 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Việc thiết kế các hệ thống AI có khả năng nhận dạng chính xác đặc điểm của từng địa danh trên thế giới ở cấp độ cá thể (nghĩa là có thể phân biệt được rõ ràng giữa các địa danh trong cùng hạng mục, ví dụ như Thác Niagara với bất kỳ thác nước nào khác) và truy xuất hình ảnh (đối tượng trong hình ảnh với các phiên bản khác của đối tượng đó theo từng danh mục) là một trong những mục tiêu lâu dài được bộ phận nghiên cứu trí tuệ nhân tạo của Google đặc biệt quan tâm. Năm ngoái, công ty đã phát hành Google-Landmarks, một gói dữ liệu liên quan đến các địa danh trên trái đất mà Google tuyên bố là có quy mô lớn nhất thế giới tại thời điểm đó, và đồng thời họ cũng đã tổ chức 2 cuộc thi (Landmark Recognition 2018 và Landmark Retriny 2018), thu hút sự tham gia của hơn 500 nhà nghiên cứu về học máy cũng như trí tuệ nhân tạo hàng đầu thế giới.

Tiếp nối thành công của năm ngoái, hôm qua 5/5, Google đã chính thức phát hành kho dữ liệu đào tạo AI Google-Landmarks-v2 với mã nguồn mở, như một bước tiến quan trọng trong kế hoạch phát triển thành công những mô hình thị giác máy tính có thể nhận biết các địa danh trên thế giới một cách nhanh chóng, chính xác, và tinh vi hơn. Kho dữ liệu Google-Landmarks-v2 lần này có quy mô lớn hơn khá nhiều so với phiên bản trước, sở hữu tới 5 triệu bức ảnh (gấp đôi phiên bản trước) về 200.000 địa danh (gấp 7 lần phiên bản trước) trên toàn thế giới.
Ngoài ra, Google cũng không quên đưa ra 2 “thử thách” mới của năm này là Landmark Recognition 2019 và Landmark Retriny 2019 trên cộng đồng học máy Kaggle, đồng thời phát hành mã nguồn và mô hình cho Detect-to-Retrieve, một framework giúp phục hồi hình ảnh theo khu vực hiệu quả hơn.

“Cả 2 phương pháp nhận dạng và truy xuất hình ảnh nhìn chung sẽ đều yêu cầu bộ dữ liệu đào tạo có quy mô lớn hơn về cả số lượng hình ảnh lẫn sự đa dạng của các địa danh để đào tạo hệ thống tốt hơn cũng như mạnh hơn. Chúng tôi hy vọng rằng bộ dữ liệu này sẽ giúp nâng cao khả năng nhận dạng và truy xuất hình ảnh của các mô hình AI hiện đại một cách triệt để hơn”, 2 kỹ sư phần mềm thuộc đội ngũ Google AI Bingyi Cao và Tobias Weyand chia sẻ.
Ngoài ra, cũng theo 2 chuyên gia này, 5 triệu bức ảnh của hơn 200.000 địa danh lưu trữ trong Google-Landmarks-v2 được thu thập cũng như đóng góp từ các nhiếp ảnh gia trên khắp thế giới. Mỗi bức ảnh sẽ được dán nhãn mô tả cụ thể về địa danh và tác giả, ví dụ như Lâu đài Neuschwanstein (Neuschwanstein Castle), Cầu Cổng Vàng (Golden Gate Bridge), Kiyomizu-dera, Burj Khalifa, Tượng Nhân sư Giza (Great Sphinx of Giza), Machu Picchu và nhiều địa điểm tham quan nổi tiếng khác. Sau đó, các nhà nghiên cứu của Google đã tiến hành bổ sung thêm những bức ảnh mang tính lịch sử, ít được biết đến, thu thập từ Wikimedia Commons, kho lưu trữ trực tuyến Wikimedia Foundation về hình ảnh, âm thanh, và nhiều loại dữ liệu phương tiện khác.
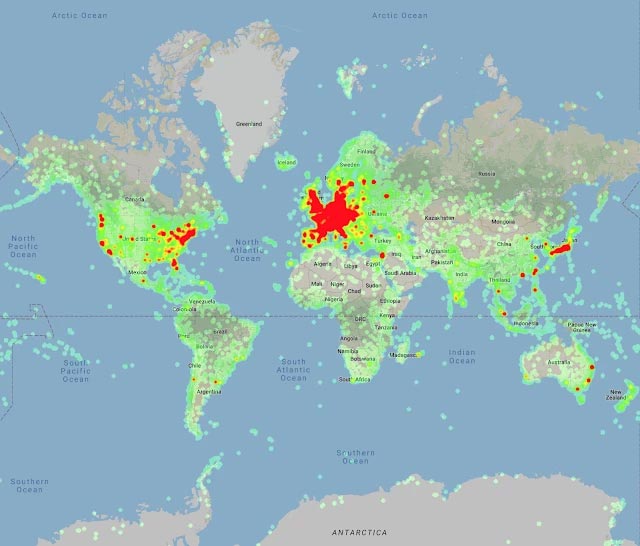
Vậy thì vấn đề chính mà Detect-to-Retrieve framework sẽ giải quyết là gì? Theo giải thích từ Bingyi Cao và Tobias Weyand thì những mô hình đã ra mắt của Google (được đào tạo dựa trên một tập hợp con bao gồm 80.000 bức ảnh lấy từ bộ dữ Google-Landmarks đầu tiên) có thể tận dụng các ô giới hạn (bounding boxes) từ một mô hình phát hiện đối tượng để “tăng thêm trọng lượng” cho các vùng ảnh có chứa những mục đáng lưu tâm, quan đó giúp cải thiện đáng kể độ chính xác.
Bên cạnh đó, Landmark Recognition 2019 (nơi những đội tham gia có nhiệm vụ thiết kế các mô hình AI giúp nhận diện địa danh) và Landmark Retriny 2019 (các đội tham gia sử dụng hệ thống AI để tìm hình ảnh hiển thị chính xác một địa danh theo chỉ định) đều đã bắt đầu nhận đăng ký tham gia ngay từ hôm nay. Cả 2 cuộc thi sẽ bao gồm giải thưởng tiền mặt với tổng trị giá 50.000 đô la và đồng thời các đội chiến thắng sẽ được Google mời tham gia hội nghị về Thị giác máy tính và Nhận dạng mẫu (Conference on Computer Vision and Pattern Recognition) tổ chức ở Long Beach, California vào cuối năm nay, để giới thiệu chi tiết về phương pháp mà họ đã triển khai.









 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học