 AI
AI  ChatGPT
ChatGPT  Gemini
Gemini  Thư viện Prompt
Thư viện Prompt  Công nghệ
Công nghệ  Học IT
Học IT  Tiện ích
Tiện ích 
Thực tế mà nói thì việc AI có thể tạo ra clip gốc từ một hoặc nhiều đoạn văn bản không phải là một thông tin địa chấn trong thế giới công nghệ. Năm ngoái, các nhà nghiên cứu đã mô tả chi tiết cách thức một hệ thống khai thác mạng thần kinh - các lớp chức năng toán học được mô phỏng theo dạng mạng lưới nơ-ron sinh học (neuron) - để tạo ra những đoạn video dài 32 khung hình và có kích thước 64 × 64 pixel từ nhiều đoạn dữ liệu mô tả mang tính chất gợi hình, ví dụ như “chơi bóng trên bãi cỏ”. Tuy nhiên, theo một bài báo mới được công bố trên Arxiv.org thì các nhà khoa học tại Disney Research và Rutgers đã thành công trong việc đưa ý tưởng này tiến thêm một bước lên tầm cao mới với dạng mô hình AI xuyên suốt từ đầu đến cuối, có thể tạo ra một cốt truyện thô cũng như video mô tả văn bản từ các kịch bản phim. Cụ thể, mô hình chuyển văn bản thành hoạt hình của các nhà khoa học giúp tạo ra hình ảnh động mà không cần dữ liệu chú thích - bước sơ bộ vốn được sử dụng để đưa ra văn bản đầu vào mô tả cho các hoạt động nhất định.

“Tự động tạo hoạt ảnh từ văn bản ngôn ngữ tự nhiên là một công nghệ rất hữu ích, có thể được ứng dụng trong một số lĩnh vực như viết kịch bản phim hay tạo video hướng dẫn. Trong đó, các hệ thống AI này sẽ đặc biệt có giá trị khi được ứng dụng vào việc viết kịch bản bằng cách cho phép lặp lại, tạo mẫu và chứng minh khái niệm một cách nhanh chóng hơn. Trong nghiên cứu này, chúng tôi đã phát triển thành công một hệ thống chuyển văn bản thành hoạt hình có khả năng xử lý ổn thỏa những câu từ phức tạp. Mục đích của hệ thống AI này không phải là để thay thế hoàn toàn cho các nhà văn hay nhà biên kịch, mà là tạo ra một trợ thủ AI có khả năng hỗ trợ hiệu quả và giúp công việc của các nhà biên kịch trở nên thú vị hơn”, nhóm nghiên cứu chia sẻ.
Như các nhà nghiên cứu đã giải thích, việc dịch văn bản thành hoạt hình không phải là một nhiệm vụ đơn giản. Trên thực tế cả câu từ (dữ liệu đầu vào) lẫn hoạt hình (dữ liệu đầu ra) đều không có cấu trúc cố định. Đây cũng là lý do khiến hầu hết các công cụ chuyển văn bản thành video hiện nay không thể xử lý được những mẫu câu phức tạp. Để giải quyết những hạn chế của các hệ thống hiện hành, nhóm nghiên cứu đã tiến hành xây dựng một mạng nơ-ron mô-đun bao gồm một số thành phần như: Mô-đun phân tích cú pháp tập lệnh mới, giúp tự động cách ly văn bản có liên quan khỏi các mô tả cảnh trong kịch bản; một mô-đun xử lý ngôn ngữ tự nhiên giúp đơn giản hóa các mẫu câu phức tạp bằng cách sử dụng một bộ quy tắc ngôn ngữ và trích xuất thông tin từ những câu được đơn giản hóa thành các biểu diễn hành động xác định trước; và một mô-đun tạo hoạt hình có nhiệm vụ chuyển các biểu diễn đã nói trên thành nhiều chuỗi hoạt hình.
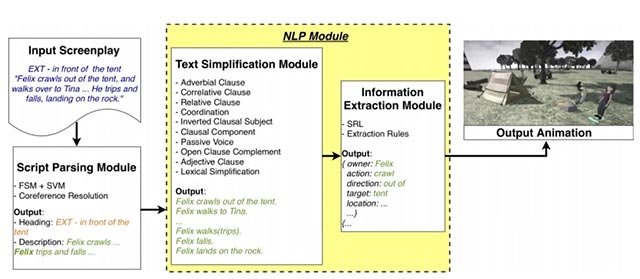
Theo các nhà nghiên cứu cho biết thì cách tiếp cận theo hướng đơn giản hóa này giúp việc trích xuất thông tin tập lệnh chính trở nên dễ dàng hơn rất nhiều, hệ thống của họ sẽ có khả năng xác định tự động khi một đoạn mã đã cho sử dụng cấu trúc cú pháp cụ thể, và sau đó phân tách cũng như lắp ráp nó thành các câu đơn giản hơn, rồi tiếp tục xử lý đệ quy cho đến khi không còn có khả năng đơn giản hóa thêm được nữa. “Bước phối hợp” tiếp theo sẽ được áp dụng cho các câu có cùng quan hệ cú pháp và đồng thời phục vụ cùng một vai trò chức năng. Và cuối cùng, một trình giả lập từ vựng phù hợp với những hành động mô tả trong các câu sẽ được đơn giản hóa với 52 hoạt ảnh khác nhau (có thể mở rộng ra thành 92 hoạt ảnh bằng cách sử dụng từ điển từ đồng nghĩa) trong một thư viện được xác định trước.
Sau đó, một hệ thống có tên là Cardinal sẽ sử dụng những hoạt ảnh này làm dữ liệu đầu vào cho các hành động và tạo ra các previsualization (quá trình chuyển đổi một phân cảnh và kịch bản thành hình ảnh 3D) trong Unreal - một công cụ trò chơi video phổ biến được phát triển bởi Epic Games. Dựa trên thư viện hoạt hình đã xác định trước, các đối tượng và đồng thời cả những mô hình mà nó có thể sử dụng để tạo những ký tự sẽ được tải sẵn, từ đó giúp tạo ra các video hoạt hình 3D mô tả gần đúng với kịch bản được xử lý.
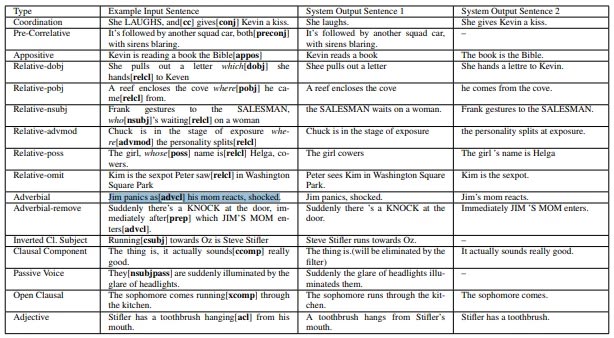
Để đào tạo hệ thống ưu việt này, các nhà nghiên cứu đã phải bắt tay vào biên soạn một kho dữ liệu mô tả cảnh được tạo nên từ 996 kịch bản, vẽ từ hơn 1.000 tập lệnh được lấy từ các nguồn có sẵn miễn phí bao gồm IMSDb, SimplyScripts và ScriptORama5. Tổng cộng, kho dữ liệu này bao gồm 525.708 mô tả có chứa 1.402.864 câu, 920.817 (hơn 40%) trong đó có ít nhất một động từ mô tả hành động.
Trong một thử nghiệm định tính, các nhà khoa học đã giao cho 22 người tham gia đánh giá 20 hình động do hệ thống tạo ra theo thang điểm 5 (ví dụ: Video hiển thị có phải là hoạt ảnh hợp lý với nội dung văn bản không?, hay có bao nhiêu thông tin văn bản được mô tả trong video và có bao nhiêu thông tin trong video đã được nói đến trong văn bản), 68% người tham gia nói rằng hệ thống đã tạo ra hình ảnh động có giá trị hợp lý từ những kịch bản đầu vào - một tỷ lệ không đặc biệt cao nhưng rất đáng khen ngợi.
Điều đó cho thấy rằng đây chưa phải là một hệ thống thực sự hoàn hảo. Trên thực tế, danh sách các hành động và đối tượng của nó không đầy đủ, và đôi khi, quá trình đơn giản hóa từ vựng không thể ánh xạ thành công các động từ phức tạp thành những hoạt hình tương tự, hoặc chỉ có thể tạo ra một vài câu đơn giản cho một động từ có nhiều chủ ngữ trong câu gốc. Tuy nhiên đây vẫn còn là một nghiên cứu non trẻ và những hạn chế như vậy là hoàn toàn có thể thông cảm được. Các nhà nghiên cứu dự định sẽ giải quyết những thiếu sót nêu trên trong tương lai gần.

“Các đánh giá nội bộ và bên ngoài đều cho thấy hiệu suất hợp lý của hệ thống này, và chúng tôi muốn tận dụng thông tin diễn ngôn bằng cách xem xét chuỗi hành động được mô tả trong các đoạn văn bản. Điều này cũng sẽ giúp giải quyết sự mơ hồ trong văn bản liên quan đến hành động. Hơn nữa, hệ thống của chúng tôi hoàn toàn có thể được sử dụng để tạo ra nguồn dữ liệu cần thiết được dùng trong huấn luyện các hệ thống thần kinh từ đầu đến cuối (end-to-end) tương tự”, nhóm nghiên cứu chia sẻ.













 AI
AI  Hướng dẫn AI
Hướng dẫn AI  Ứng dụng
Ứng dụng  Hệ thống
Hệ thống  Game - Trò chơi
Game - Trò chơi  iPhone
iPhone  Android
Android  Hàm Excel
Hàm Excel  Download
Download  Khoa học
Khoa học  Cuộc sống
Cuộc sống  Làng Công nghệ
Làng Công nghệ