 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Nếu sử dụng Linux đủ lâu, bạn sẽ biết về thuật ngữ “inode”. Nó thỉnh thoảng xuất hiện, nhưng không ảnh hưởng đến những gì bạn đang làm. Bài viết sau đây sẽ giải thích inode là gì và làm thế nào nó hoạt động.
Inode là gì?
Trong một thư viện, tất cả các cuốn sách được sắp xếp theo thể loại, tên tác giả hoặc độ tuổi khán giả. Giống như một thư viện, tất cả các file trong hệ thống Linux được tổ chức để truy xuất và sử dụng hiệu quả. Inode là một thực thể hỗ trợ việc sắp xếp các file trong hệ thống Linux.
Siêu dữ liệu file là gì?
Giả sử ta có một file tên là “sample.txt” chứa dữ liệu “hello”.
File này có một số dữ liệu và thông tin liên quan như dung lượng file, quyền, quyền sở hữu nhóm và người dùng, các dấu thời gian (timestamp) tạo/truy cập/sửa đổi, số lượng liên kết, v.v... Tất cả những thông tin này được gọi chung là siêu dữ liệu file.
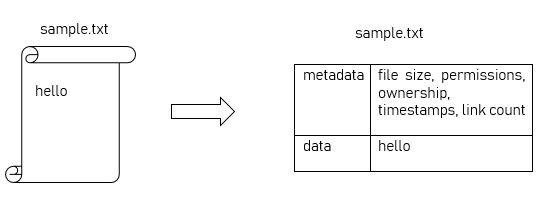
Hệ thống file là gì?
Tham khảo bài viết: Cơ bản về hệ thống File trong Unix/Linux để biết thêm chi tiết.
Kết hợp các khái niệm với nhau
Inode là cấu trúc dữ liệu trên Ext4 chứa tất cả siêu dữ liệu cho một file.
Tất nhiên sẽ có nhiều file trên một hệ thống file. Như bạn có thể đoán, mỗi file sẽ có inode riêng và mỗi inode được đánh số.
Đánh số inode như thế nào?
Số inode trên một hệ thống file bắt đầu từ 1. 10 inode đầu tiên được dành riêng cho việc sử dụng trong hệ thống. Các file người dùng có siêu dữ liệu được lưu trữ từ inode 11. Tất cả các inode được xếp chồng lên nhau gọn gàng trong một bảng inode.
Một mục trong bảng inode sẽ có dung lượng 256 byte. Đối với một file, Linux sắp xếp thông minh tất cả các siêu dữ liệu trong phạm vi 256 byte này! Ngoài ra, mỗi inode cho một file cũng sẽ có thông tin về vị trí của dữ liệu trong hệ thống file. Hãy nhớ rằng, chỉ có siêu dữ liệu của file được lưu trữ trong inode.
Tổng số lượng inode trong một hệ thống file phụ thuộc vào không gian có sẵn và số lượng file có thể được lưu trữ trên phân vùng.
Các inode được phân bổ và giải phóng như thế nào?
Khi người dùng thêm file vào hệ thống file được định dạng mới, các inode bắt đầu từ 11 được phân bổ để giữ siêu dữ liệu file.
Có một cấu trúc dữ liệu khác có tên là Inode Bitmap, dùng để theo dõi trạng thái phân bổ của một inode. Đó là một tập hợp các bit hoạt động như một bản đồ.
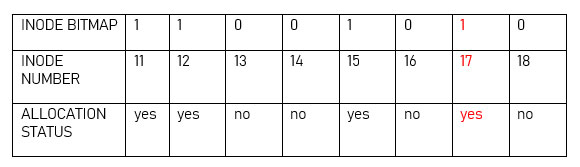
Hãy xem xét 8 bit trong bitmap inode để biểu thị trạng thái phân bổ của các inode 11 đến 18 như trong bảng dưới đây. Giá trị 1 trong bitmap có nghĩa là inode đã được phân bổ để giữ siêu dữ liệu cho một file. Giá trị 0 trong bitmap có nghĩa là inode hiện không được sử dụng. Ở đây, bạn có thể thấy rằng inode 17 đang được sử dụng.
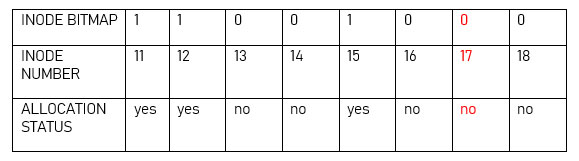
Trong trường hợp file có siêu dữ liệu trong inode 17 bị xóa, thì trạng thái bitmap tương ứng của nó sẽ trở thành 0, cho biết rằng nó có thể được sử dụng tự do bởi một file khác.
Làm cách nào để xem số inode cho một file?
Có hai cách để làm điều này.
Đầu tiên là sử dụng lệnh ls với switch -i, theo sau là tên của file. Trường đầu tiên trong đầu ra là số inode có siêu dữ liệu của sample.txt.
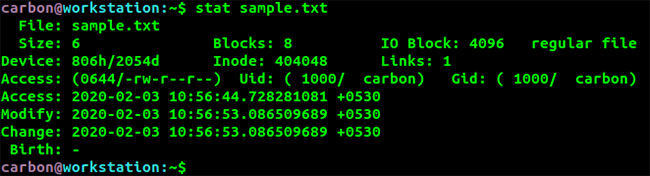
Thông tin tương tự có thể được lấy bằng lệnh stat theo sau là tên file.
Để xem tổng số lượng inode có sẵn cho một phân vùng, lệnh df có thể được sử dụng với switch -i.
Trong phân vùng “/dev/sda4”, 404854480 inode có sẵn để sử dụng, trong đó chỉ có 359044 inode đã được dùng.
Về bản chất, bảng inode sắp xếp siêu dữ liệu của tất cả mọi file một cách tỉ mỉ trong các inode, cùng với thông tin về vị trí của dữ liệu file. Lưu ý tất cả những gì bài viết đã thảo luận về Linux inode mới chỉ là phần nổi của tảng băng chìm mà thôi.









 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học