 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích
Quản trị mạng - SQL Server 2008 được tích hợp nhiều tính năng mới đáng chú ý. Một trong số những tính năng này là những cải tiến trong câu lệnh T-SQL giúp giảm thời gian làm việc với những câu lệnh này.
Trong phần đầu tiên của loạt bài viết này chúng ta sẽ tìm hiểu một số cải tiến của T-SQL.
Cải tiến trong Intellisense (trình cảm ứng thông minh)
Với những cải của Intellisense giờ đây người dùng có thể lưu dữ liệu, tìm những thông tin cần thiết, chèn trực tiếp các thành phần ngôn ngữ T-SQL vào mã và trình cảm ứng thông minh này có thể giúp rút ngắn thời gian nhập lệnh từ bàn phím. Chức năng này có thể rút ngắn thời gian phát triển phần mềm nhờ làm giảm thời gian thao tác với bàn phím đồng thời giảm thiểu những tham chiếu tới những tài liệu ngoài. Những cải tiến của Intellisense bao gồm vùng ngôn ngữ T-SQL được mở rộng và tích hợp một hệ thống mầu sắc.
Tính năng này hoạt động giống như tính năng kiểm tra cú pháp tự động trong Visual Studio. Khi nhập lệnh T-SQL nó sẽ tự động hoàn thiện cú pháp cho lệnh, và cho các đối tượng trong cơ sở dữ liệu, dù các biến đã được khai báo trước đó. Người dùng có thể có thể lựa chọn sử dụng tính năng này hoặc tắt bỏ nó nếu thấy không cần thiết.

Cải tiến trong cú pháp lệnh T-SQL
Trong SQL Server 2008, cú pháp của lệnh T-SQL có ba cải tiến chính sau đây:
1. Khởi tạo biến cùng thời điểm khai báo. Giờ đây người dùng có thể khởi tạo biến ngay khi khai báo thay vì sử dụng hai lệnh riêng biệt là DECLARE và SET như trước đây. Nó có thể làm việc với hầu hết các kiểu dữ liệu bao gồm kiểu dữ liệu SQLCLR, nhưng sẽ không làm việc với kiểu dữ liệu TEXT, NTEXT hay IMAGE.
2. Compound Operators. Compound Operators (toán tử kết hợp) là dạng toán tử giống như trong C++ và C#. Chúng thực thi một số thao tác và cài đặt một giá trị gốc cho kết quả của thao tác. Chúng giúp tránh một số lỗi và cho phép viết tắt khi làm việc với code. Ngoài ra toán tử này có thể sử dụng trong mệnh đề SET của lệnh UPDATE. Dưới đây là danh sách các toán tử được hỗ trợ trong SQL Server 2008:
3. Row Constructor. T-SQL được cải tiến cho phép chèn nhiều giá trị bằng một lệnh INSERT duy nhất. Điều đó có nghĩa là người dùng có thể đưa nhiều thuộc tính hàng vào trong mệnh đề VALUE.
Ví dụ:
Những cải tiến trong thành phần phụ thuộc của đối tượng
Sử dụng bảng gợi ý FORCESEEK
GROUPING SETS
Kết luận
Trong phần đầu tiên của loạt bài viết này chúng ta sẽ tìm hiểu một số cải tiến của T-SQL.
Cải tiến trong Intellisense (trình cảm ứng thông minh)
Với những cải của Intellisense giờ đây người dùng có thể lưu dữ liệu, tìm những thông tin cần thiết, chèn trực tiếp các thành phần ngôn ngữ T-SQL vào mã và trình cảm ứng thông minh này có thể giúp rút ngắn thời gian nhập lệnh từ bàn phím. Chức năng này có thể rút ngắn thời gian phát triển phần mềm nhờ làm giảm thời gian thao tác với bàn phím đồng thời giảm thiểu những tham chiếu tới những tài liệu ngoài. Những cải tiến của Intellisense bao gồm vùng ngôn ngữ T-SQL được mở rộng và tích hợp một hệ thống mầu sắc.
Tính năng này hoạt động giống như tính năng kiểm tra cú pháp tự động trong Visual Studio. Khi nhập lệnh T-SQL nó sẽ tự động hoàn thiện cú pháp cho lệnh, và cho các đối tượng trong cơ sở dữ liệu, dù các biến đã được khai báo trước đó. Người dùng có thể có thể lựa chọn sử dụng tính năng này hoặc tắt bỏ nó nếu thấy không cần thiết.

Cải tiến trong cú pháp lệnh T-SQL
Trong SQL Server 2008, cú pháp của lệnh T-SQL có ba cải tiến chính sau đây:
1. Khởi tạo biến cùng thời điểm khai báo. Giờ đây người dùng có thể khởi tạo biến ngay khi khai báo thay vì sử dụng hai lệnh riêng biệt là DECLARE và SET như trước đây. Nó có thể làm việc với hầu hết các kiểu dữ liệu bao gồm kiểu dữ liệu SQLCLR, nhưng sẽ không làm việc với kiểu dữ liệu TEXT, NTEXT hay IMAGE.
2. Compound Operators. Compound Operators (toán tử kết hợp) là dạng toán tử giống như trong C++ và C#. Chúng thực thi một số thao tác và cài đặt một giá trị gốc cho kết quả của thao tác. Chúng giúp tránh một số lỗi và cho phép viết tắt khi làm việc với code. Ngoài ra toán tử này có thể sử dụng trong mệnh đề SET của lệnh UPDATE. Dưới đây là danh sách các toán tử được hỗ trợ trong SQL Server 2008:
- += Add and assign
- -= Subtract and assign
- *= Multiply and assign
- /= Divide and assign
- %= Modulo and assign
- &= Bitwise AND and assign
- ^= Bitwise XOR and assign
- |= Bitwise OR and assign
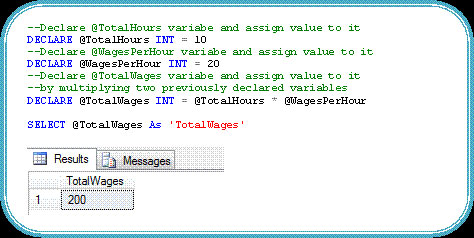
3. Row Constructor. T-SQL được cải tiến cho phép chèn nhiều giá trị bằng một lệnh INSERT duy nhất. Điều đó có nghĩa là người dùng có thể đưa nhiều thuộc tính hàng vào trong mệnh đề VALUE.
Ví dụ:
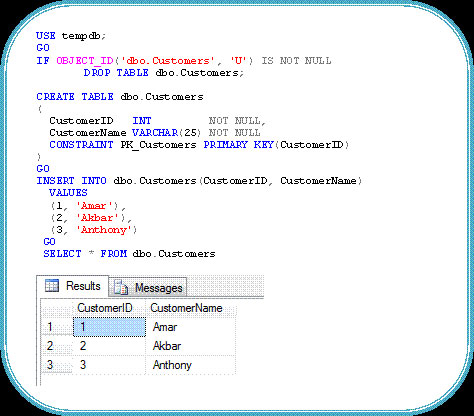
Những cải tiến trong thành phần phụ thuộc của đối tượng
Những cải tiến trong những thành phần phụ thuộc của đối tượng giúp cung cấp những thông tin đáng tin cậy của nhiều thành phần phụ thuộc giữa các đối tượng thông qua view catalog mới được giới thiệu và các chức năng quản lý động. Những thông tin của thành phần phụ thuộc luôn được cập nhật cho phạm vi lược đồ đối tượng(nơi đối tượng A không thể bị xóa do đối tượng B phụ thuộc vào nó) và ngoài lược đồ đối tượng (nơi đối tượng A có thể bị xóa hoặc thậm chí không thể được tạo tuy nhiên đối tượng B vẫn phụ thuộc vào nó). Những thành phần phụ thuộc được kiểm tra cho các thủ tục lưu, bảng biểu, view, chức năng, trigger, kiểu người dùng định nghĩa, tập hợp lược đồ XML, … SQL Server 2008 giới thiệu ba đối tượng mới cung cấp những thông tin thành phần phụ thuộc của đối tượng, bao gồm:
1. sys.sql_expression_dependenciescatalog view: Hiển thị tên các thành phần phụ thuộc của đối tượng. Nó bao gồm một bản ghi cho mỗi thành phần phụ thuộc trên đối tượng do người dùng định nghĩa trong cơ sở dữ liệu hiện thời.
2. sys.dm_sql_referenced_entitiesDMF: Cung cấp nọi thực thể mà thực thể nhập phụ thuộc vào, trả về một hàng cho mỗi đối tượng được người dùng định nghĩa quy chiếu theo tên trong định nghĩa của thực thể tham chiếu được chỉ định.
3. sys.dm_sql_referencing_entitiesDMF: Cung cấp mọi đối tượng phụ thuộc vào thực thể nhập, nó sẽ trả về một bản ghi cho mội đối tượng được người dùng định nghĩa trong cơ sở dữ liệu hiện tại được tham chiếu theo tên của một đối tượng khác được cũng được người dùng định nghĩa.
Có hai phương pháp người dùng có thể sử dụng để xem những đối tượng phụ thuộc đó là sử dụng SSMS (phải chuột lên đối tượng rồi chọn View Dependencies) hay bằng cách viết những truy vấn theo view và DMF vừa kể ra ở trên.
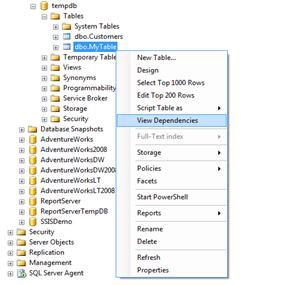
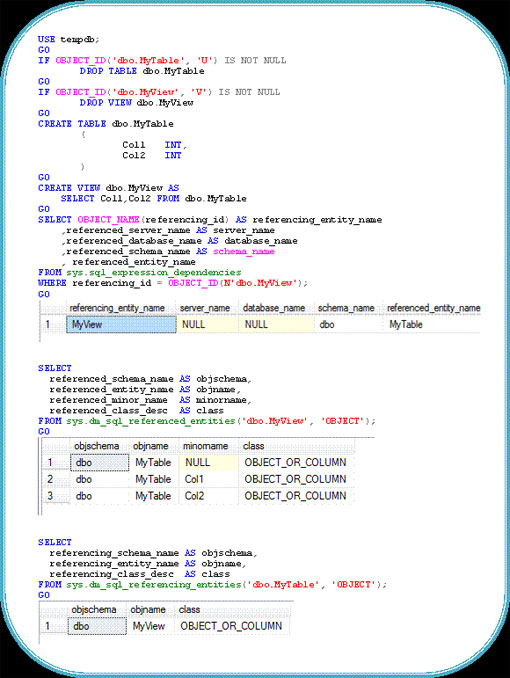
Sử dụng bảng gợi ý FORCESEEK
Bảng gợi ý FORCESEEK khá hữu dụng trong trường hợp Query Plan (các bước được sử dụng để truy cập hay hiệu chỉnh thông tin trong hệ thống quản lý cơ sở dữ liệu liên quan tới SQL) sử dụng một bảng hay toán tử Index Scan (quét chỉ mục) trên một bảng hay view, tuy nhiên toán tử (Index Seek) tìm kiếm chỉ mục có thể hiệu quả hơn (ví dụ như trong trường hợp có quá nhiều sự lựa chọn). Gợi ý bảng FORCESEEK buộc Query Optimizer (trình tối ưu truy vấn) chỉ sử dụng các thao tác Index Seek như đường dẫn truy cập vào dữ liệu trong bảng hay view được tham chiếu trong truy vấn. Chúng ta có thể sử dụng bảng gợi ý này để ghi đè lên Query Plan mặc định được Query Optimizer lựa chọn để tránh các vấn đề thực thi gây ra do Query Plan không hiệu quả. Ví dụ, nếu một Plan chứa bảng hay các toán tử Index Scan, và những bảng tương ứng liên tục được truy cập trong khi thực thi truy vấn thì việc áp dụng một thao tác Index Seek có thể sẽ hiệu quả hơn sử dụng truy vấn. Khả năng này sẽ xảy ra trong trường hợp các thành phần trong tập hợp không chính xác hay tính đến lượng thời gian cần sử dụng để viết một Query Plan mà Query Optimizer sử dụng để thực hiện tìm kiếm.
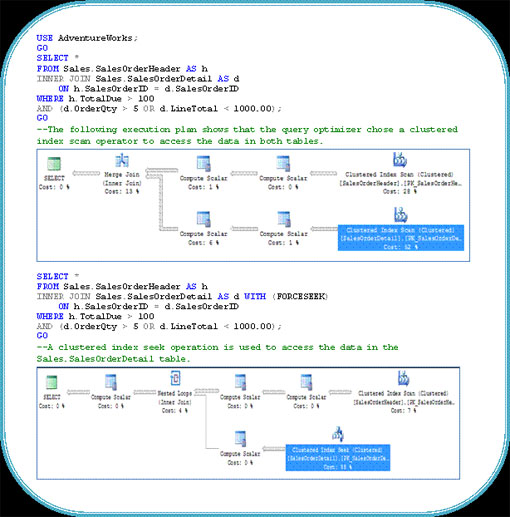
Một trong những tình huống mà bảng gợi ý này trở nên hữu dụng đó là khả năng làm việc với Parameter Sniffing (một công cụ mà trình tối ưu truy vần của SQL Server sử dụng để tìm kiếm giá trị biến từ truy vấn trong khi thực hiện lệnh lần đầu tiên và tạo một Plan thực thi tối ưu dựa trên giá trị đó). Chúng ta hãy kiểm chứng điều này bằng cách chạy những truy vấn dưới đây trong cơ sở dữ liệu AdventureWorks và phân tích những điểm khác biệt.
Trường hợp 1: Truy vấn đầu tiên trả về 450 hàng và có ít khả năng chọn lọc hơn so với truy vấn thứ hai chỉ trả về 16 bản ghi. Do đó cần sử dụng Index Scan cho truy vấn đầu tiên hơn là sử dụng Index Seek và Lookup (tra cứu) của truy vấn thứ hai.
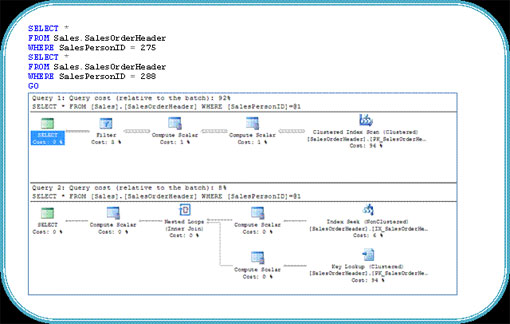
Trường hợp 2: Chúng ta sẽ chạy lại các truy vần ở trên, nhưng trong trường hợp này chúng ta sẽ sử dụng các biến để gán các giá trị cho truy vấn thay vì nhập trực tiếp các giá trị. Nếu kiểm tra các Plan thực thi được tạo chúng ta sẽ thấy cả hai truy vấn đang sử dụng cùng Index Scan mặc dù các giá trị của tham số hoàn toàn khác nhau. Theo trường hợp 1 thì truy vấn thứ hai có khả năng chọn lọc cao hơn và cần sử dụng Index Seek và Lookup. Đó là do trong khi khi truy vấn đầu tiên chạy, trình tối ưu truy vấn SQL không nhận biết được giá trị biến cho đến khi chạy thực. Vì đã sử dụng biến và nhập tùy chọn lọc trên bộ lọc và tạo Plan thực thi trên cơ sở của bộ lọc này và lưu trữ lại, trong khi đó truy vấn thứ hai cũng sẽ sử dụng Plan thực thi tương tự được lưu trữ.
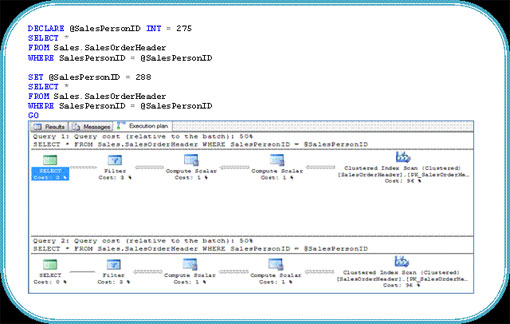
Trường hợp 3: Nếu những truy vấn sử dụng tham số và mọi thời điểm những giá trị biến này trả về với khả năng lọc cao thì chúng ta phải áp dụng phương pháp nào để buộc Query Optimizer thực hiện Index Seek thay vì Index Scan? Chúng tra có hai lựa chọn ở đây, hoặc là sử dụng gợi ý FORCESEEK hay sử dụng tùy chọn RECOMPILE.

FORCESEEK áp dụng cho các thao tác tìm kiểm chỉ mục theo nhóm và không theo nhóm. Nó có thể được chỉ định cho mọi bảng hay view trong mệnh đề FROM của lệnh STATEMENT và trong mệnh đề FROM <table_source> của lệnh UPDATE hay DELETE.
Lưu ý: Do Query Optimizer của SQL Server chỉ lựa chọn Plan thực thi tốt nhất cho một truy vấn nên Microsoft đề xuất rằng các nhà phát triển có kinh nghiệm và các quản trị viên cở sở dữ liệu chỉ sử dụng những gợi ý như một phương pháp cuối cùng vì Optimizer luôn thực hiện tốt tác vụ này.
GROUPING SETS
GROUPING SETS cho phép người dùng viết một truy vấn để tạo nhiều nhóm sau đó chỉ trả về một tập giá trị. Tập giá trị này tương đương với một UNION ALL của những hàng được nhóm khác nhau. Sử dụng GROUPING SETS chúng ta có thể tập trung vào các cấp độ thông tin khác nhau cần sử dụng ngoài việc sử dụng phương pháp kết hợp một số kết quả tru yvaans.
Với khả năng thục thi truy vấn được cải tiến, GROUPING SETS cho phép chúng ta lập báo cáo với nhiều nhóm một cách dễ dàng. VÌ số lượng nhóm luôn có thể tăng lên, nên sự đơn giản và những tiện ích trong khả năng thực thi mà GROUPING SETS mang lại sẽ trở nên hữu dụng hơ nhiều.
Nói cách khác, mệnh đề GROUP BY sử dụng GROUPING SETS có thể kết xuất một nhóm kết quả tương ứng với kết quả được tạo bởi một UNION ALL của nhiều mệnh đề GROUP BY đơn vì mệnh đề GROUP BY chỉ có tác dụng khi kết hợp.
Kết luận
Trong phần đầu này chúng ta đã tìm hiểu một số cải tiến trong câu lệnh T-SQL trong SQL Server 2008 hỗ trợ cho quá trình làm việc của các nhà lập trình. Trong phần tiếp theo của loạt bìa viết này chúng ta sẽ tìm hiểu chi tiết hơn về các kiểu dữ liệu được giới thiệu trong SQL Server 2008.







 Lập trình
Lập trình
 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học