sắp xếp theo thứ tự. Kết quả trả về sẽ được hiển thị như sau:
Có gì mới trong SSRS (Reporting Services) của SQL 2017
- Từ bây giờ trở đi, thiết lập SSRS không còn có sẵn trên thiết lập của SQL Server, bạn cần phải tải xuống từ kho download [tại đây].
- Từ bây giờ, Query designer sẽ hỗ trợ DAX. Các truy vấn DAX nguyên bản sẽ có thể được tạo ra để ngăn chặn SSAS (các dịch vụ phân tích). Tính năng này sẽ xuất hiện trên bản cập nhật mới nhất của các công cụ SQL và trình xây dựng báo cáo.
- Các lệnh OpenAPI được hỗ trợ bởi RESTful API, và giờ đây, RESTful API lại được hỗ trợ bởi SSRS.
- Từ bây giờ, bạn có thể đính kèm thêm tệp vào các nhận xét của mình.
- Bạn cũng có thể thêm nhận xét vào các báo cáo.
- Cổng thông tin dịch vụ báo cáo đã được nâng cấp đáng kể (tính năng này đã có sẵn trong SQL 2016).
Có gì mới ở SSIS (Dịch vụ tích hợp) trong SQL 2017
Từ bây giờ bạn có thể thực hiện SSIS trên Linux, tăng thêm khối lượng, cũng như trích xuất và chuyển đổi dữ liệu trực tiếp trên Linux.
Tính năng mở rộng quy mô cho phép các hệ thống tích hợp phức tạp với nhiều máy có hiệu năng cao. Tính năng mở rộng quy mô có thể thực hiện tất cả các hoạt động với sự trợ giúp của Scale Out Master và Scale Out Workers.
Dịch vụ phân tích trong (SSAS) trong SQL 2017 có gì mới
- Giao diện mới của Get Data được ra mắt trên SQL 2017 tương tự như MS Excel, power BI. Ngoài ra tính năng data transformation và data mashup cũng đã xuất hiện, bạn có thể làm điều đó bằng cách sử dụng trình tạo truy vấn và biểu thức M.
- Tabular mode cho SSAS - một đế độ được giới thiệu trong SQL 2012, giờ đã được nâng cấp mạnh mẽ hơn trong SQL 2017.
- SQL 2017 đưa ra tính năng Encoding hints mới, được sử dụng để tối ưu hóa dữ liệu bảng trong bộ nhớ lớn.
- Cải thiện hiệu suất cho PIVOT.
Machine Learning
Chúng ta đều biết rằng SQL 2016 hiện đang hỗ trợ các dịch vụ R, và từ bây giờ, dịch vụ này sẽ được đổi tên thành các dịch vụ SQL Server Machine learning. Lợi ích từ sự thay đổi này là bạn có thể dễ dàng sử dụng hệ thống các lệnh R hoặc Python trên SQL Server.
Với tính năng mới này, Python có thể chạy được trong những thủ tục đã lưu. Thậm chí bạn có thể thực thi lệnh từ xa thông qua SQL Server, điều này sẽ thực sự hữu ích cho các nhà phát triển Python. Tuy nhiên, tính năng này hiện tại vẫn chưa được hỗ trợ trên Linux, hãy cùng chờ đợi ở những bản nâng cấp tiếp theo.
Để sử việc dụng machine learning một cách trở lên hiệu quả và tối ưu hơn, SQL sử dụng các giải pháp sau:
- revoscalepy là một loại thư viện mới có nhiệm vụ làm nền tảng cho các thuật toán hiệu năng cao, các tính toán và tình huống từ xa. Về cơ bản revoscalepy dựa trên nền tảng RevoScaleR (một gói dịch vụ R).
- microsoftml là cụm máy chủ Microsoft R hỗ trợ các thuật toán theo ngôn ngữ máy, Microsoft đã phát triển thư viện này cho machine learning nội bộ. Nhưng qua nhiều năm, nó đã được cải tiến và hiện tại microsoftml hỗ trợ truyền dữ liệu nhanh cũng như chuyển đổi các văn bản lớn, v.v...
Hỗ trợ Linux
Về cơ bản, ngay từ tên gọi "SQL 2017 on Linux and Windows" ta đã có thể biết được rằng mục đích chính của bản nâng cấp này là hỗ trợ cho việc phát hành sản phẩm trên nền tảng Linux. Dưới đây là một vài tính năng chính của "SQL trên Linux":
- Khả năng lưu trữ cơ sở dữ liệu lõi
- Hỗ trợ IPV6
- Hỗ trợ NFS
- Xác thực AD trên linux
- Hỗ trợ mã hóa
- Có thể cài đặt SSIS trên Linux
- Có sẵn công cụ lệnh MSSQL-conf
- Liền mạch hóa và tự do hóa quá trình cài đặt
- SQL cho Visual studio core (VS core đã có trên Linux)
- Trình tạo tập lệnh nền tảng chéo
Tổng kết
Sẽ còn rất nhiều điều để nói và tìm hiểu về SQL Server, chúng ta sẽ tiếp tục cuộc hành trình này trong trong những phần tiếp theo. Đừng ngần ngại đặt ra những ý kiến đóng góp và thắc mắc!
Xem thêm:






 Lập trình
Lập trình
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học