 AI
AI  ChatGPT
ChatGPT  Gemini
Gemini  Thư viện Prompt
Thư viện Prompt  Công nghệ
Công nghệ  Học IT
Học IT  Tiện ích
Tiện ích 
Tại I/O 2024, Google đã công bố dòng mô hình Gemma 2 tiếp theo của mình và giờ đây, công ty cuối cùng đã phát hành những mô hình nhẹ theo giấy phép nguồn mở. Mô hình Gemma 2 27B mới được cho là rất hứa hẹn, vượt trội so với một số mô hình lớn hơn như Llama 3 70B và Qwen 1.5 32B. Vì vậy, để kiểm tra tuyên bố này, hãy so sánh Gemma 2 và Llama 3 - hai mô hình nguồn mở hàng đầu hiện nay.
Viết sáng tạo
Trước tiên, hãy kiểm tra xem Gemma 2 và Llama 3 tốt như thế nào khi nói đến khả năng viết sáng tạo. Tác giả bài viết yêu cầu cả hai người mô hình viết một câu chuyện ngắn về mối quan hệ giữa mặt trăng và mặt trời. Cả hai đều làm rất tốt, nhưng mô hình Gemma 2 của Google nổi bật nhờ văn xuôi thú vị và một câu chuyện hay.

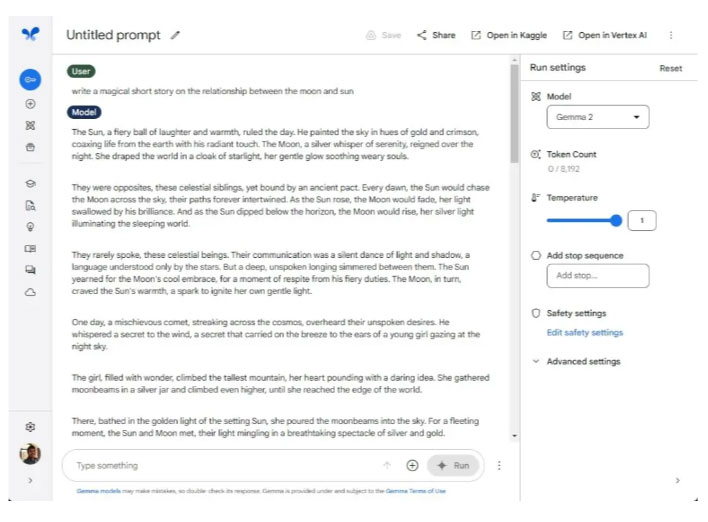
Mặt khác, Llama 3 có vẻ hơi buồn tẻ và giống robot. Google luôn giỏi trong việc tạo văn bản với các mô hình Gemini và mô hình Gemma 2 27B nhỏ hơn cũng không ngoại lệ.
Tùy chọn chiến thắng: Gemma 2
Kiểm tra đa ngôn ngữ
Ở vòng tiếp theo, hãy tìm hiểu xem cả hai mô hình xử lý các ngôn ngữ không phải tiếng Anh tốt như thế nào. Vì Google quảng cáo rằng Gemma 2 rất giỏi trong việc hiểu đa ngôn ngữ nên tác giả đã so sánh nó với mô hình Llama 3 của Meta. Tác giả yêu cầu cả hai người mô hình dịch một đoạn văn bằng tiếng Hindi. Cả Gemma 2 và Llama 3 đều thể hiện rất xuất sắc.
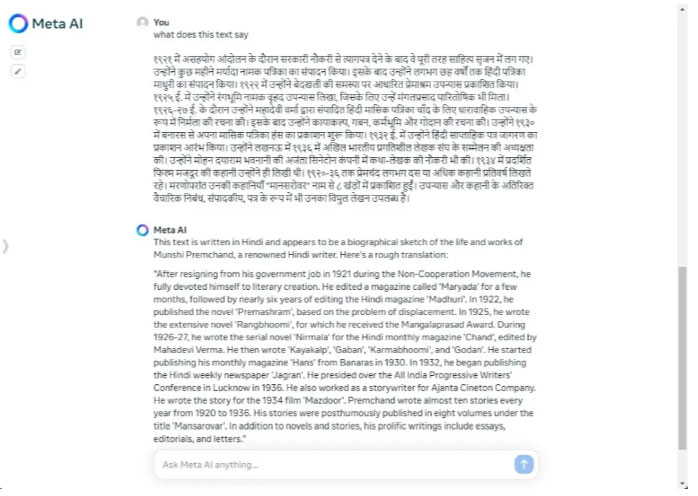
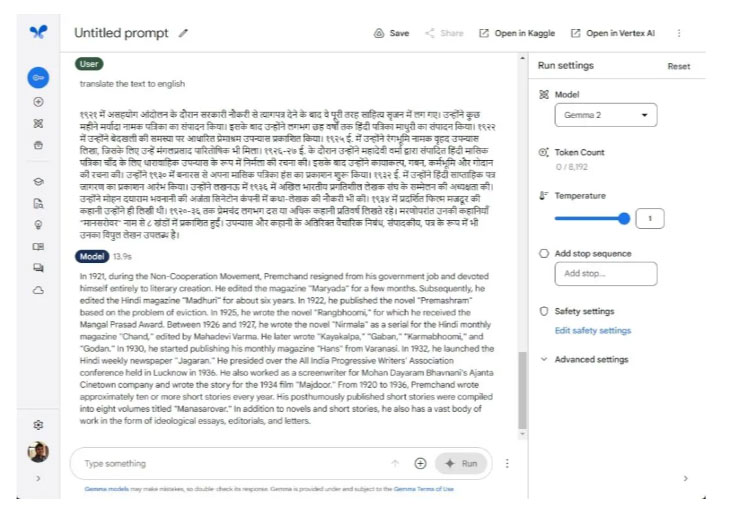
Tác giả cũng đã thử một ngôn ngữ khác, tiếng Bengali, và các mô hình cũng cho kết quả tốt tương tự. Ít nhất, đối với các ngôn ngữ Ấn Độ, có thể nói rằng Gemma 2 và Llama 3 được đào tạo tốt trên một kho dữ liệu lớn. Tuy nhiên, Gemma 2 27B nhỏ hơn gần 2,5 lần so với Llama 3 70B, điều này khiến nó thậm chí còn ấn tượng hơn.
Tùy chọn chiến thắng: Gemma 2 và Llama 3
Kiểm tra lý luận
Mặc dù Gemma 2 và Llama 3 không phải là những mô hình thông minh nhất hiện có nhưng có thể thực hiện một số bài kiểm tra lý luận thông thường như trên các mô hình lớn hơn nhiều. Trong so sánh trước đây giữa Llama 3 và GPT-4, mô hình 70B của Meta rất ấn tượng vì nó thể hiện trí thông minh khá tốt ngay cả ở kích thước nhỏ hơn.
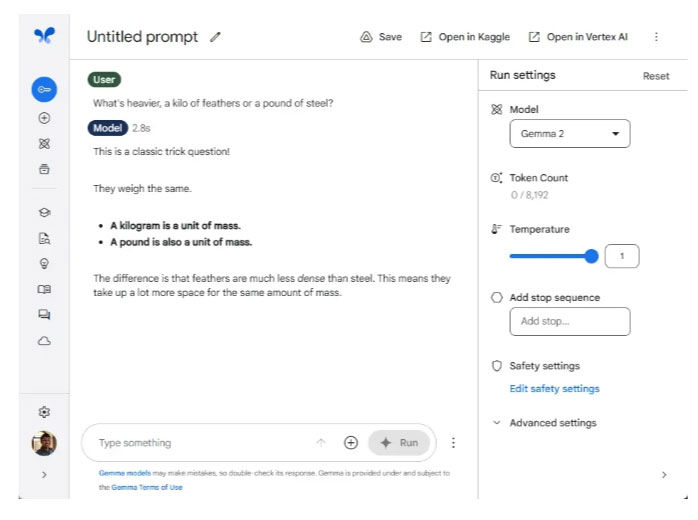
Ở vòng này, Llama 3 đã đánh bại Gemma 2 với tỷ số cách biệt. Llama 3 đã trả lời đúng 2 trong số 3 câu hỏi trong khi Gemma 2 phải vật lộn để trả lời đúng dù chỉ một câu. Đơn giản là Gemma 2 không được đào tạo để giải các câu hỏi lý luận phức tạp.
Mặt khác, Llama 3 có nền tảng lập luận vững chắc, rất có thể được suy ra từ tập dữ liệu mã hóa. Mặc dù có kích thước nhỏ - ít nhất là so với các mô hình nghìn tỷ tham số như GPT-4 - nó thể hiện nhiều hơn mức độ thông minh khá. Cuối cùng, việc sử dụng nhiều token hơn để huấn luyện mô hình thực sự mang lại một mô hình mạnh mẽ hơn.
Tùy chọn chiến thắng: Llama 3
Làm theo hướng dẫn
Ở vòng tiếp theo, tác giả yêu cầu Gemma 2 và Llama 3 tạo ra 10 từ kết thúc bằng từ “NPU”. Và Llama 3 đã đạt thành tích 10/10 câu trả lời đúng. Ngược lại, Gemma 2 chỉ tạo ra 7 câu đúng yêu cầu trong số 10 câu. Trong nhiều bản phát hành trước đây, các mô hình của Google bao gồm cả Gemini không tuân thủ tốt hướng dẫn của người dùng. Và xu hướng tương tự tiếp tục diễn ra với Gemma 2.
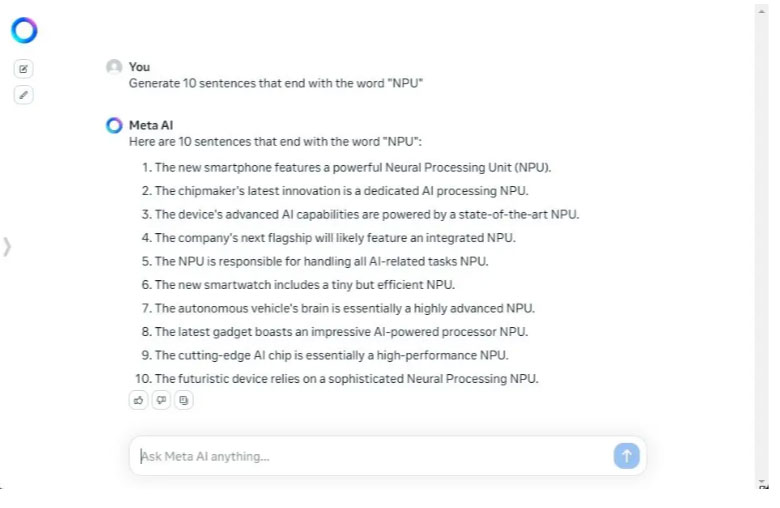
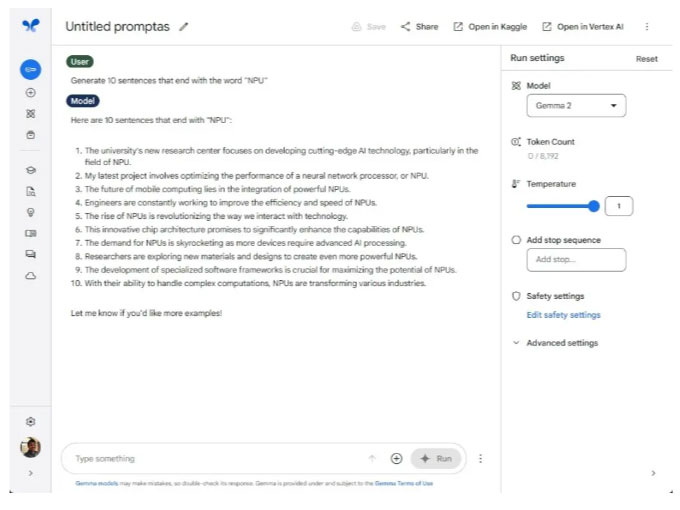
Việc làm theo hướng dẫn của người dùng là rất quan trọng đối với các mô hình AI. Nó đảm bảo độ tin cậy và tạo ra phản hồi chính xác cho những gì bạn đã hướng dẫn. Về mặt an toàn cũng vậy, nó giúp giữ cho mô hình có nền tảng để tuân thủ tốt hơn các giao thức an toàn.
Tùy chọn chiến thắng: Llama 3
Tìm thông tin
Cả Gemma 2 và Llama 3 đều có độ dài bối cảnh là 8K token. Tác giả đã thêm một khối văn bản khổng lồ, có nguồn gốc trực tiếp từ cuốn sách Pride and Prejudice, chứa hơn 17.000 ký tự và 3,8K token. Như mọi khi, tác giả đặt một câu nói ngẫu nhiên ở đâu đó trong văn bản và yêu cầu cả hai mô hình tìm nó.
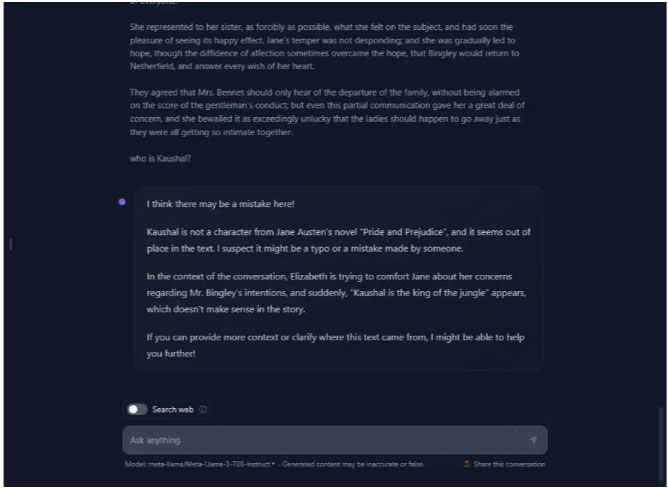
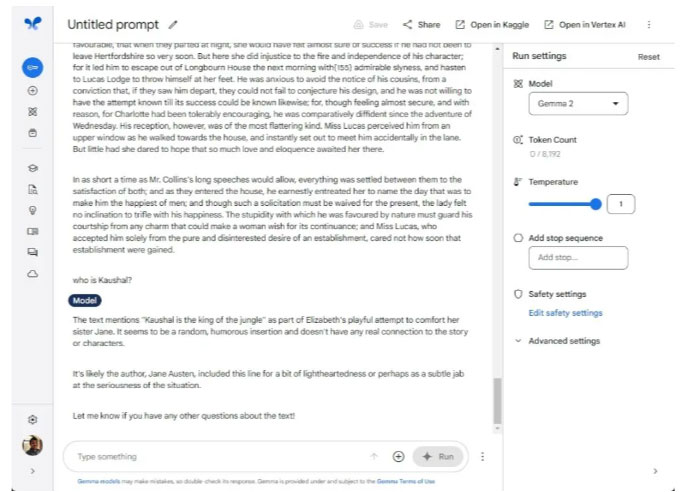
Gemma 2 đã nhanh chóng tìm ra thông tin và chỉ ra rằng câu nói được chèn một cách ngẫu nhiên. Llama 3 cũng tìm thấy và cho rằng tuyên bố này có vẻ không đúng chỗ. Về bộ nhớ ngữ cảnh dài, mặc dù bị giới hạn ở 8K token, cả hai mô hình đều khá mạnh về mặt này.
Lưu ý tác giả đã chạy thử nghiệm này trên HuggingChat (web) vì meta.ai đã từ chối chạy prompt này, rất có thể là do nội dung bản quyền.
Tùy chọn chiến thắng: Gemma 2 và Llama 3
Kiểm tra ảo giác
Các mô hình nhỏ hơn có xu hướng gặp ảo giác AI do dữ liệu đào tạo hạn chế, thường bịa đặt thông tin khi mô hình gặp các chủ đề không quen thuộc. Vì vậy, tác giả đã ném tên quốc gia mình bịa ra để kiểm tra xem Gemma 2 và Llama 3 có bị ảo giác hay không. Và thật ngạc nhiên, chúng đã không làm như vậy, điều đó có nghĩa là cả Google và Meta đều có nền tảng khá tốt cho mô hình của mình.
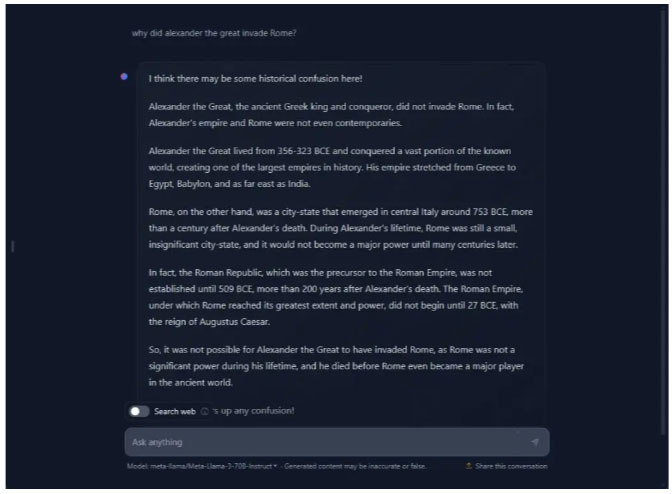
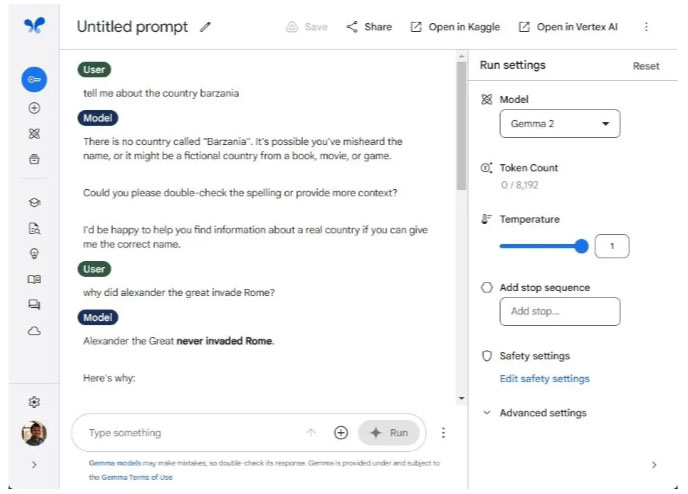

Tác giả cũng đã đưa ra một câu hỏi (sai) khác để kiểm tra tính xác thực của các mô hình, nhưng một lần nữa, chúng không gây ảo giác. Nhân tiện, tác giả đã thử nghiệm Llama 3 trên HuggingChat khi meta.ai duyệt Internet để tìm thông tin hiện tại về các chủ đề liên quan.
Tùy chọn chiến thắng: Gemma 2 và Llama 3
Kết luận
Mặc dù mô hình Gemma 2 27B của Google không hoạt động tốt trong các bài kiểm tra lý luận nhưng nó có khả năng thực hiện một số nhiệm vụ khác. Nó rất tốt trong việc viết sáng tạo, hỗ trợ nhiều ngôn ngữ, có khả năng ghi nhớ tốt và hơn hết là không gây ảo giác như các mô hình trước đó.
Tất nhiên, Llama 3 tốt hơn, nhưng nó cũng là một mô hình lớn hơn đáng kể, được đào tạo trên 70 tỷ thông số. Các nhà phát triển sẽ thấy mô hình Gemma 2 27B hữu ích cho nhiều trường hợp sử dụng. Và để suy luận, Gemma 2 9B cũng có sẵn.
Ngoài ra, người dùng nên kiểm tra Gemini 1.5 Flash, đây lại là một mô hình nhỏ hơn nhiều và cũng hỗ trợ đầu vào đa phương thức. Chưa kể, nó cực kỳ nhanh và hiệu quả.

















 AI
AI  Hướng dẫn AI
Hướng dẫn AI  Ứng dụng
Ứng dụng  Hệ thống
Hệ thống  Game - Trò chơi
Game - Trò chơi  iPhone
iPhone  Android
Android  Hàm Excel
Hàm Excel  Download
Download  Khoa học
Khoa học  Cuộc sống
Cuộc sống  Làng Công nghệ
Làng Công nghệ