 AI
AI  ChatGPT
ChatGPT  Gemini
Gemini  Thư viện Prompt
Thư viện Prompt  Công nghệ
Công nghệ  Học IT
Học IT  Tiện ích
Tiện ích Kiến trúc Core của Intel đã xuất hiện vào năm 2006, đây là kiến trúc được sử dụng trên tất cả các CPU mới vào thời điểm này của Intel như Merom, Conroe và Woodcrest. Kiến trúc mới này được xây dựng trên kiến trúc của Pentium M và có thêm một số tính năng mới. Trong hướng dẫn này chúng tôi sẽ giới thiệu cho các bạn về kiến trúc Core này của Intel nhằm trang bị thêm cho các bạn một số kiến thức về phần cứng máy tính.
Thứ đầu tiên mà bạn cần phải lưu ý đó là phần tên, kiến trúc Core không có liên quan gì với các CPU Core Solo và Core Duo của Intel. Core Single là một CPU Pentium M được sản xuất ở công nghệ 65 nm, còn các CPU Core Duo – trước đây được gọi là Yonah – là loại CPU dual-core công nghệ 65 nm dựa trên kiến trúc của Pentium M.
Pentium M được xây dựng trên kiến trúc thế hệ thứ 6 của Intel, kiến trúc này cũng được sử dụng trong các CPU Pentium Pro, Pentium II, Pentium III và các CPU trước đây của Celeron chứ không phải trên Pentium 4 như bạn vẫn nghĩ, ý tưởng ban đầu được nhắm đến các máy tính di động. Nếu bạn có thể nghĩ Pentium M là một Pentium III nâng cao thì cũng có thể nghĩ kiến trúc Core là một Pentium M nâng cao.
Tuy vậy để có thể đọc được hướng dẫn này bạn cần phải đọc hai hướng dẫn khác mà chúng tôi đã giới thiệu cho các bạn đó là Tìm hiểu cách làm việc của CPU và Bên trong kiến trúc Pentium M. Hướng dẫn đầu tiên chúng tôi giới thiệu một cách cơ bản về cách làm việc của CPU còn trên hướng dẫn thứ hai là giới thiệu về cách Pentium M làm việc như thế nào. Trong hướng dẫn này chúng tôi thừa nhận rằng bạn đã có những kiến thức ở trong cả hai hướng dẫn trên. Cũng rất tốt với các bạn đã có kiến thức am hiểu nữa về kiến trúc Pentium 4, vì các bạn có thể so sánh giữa hai kiến trúc với nhau nhằm hiểu sâu hơn về hai kiểu kiến trúc này.
Kiến trúc Core sử dụng cấu trúc 14 tầng. Cấu trúc này là một danh sách tất cả các tầng mà một chỉ lệnh được cho phải trải qua khi thực thi hoàn tất. Intel đã không tiết lộ cấu trúc của Pentium M và chính vì vậy cho tới nay họ vẫn chưa công bố những chỉ dẫn của mỗi tầng trong kiến trúc Core. Do đó chúng tôi cũng không thể cung cấp nhiều thông tin chi tiết hơn. Pentium III đã sử dụng cấu trúc 11 tầng, Pentium 4 ban đầu có 20 tầng và các CPU Pentium 4 mới hơn dựa trên lõi “Prescott” được biết có đến 31 tầng.
Bây giờ chúng ta hãy nói về một số điểm khác trong kiến trúc Core của Pentium M.
Cache nhớ và khối tìm nạp
Hãy nhớ rằng Cache nhớ là bộ nhớ tốc độ cao (SRAM) được nhúng vào bên trong CPU, sử dụng để lưu dữ liệu mà CPU có thể cần đến. Nếu dữ liệu được yêu cầu bởi CPU không có trong Cache nhớ thì nó sẽ phải truy cập vào bộ nhớ RAM chính, điều này sẽ làm giảm tốc độ của CPU vì bộ nhớ RAM được truy vập bằng sử dụng tốc độ clock ngoài của CPU. Ví dụ, trên một CPU 3,2GHz, Cache nhớ được truy cập ở tốc độ 3,2GHz nhưng bộ nhớ RAM chính chỉ được truy cập ở tốc độ clock 800MHz.
Kiến trúc Core được tạo bằng việc có khái niệm multi-core, nghĩa là có nhiều chip trên một đóng gói. Trên Pentium D, phiên bản dual-core của Pentium 4, mỗi core đều có Cache nhớ L2 của riêng nó. Vấn đề với hai Cache riêng ở đây là tại một thời điểm nào đó khi một lõi này sử dụng hết Cache nhớ trong khi lõi kia lại không sử dụng hết hiệu suất trên Cache nhớ L2 của riêng nó. Khi xảy ra điều này thì lõi đầu tiên phải truy cập và lấy dữ liệu từ bộ nhớ RAM chính, thậm chí Cache nhớ L2 của lõi thứ hai là hoàn toàn trống rỗng mà lẽ ra có thể được sử dụng để lưu dữ liệu, tránh tình trạng lõi phải truy cập trực tiếp vào bộ nhớ RAM chính.
Đối với kiến trúc Core, vấn đề này đã được giải quyết. Cache nhớ L2 được chia sẻ, có nghĩa là cả hai lõi đều có thể sử dụng Cache nhớ L2 một cách chung nhau, cấu hình động sẽ được thực hiện cho mỗi Cache. Ví dụ với một CPU có 2 MB L2 cache, một lõi có thể đang sử dụng 1,5MB còn lõi kia sử dụng 512 KB (0.5 MB), ngược lại với tỷ lệ chia cố định 50-50 như đã được sử dụng trước đây trong các CPU dual-core.
Khối tiền tìm nạp được chia sẻ giữa các lõi, nghĩa là nếu hệ thống Cache nhớ đã nạp một khối dữ liệu để được sử dụng bởi lõi đầu tiên thì lõi thứ hai cũng có thể sử dụng dữ liệu đã được nạp trên Cache này rồi. Trong các kiến trúc trước, nếu lõi thứ hai cần dữ liệu giống như dữ liệu đã được nạp vào Cache của lõi đầu tiên thì nó vẫn phải truy cập thông qua bus ngoài (điều đó khiến CPU làm việc ở tốc độ clock ngoài, có tốc độ clock thấp hơn tốc độ clock trong) hoặc thậm chí lấy dữ liệu cần thiết trực tiếp từ bộ nhớ RAM của hệ thống.
Intel cũng đã cải thiện khối tiền tìm nạp của CPU, đưa ra các mẫu theo cách mà CPU hiện đang lấy dữ liệu từ bộ nhớ để đoán thử dữ liệu mà CPU sẽ tìm nạp tiếp theo là gì và nạp nó vào Cache nhớ trước khi CPU yêu cầu. Ví dụ, nếu CPU đã nạp dữ liệu từ địa chỉ 1, sau đó yêu cầu dữ liệu trên địa chỉ 3 và sau đó yêu cầu tiếp dữ liệu trên địa chỉ 5 thì khối tiền tìm nạp sẽ đoán rằng chương trình sẽ nạp dữ liệu từ địa chỉ 7 và nó sẽ nạp từ địa chỉ này ra Cache nhớ trước khi CPU yêu cầu đến nó. Quả thực ý tưởng này không có gì mới mẻ và tất cả các CPU từ Pentium Pro sẽ dụng một số kiểu dự đoán để cung cấp Cache nhớ L2. Trên kiến trúc Core, Intel đã có một chút nâng cao về tính năng này bằng cách tạo ra một khối tiền tìm nạp tìm kiếm các mẫu trong dữ liệu tìm nạp thay vì các bộ chỉ thị tĩnh của dữ liệu mà CPU sẽ yêu cầu tiếp theo.
Bộ giải mã chỉ lệnh: Macro-Fusion
Một khái niệm mới được giới thiệu trong kiến trúc Core đó là macro-fusion. Macro-fusion là khả năng gắn (joining) hai chỉ lệnh x86 vào thành một chỉ lệnh micro-op. Cách làm này có thể cải thiện được hiệu suất của CPU và tiêu tốn ít năng lượng của CPU hơn vì nó sẽ chỉ thực thi một chỉ lệnh micro-op thay vì hai.
Mặc dù vậy cơ chế này lại bị hạn chế đối với các chỉ lệnh so sánh và các chỉ lệnh rẽ nhánh có điều kiện (có nghĩa là các chỉ lệnh CMP và TEST và Jcc). Ví dụ, chúng ta hãy xem đoạn chương trình dưới đây:
…
load eax, [mem1]
cmp eax, [mem2]
jne target
…
Đoạn chương trình này sẽ thực hiện nạp thanh ghi 32 bit EAX bằng dữ liệu được chứa trong vị trí nhớ 1, so sách giá trị của nó với dữ liệu có trong vị trí nhớ 2 và nếu chúng khác nhau thì (jne = jump if not equal), thì chương trình sẽ truy cập vào địa chỉ “target”, còn nếu bằng nhau thì chương trình sẽ tiếp tục trên vị trí hiện hành.
Với macro-fusion, các chỉ lệnh so sánh (cmp) và rẽ nhánh (jne) sẽ được hợp nhất vào một chỉ lệnh micro-op. Chính vì vậy sau khi chuyển qua bộ giải mã chỉ lệnh, phần chương trình này sẽ giống như dưới đây:
…
load eax, [mem1]
cmp eax, [mem2] + jne target
…
Như những gì thấy ở trên, chúng ta đã lưu một chỉ lệnh. Càng ít chỉ lệnh được thực thi thì máy tính của bạn sẽ thực hiện việc thực thi nhiệm vụ nhanh hơn và tốn ít công suất tiêu thụ hơn.
Bộ giải mã chỉ lệnh có trên kiến trúc Core có thể giải mã 4 chỉ lệnh trên một chu kỳ clock, trong khi đó ở các CPU trước như Pentium M và Pentium 4 thì chỉ có thể giải mã được đến 3.
Ở đây bộ giải mã chỉ lệnh của kiến trúc Core kéo đến 5 chỉ lệnh mỗi lần vào hàng đợi chỉ lệnh, thậm chí nó còn có thể giải mã đến 4 chỉ lệnh trên một chu kỳ clock. Chính vì vậy nếu hai trong số 5 chỉ lệnh được nối thành một thì bộ giải mã vẫn có thể giải mã bốn chỉ lệnh trên một chu kỳ clock. Và nó sẽ ở chế độ nhàn rỗi cục bộ bất cứ khi nào macro-fusion xảy ra, nghĩa là bộ giải mã sẽ chỉ cung cấp ba chỉ lệnh nối micro-op ở đầu ra của nó trong khi có khả năng cung cấp đến bốn.
Trong hình 1 bên dưới bạn có thể thấy những thông tin tóm tắt mà chúng tôi đã giải thích ở trên.
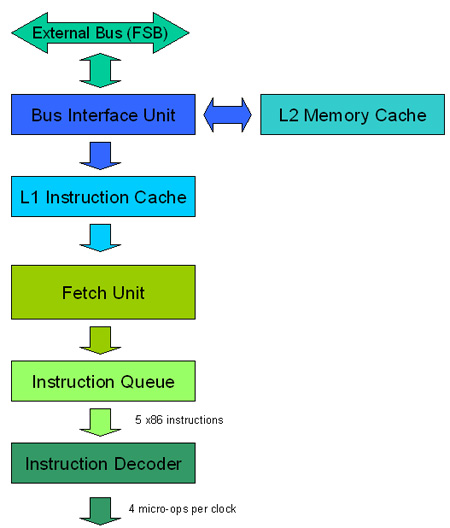
Hình 1: Khối tìm nạp và bộ giải mã chỉ lệnh trong kiến trúc Core














 AI
AI  Hướng dẫn AI
Hướng dẫn AI  Ứng dụng
Ứng dụng  Hệ thống
Hệ thống  Game - Trò chơi
Game - Trò chơi  iPhone
iPhone  Android
Android  Hàm Excel
Hàm Excel  Download
Download  Khoa học
Khoa học  Cuộc sống
Cuộc sống  Làng Công nghệ
Làng Công nghệ