 AI
AI  ChatGPT
ChatGPT  Gemini
Gemini  Thư viện Prompt
Thư viện Prompt  Công nghệ
Công nghệ  Học IT
Học IT  Tiện ích
Tiện ích 
TensorRT là Bộ công cụ phát triển phần mềm (SDK) học sâu (deep learning) do Nvidia phát triển. Nó cho phép các ứng dụng hoạt động nhanh hơn tới 40 lần so với những nền tảng chỉ dùng CPU trong quá trình suy luận. Với mô hình lập trình song song của CUDA, TensorRT cho phép các kỹ sư tối ưu hóa mô hình mạng nơ-ron, hiệu chỉnh để đạt được độ chính xác cao hơn, cũng như dễ dàng triển khai các mô hình của mình trong những trường hợp sử dụng thương mại và nghiên cứu.
Hôm nay, Nvidia đã ra mắt thế hệ thứ 8 của TensorRT với tên gọi TensorRT 8. Phiên bản mới nhất của SDK nổi tiếng này đi kèm với một loạt các bản cập nhật và tính năng cải tiến, hứa hẹn sẽ cho phép các nhà phát triển và doanh nghiệp tối ưu hóa cũng như triển khai hiệu quả các quy trình, sản phẩm học sâu của họ trên web một cách đơn giản hơn.
Trong các quy trình triển khai và sử dụng thương mại, thời gian suy luận đối với các mô hình học sâu đóng vai trò quan trọng. Sự chậm chạp có thể tạo ra hiện tượng tắc nghẽn, đặc biệt là đối với những mô hình biến áp lớn như BERT và GPT-3. Để giảm thiểu những vấn đề như vậy, các nhà phát triển đã sử dụng cách giảm các thông số/kích thước mô hình. Nhưng điều này dẫn đến mất độ chính xác và giảm chất lượng đầu ra trong mô hình thu nhỏ.
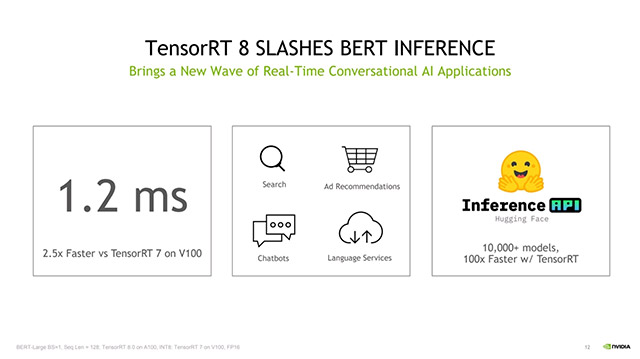
Trong các thử nghiệm nội bộ của Nvidia TensorRT 8, thời gian suy luận đạt được chỉ là 1,2 mili giây trên BERT-Large, một trong những mô hình ngôn ngữ được sử dụng phổ biến nhất hiện nay. So với thế hệ trước của TensorRT, thời gian suy luận 1,2 mili giây của TensorRT 8 nhanh hơn 2,5 lần trên cùng nền tảng GPU V100 của Nvidia.
Thời gian suy luận cực kỳ ấn tượng của TensorRT 8 sẽ tạo điều kiện cho phép các doanh nghiệp triển khai mô hình học sâu của mình với quy mô lớn hơn mà không cần lo lắng quá nhiều về khả năng tính toán và thời gian suy luận, trong khi vẫn đảm bảo chất lượng và độ chính xác.
Khía cạnh chính mang đến tốc độ suy luận nhanh chóng này nằm ở hai tiến bộ quan trọng. Thứ nhất, TensorRT 8 sử dụng một kỹ thuật hiệu suất được gọi là Sparsity để tăng tốc độ suy luận mạng nơ-ron bằng cách linh hoạt giảm các hoạt động tính toán. Sparsity, được hỗ trợ trên kiến trúc Ampere của Nvidia tập trung vào các mục khác 0 trong các lớp ẩn của mạng nơ-ron, về cơ bản hoạt động theo cách lược bỏ các mục không ảnh hưởng đến luồng của tensor qua mạng. Điều này làm giảm số lượng thao tác cần thiết để tính toán câu trả lời trong quy trình chuyển tiếp, cho phép rút ngắn thời gian suy luận trong quá trình triển khai.
Kỹ thuật thứ hai, gọi là Quantization Aware Training (QAT), cho phép nhà phát triển sử dụng các mô hình được đào tạo để chạy suy luận với độ chính xác INT8 mà không làm mất độ chính xác. So với INT32 và INT16, thường được sử dụng để đào tạo và triển khai, INT8 cung cấp các phép tính nhanh hơn bằng cách giảm độ chính xác của các con số, từ đó làm giảm tài nguyên tính toán và lưu trữ trên các lõi tensor.

Sparsity, QAT, và các tính năng tối ưu hóa theo mô hình cụ thể khác được đưa vào TensorRT 8 góp phần mang đến hiệu suất gần gấp đôi so với TensorRT 7. Và trong khi việc sử dụng INT8 để tăng tốc độ suy luận không phải là một khái niệm mới, việc QAT giúp cải thiện độ chính xác của INT8 gấp đôi so với thế hệ trước rõ ràng là một điểm sáng lớn.
Một tin tức thú vị khác dành cho các nhà phát triển là Huggingface, thư viện mã nguồn mở nổi tiếng và phổ biến dành cho các mô hình transformer, sẽ chính thức hỗ trợ TensorRT 8, đạt tốc độ suy luận 1ms vào khoảng cuối năm nay.









 Làng Công nghệ
Làng Công nghệ  Bảo mật mạng
Bảo mật mạng  Chuyện công nghệ
Chuyện công nghệ  Công nghệ mới
Công nghệ mới  Trí tuệ Thiên tài
Trí tuệ Thiên tài 









 AI
AI  Hướng dẫn AI
Hướng dẫn AI  Ứng dụng
Ứng dụng  Hệ thống
Hệ thống  Game - Trò chơi
Game - Trò chơi  iPhone
iPhone  Android
Android  Hàm Excel
Hàm Excel  Download
Download  Khoa học
Khoa học  Cuộc sống
Cuộc sống