 AI
AI  ChatGPT
ChatGPT  Gemini
Gemini  Thư viện Prompt
Thư viện Prompt  Công nghệ
Công nghệ  Học IT
Học IT  Tiện ích
Tiện ích 
Một trong những thách thức lớn nhất của deep learning là hiểu vì sao mô hình lại đưa ra quyết định như vậy. Dù là những lần xAI phải “chỉnh đốn” quan điểm chính trị của Grok, ChatGPT gặp vấn đề về xu hướng chiều lòng người dùng (sycophancy), hay các hiện tượng “ảo giác” thường thấy, việc truy ngược hành vi của một mạng nơ-ron với hàng tỷ tham số chưa bao giờ đơn giản.
Guide Labs, startup có trụ sở tại San Francisco do CEO Julius Adebayo và Giám đốc khoa học Aya Abdelsalam Ismail sáng lập, cho rằng họ đã tìm ra lời giải. Công ty vừa công bố mã nguồn mở một mô hình LLM 8 tỷ tham số mang tên Steerling-8B, được huấn luyện bằng kiến trúc mới giúp hành vi của mô hình có thể được diễn giải rõ ràng. Theo đó, mỗi token mà mô hình tạo ra đều có thể truy vết ngược lại nguồn gốc trong dữ liệu huấn luyện.
Việc truy vết này có thể đơn giản như xác định tài liệu tham khảo cho một thông tin mà mô hình trích dẫn, nhưng cũng có thể phức tạp hơn, chẳng hạn như phân tích cách mô hình hiểu về khái niệm giới tính hay sự hài hước.
Adebayo chia sẻ rằng nếu một khái niệm như “giới tính” được mã hóa theo hàng tỷ cách khác nhau trong mô hình, thì việc tìm ra và kiểm soát tất cả các biểu diễn đó là cực kỳ khó khăn. Với các mô hình hiện tại, điều này vẫn có thể thực hiện, nhưng rất mong manh và thiếu ổn định. Theo ông, đây là một trong những “chén thánh” của lĩnh vực AI.
Từ nghiên cứu tại MIT đến kiến trúc LLM mới
Adebayo bắt đầu theo đuổi hướng đi này khi làm nghiên cứu sinh tiến sĩ tại MIT. Ông là đồng tác giả của một bài báo năm 2018, trong đó chỉ ra rằng các phương pháp giải thích mô hình deep learning hiện có không đáng tin cậy.
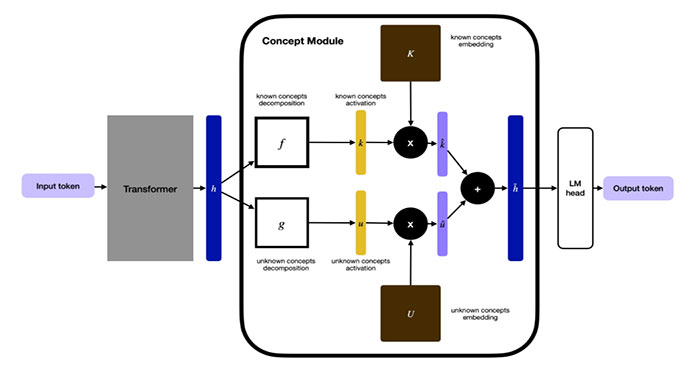
Từ nền tảng đó, đội ngũ Guide Labs phát triển một cách xây dựng LLM hoàn toàn mới. Thay vì cố gắng “giải phẫu” mô hình sau khi đã huấn luyện xong, họ chèn vào một “lớp khái niệm” (concept layer) ngay trong quá trình thiết kế. Lớp này giúp gom nhóm dữ liệu thành các danh mục có thể truy vết được.
Cách tiếp cận như vậy đòi hỏi giai đoạn gán nhãn dữ liệu nhiều hơn ban đầu, nhưng nhóm nghiên cứu đã tận dụng chính các mô hình AI khác để hỗ trợ quá trình đó. Steerling-8B hiện là mô hình lớn nhất mà họ xây dựng để chứng minh tính khả thi của phương pháp.
Theo Adebayo, phần lớn nỗ lực giải thích mô hình hiện nay giống như làm “khoa học thần kinh” trên một bộ não đã hình thành sẵn. Trong khi đó, Guide Labs chọn cách thiết kế mô hình từ đầu sao cho không cần phải “mổ xẻ” phức tạp sau này.
Liệu khả năng giải thích có làm mất đi tính “emergent”?
Một lo ngại là việc ràng buộc mô hình theo cấu trúc có thể làm giảm các hành vi “emergent” – tức khả năng khái quát hóa và suy luận vượt ngoài dữ liệu huấn luyện, vốn là điều khiến LLM trở nên đặc biệt.
Tuy nhiên, Adebayo khẳng định Steerling-8B vẫn thể hiện các “khái niệm được khám phá” (discovered concepts) do chính mô hình tự hình thành, ví dụ như các chủ đề liên quan đến điện toán lượng tử.
Ông cho rằng kiến trúc có khả năng giải thích được sẽ trở thành yêu cầu bắt buộc trong tương lai. Với các LLM hướng đến người tiêu dùng, nó cho phép nhà phát triển kiểm soát tốt hơn việc sử dụng tài liệu có bản quyền, hay điều chỉnh đầu ra liên quan đến các chủ đề nhạy cảm như bạo lực hoặc chất kích thích.
Trong các ngành bị quản lý chặt chẽ như tài chính, yêu cầu này càng rõ ràng hơn. Ví dụ, một mô hình đánh giá hồ sơ vay vốn cần xem xét dữ liệu tài chính, nhưng không được phép chịu ảnh hưởng bởi yếu tố chủng tộc. Tương tự, trong nghiên cứu khoa học – chẳng hạn lĩnh vực gấp cuộn protein – các nhà khoa học cần hiểu rõ vì sao mô hình đề xuất một tổ hợp nhất định, thay vì chỉ nhận kết quả “hộp đen”.
Từ “bài toán khoa học” thành “bài toán kỹ thuật”
Theo Guide Labs, Steerling-8B đạt khoảng 90% năng lực so với các mô hình hiện có, nhưng sử dụng ít dữ liệu huấn luyện hơn nhờ kiến trúc mới. Adebayo cho rằng việc huấn luyện mô hình có khả năng giải thích giờ đây không còn là vấn đề nghiên cứu thuần túy, mà đã trở thành bài toán kỹ thuật có thể mở rộng quy mô.
Ông tin rằng không có lý do gì khiến loại mô hình này không thể đạt hiệu suất tương đương các mô hình tiên phong với số lượng tham số lớn hơn nhiều.
Guide Labs, xuất thân từ Y Combinator và huy động được 9 triệu USD vòng seed từ Initialized Capital vào tháng 11/2024, đang lên kế hoạch xây dựng một mô hình lớn hơn, đồng thời cung cấp API và khả năng truy cập theo hướng agentic cho người dùng.
Adebayo nhận định rằng cách chúng ta đang huấn luyện mô hình hiện nay vẫn còn rất “nguyên thủy”. Việc phổ cập khả năng giải thích nội tại sẽ mang lại lợi ích lâu dài cho xã hội, đặc biệt khi các mô hình ngày càng tiến gần tới mức siêu thông minh. Theo ông, không ai muốn một hệ thống đưa ra quyết định thay mình mà bản thân lại không hiểu rõ cách nó hoạt động.
















 AI
AI  Hướng dẫn AI
Hướng dẫn AI  Ứng dụng
Ứng dụng  Hệ thống
Hệ thống  Game - Trò chơi
Game - Trò chơi  iPhone
iPhone  Android
Android  Hàm Excel
Hàm Excel  Download
Download  Khoa học
Khoa học  Cuộc sống
Cuộc sống  Làng Công nghệ
Làng Công nghệ