 AI
AI  ChatGPT
ChatGPT  Gemini
Gemini  Thư viện Prompt
Thư viện Prompt  Công nghệ
Công nghệ  Học IT
Học IT  Tiện ích
Tiện ích 
AMD vừa chính thức trình làng GPU AI đầu bảng MI300X, được cho là có thể mang lại hiệu suất tốt hơn tới 60% so với nền tảng H100 của NVIDIA, và chủ yếu nhắm mục tiêu đến thị trường data center, phục vụ xử lý HPC và AI. So với phiên bản tiền nhiệm MI300A, Instinct MI300X tập trung vào việc tận dụng dụng toàn bộ tile nhân xử lý GPU kiến trúc CDNA 3, thay vì kết hợp CPU và GPU như trước đây.
Với sự ra mắt của Instinct MI300X, AMD đã lần đầu tiên sử dụng các thông số kỹ thuật chung để so sánh là làm nổi bật hiệu năng của bộ tăng tốc CDNA 3 tiên tiến (so với NVIDIA H100):
- Dung lượng bộ nhớ cao hơn 2,4 lần
- Băng thông bộ nhớ cao hơn 1,6 lần
- 1,3 lần FP8 TFLOPS
- 1,3 lần FP16 TFLOPS
- Nhanh hơn tới 20% so với H100 (Llama 2 70B) khi so sánh 1v1
- Nhanh hơn tới 20% so với H100 (FlashAttention 2) trong so sánh 1v1
- Nhanh hơn tới 40% so với H100 (Llama 2 70B) trong Máy chủ 8v8
- Nhanh hơn tới 60% so với H100 (Bloom 176B) trong máy chủ 8v8
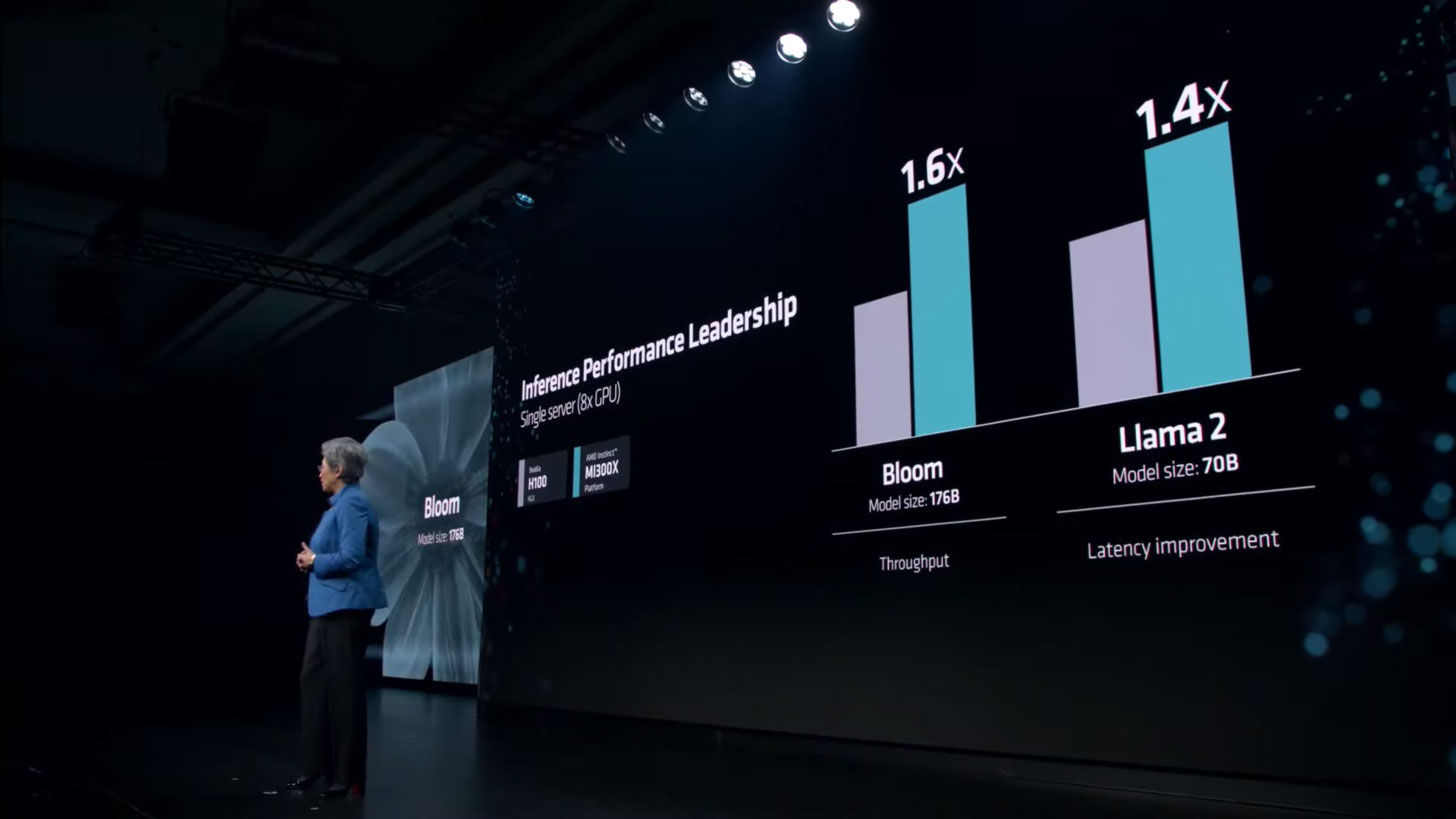
Về mặt kỹ thuật, sự góp mặt của TFLOP hạt nhân LLM giúp MI300X mang lại hiệu suất cao hơn tới 20% trong FlashAttention-2 và Llama 2 70B. Nhìn từ góc độ nền tảng so sánh giải pháp 8x MI300X với giải pháp 8X H100, có thể nhận thấy mức tăng 40% lớn hơn nhiều ở Llama 2 70B và thậm chí lên tới 60% đối với Bloom 176B.

AMD đề cập rằng về hiệu suất đào tạo, MI300X ngang bằng với đối thủ (H100) và cung cấp mức giá/hiệu suất cực kỳ cạnh tranh, đồng thời “tỏa sáng” trong khối lượng công việc liên quan đến tính toán suy luận.
Một trong những yếu tố giúp AMD thực sự tự tin với nền tảng MI300 mới của mình nằm ở ROCm 6.0. Kho phần mềm đã được cập nhật lên phiên bản mới nhất với các tính năng mới mạnh mẽ, bao gồm hỗ trợ cho nhiều khối lượng công việc AI khác nhau như AI sáng tạo và mô hình ngôn ngữ lớn.
Gói phần mềm mới hỗ trợ các định dạng điện toán mới nhất như FP16, Bf16 và FP8 (bao gồm cả Sparsity). Các hoạt động tối ưu hóa kết hợp để mang lại khả năng tăng tốc lên tới 2,6 lần trong vLLM thông qua các thư viện suy luận được tối ưu hóa, tăng tốc 1,4 lần trong Biểu đồ HIP thông qua thời gian chạy được tối ưu hóa, và mức cải thiện 1,3 lần Flash Attention thông qua các Kernel được tối ưu hóa. Sẽ rất thú vị khi so sánh ROCm 6 với phiên bản CUDA mới nhất của NVIDIA, vốn là đối thủ cạnh tranh thực sự của nhau.
AMD Instinct MI300X là con chip sẽ được chú ý nhiều nhất vì nhắm đến các bộ tăng tốc Hopper của NVIDIA và Gaudi của Intel trong phân khúc AI. Con chip này được thiết kế độc quyền trên kiến trúc CDNA 3 với rất nhiều cải tiến đáng chú ý. MI300X sẽ lưu trữ hỗn hợp IP 5nm và 6nm, tất cả kết hợp để cung cấp tới 153 tỷ bóng bán dẫn. Kết hợp với Với bộ nhớ VRAM HBM3 dung lượng lên đến 192GB, MI300X có khả năng vận hành những mô hình machine learning quy mô lớn nhất hiện nay.

Về thiết kế, bộ chuyển tiếp chính được bố trí bằng một khuôn thụ động chứa lớp kết nối dựa trên giải pháp Infinity Fabric thế hệ thứ 4. Interposer bao gồm tổng cộng 28 khuôn trong đó có 8 gói HBM3, 16 khuôn giả giữa các gói HBM và 4 khuôn hoạt động, và mỗi khuôn hoạt động này chứa hai khuôn tính toán.
Mỗi GCD dựa trên kiến trúc GPU CDNA 3 có tổng cộng 40 đơn vị tính toán tương đương với 2560 lõi. Tổng cộng có tám khuôn điện toán (GCD), do đó cung cấpi tổng cộng 320 đơn vị tính toán và 20.480 đơn vị lõi. Để đạt được hiệu suất, AMD sẽ thu nhỏ lại một phần nhỏ trong số các lõi này và chúng ta sẽ thấy tổng cộng 304 đơn vị tính toán (38 CU trên mỗi chiplet GPU), được kích hoạt cho tổng số 19.456 bộ xử lý luồng.
Đi sâu hơn vào bộ nhớ, MI300X có dung lượng HBM3 cao hơn 50% so với phiên bản tiền nhiệm MI250X (128 GB). Để đạt được tổng bộ nhớ 19 GB, AMD trang bị cho MI300X 8 ngăn xếp HBM3 và mỗi ngăn xếp là 12-Hi, đồng thời kết hợp các IC 1Gb mang lại mức dung lượng 2GB cho mỗi IC hoặc 24GB cho mỗi ngăn xếp.
Bộ nhớ sẽ cung cấp băng thông lên tới 5,3TB/s và băng thông Infinity Fabric 896GB/s. Để so sánh,GPU AI H200 sắp ra mắt của NVIDIA cung cấp dung lượng 141GB, trong khi Gaudi 3 của Intel sẽ cung cấp dung lượng 144GB. Đây là yếu tố đóng vai trò rất quan trọng trong khối lượng công việc liên quan đến LLM vốn chủ yếu phụ thuộc vào bộ nhớ, và AMD có thể thể hiện sức mạnh AI vượt trội trên sản phẩm của mình ở khía cạnh này.
- Instinct MI300X - 192 GB HBM3
- Gaudi 3 - 144 GB HBM3
- H200 - 141 GB HBM3e
- MI300A - 128 GB HBM3
- MI250X - 128 GB HBM2e
- H100 - 96 GB HBM3
- Gaudi 2 - 96 GB HBM2e

Về mức tiêu thụ điện năng, AMD Instinct MI300X có TDP 750W, tăng 50% so với mức 500W của Instinct MI250X và nhiều hơn 50W so với NVIDIA H200.
Hiện tại, AMD thừa hiểu rằng các đối thủ cạnh tranh của họ cũng đang hết sức nỗ lực nhằm chiếm lĩnh chỗ đứng vững chắc trong cơn sốt AI. NVIDIA đã đưa ra những con số ấn tượng cho GPU Hopper H200 2024 và Blackwell B100, trong khi Intel cũng đang chuẩn bị ra mắt GPU Guadi 3 và Falcon Shores vào năm 2024. những năm tới cũng vậy. Các công ty như Oracle, Dell, META và OpenAI đã công bố hỗ trợ chip AI Instinct MI300 AI của AMD trong hệ sinh thái của họ.
Với việc ra mặt AMD Instinct MI300X, nhà sản xuất này được kỳ vọng sẽ phá vỡ thế độc quyền của Nvidia trong thị trường chip xử lý nghiên cứu và vận hành AI. Sự ra mắt của MI300 sẽ mở ra cơ hội cho AMD trong thị trường này. MI300X cũng sẽ góp phần quan trọng vào báo cáo tài chính thường niên của AMD trong năm nay.
















 AI
AI  Hướng dẫn AI
Hướng dẫn AI  Ứng dụng
Ứng dụng  Hệ thống
Hệ thống  Game - Trò chơi
Game - Trò chơi  iPhone
iPhone  Android
Android  Hàm Excel
Hàm Excel  Download
Download  Khoa học
Khoa học  Cuộc sống
Cuộc sống  Làng Công nghệ
Làng Công nghệ