 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Qwen 3.5 là dòng mô hình Qwen mới nhất của Alibaba, được xây dựng dựa trên hiệu năng mạnh mẽ của các mô hình Qwen trước đó trong các tác vụ suy luận, lập trình và đa phương thức.
Các đánh giá chuẩn độc lập cho thấy mô hình Qwen 3.5-397B-A17B đạt điểm cao trong những bài kiểm tra được sử dụng rộng rãi như LiveCodeBench và AIME26, thường vượt trội hơn các mô hình hàng đầu như GPT-5.2 và Claude Opus 4.5 trong phần lớn những hạng mục được đánh giá, và mang lại thông lượng cao hơn đáng kể so với các thế hệ Qwen trước đó.
Yêu cầu phần cứng và phần mềm cho Qwen 3.5
Trước khi chạy Qwen 3.5 cục bộ, bạn cần đảm bảo thiết lập của mình đáp ứng cả yêu cầu phần cứng và phần mềm để suy luận mượt mà. Hướng dẫn này sẽ sử dụng GPU NVIDIA H200 với 141GB VRAM, kết hợp với 240GB RAM hệ thống, cung cấp đủ bộ nhớ để chạy phiên bản MXFP4_MOE của Qwen 3.5 một cách hiệu quả với tính năng giảm tải MoE.
Để dễ hình dung, thuật toán lượng tử động 4-bit Unsloth UD-Q4_K_XL sử dụng khoảng 214GB dung lượng ổ cứng. Nó có thể cài đặt trực tiếp trên ổ SSD M3 Ultra 256GB, và cũng hoạt động tốt trên một GPU 24GB với 256GB RAM, đạt tốc độ xử lý hơn 25 token mỗi giây với tính năng giảm tải MoE. Các thuật toán lượng tử 3-bit nhỏ hơn có thể cài đặt trong 192GB RAM, trong khi các phiên bản 8-bit có độ chính xác cao hơn có thể yêu cầu tới 512GB RAM và VRAM kết hợp.
Nhìn chung, để đạt hiệu suất tốt nhất, tổng dung lượng VRAM + RAM của bạn nên xấp xỉ bằng kích thước của mô hình lượng tử hóa mà bạn tải xuống. Nếu không, llama.cpp có thể chuyển tải sang ổ SSD, nhưng quá trình suy luận sẽ chậm hơn.
Về phần mềm, bạn cần cài đặt driver GPU NVIDIA mới nhất, cùng với CUDA Toolkit phiên bản gần đây, để đảm bảo khả năng tương thích hoàn toàn với llama.cpp và quá trình suy luận tăng tốc bằng CUDA.
Cách chạy Qwen 3.5 cục bộ
Bây giờ, bạn đã đáp ứng đủ các điều kiện tiên quyết, hãy cùng xem hướng dẫn từng bước về cách sử dụng Qwen 3.5 cục bộ:
1. Thiết lập môi trường cục bộ
Để chạy Qwen 3.5 cục bộ, bạn cần có quyền truy cập vào một máy tính có GPU mạnh. Vì hầu hết các máy tính xách tay và máy tính để bàn không có đủ VRAM hoặc bộ nhớ để xử lý những mô hình có kích thước này, chúng ta sẽ sử dụng máy ảo GPU trên đám mây.
Hướng dẫn này đang sử dụng Hyperbolic để chạy mô hình một cách riêng tư. Bạn cũng có thể sử dụng các nhà cung cấp khác như RunPod, Vast.ai, hoặc bất kỳ nền tảng máy ảo GPU nào bạn thích. Bài viết chọn Hyperbolic vì hiện tại nó cung cấp một số phiên bản GPU tiết kiệm chi phí nhất hiện có.
Bắt đầu bằng cách khởi chạy một phiên bản mới với một GPU H200 duy nhất.
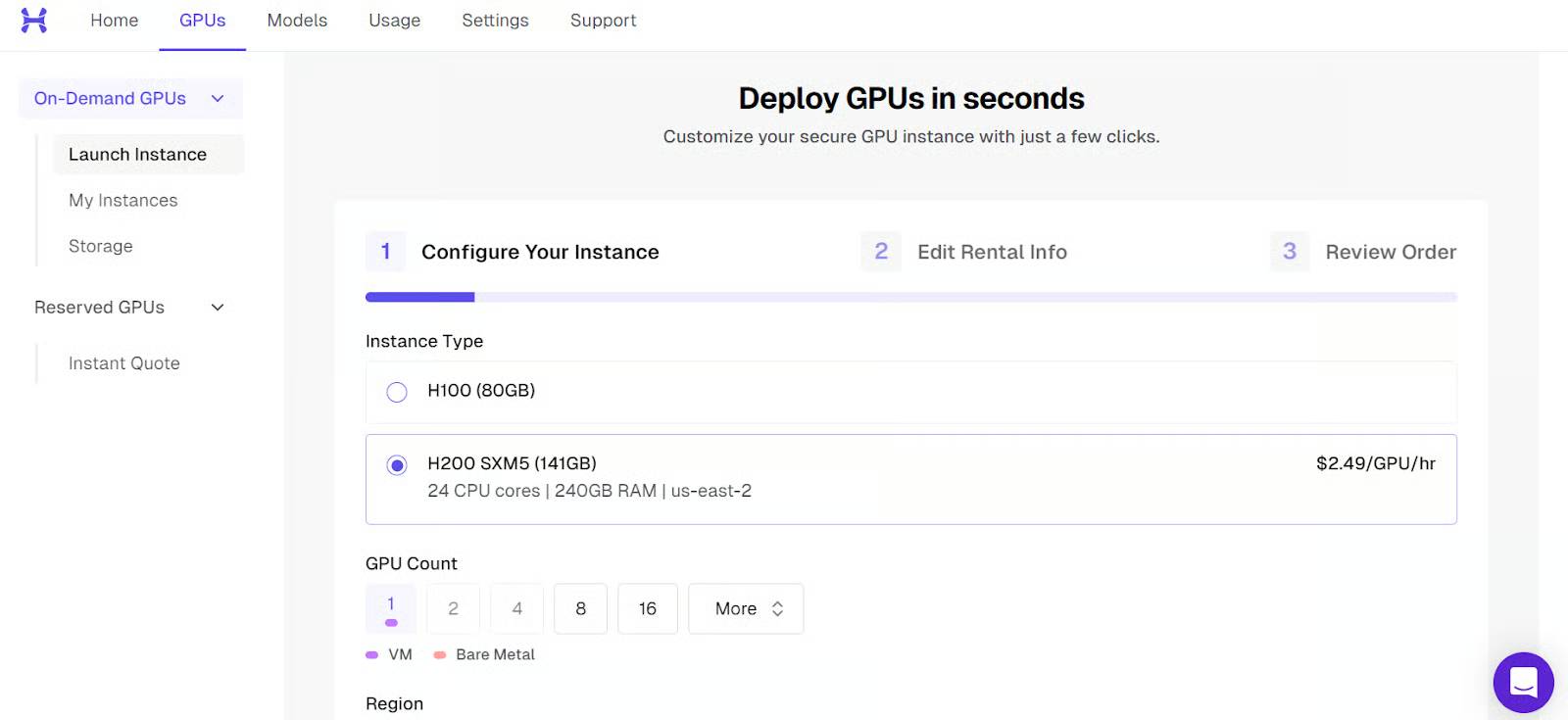
Sau khi máy khởi động, bạn sẽ thấy địa chỉ IP public và lệnh SSH cần thiết để kết nối từ terminal cục bộ của bạn.
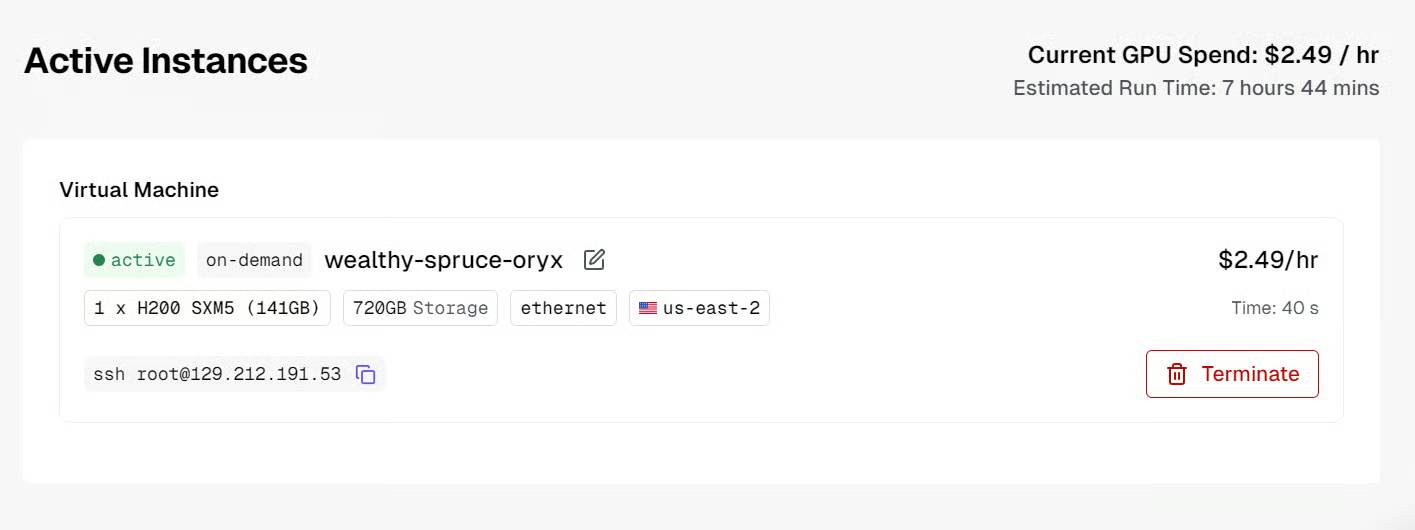
Trước khi kết nối, hãy đảm bảo bạn đã thiết lập SSH cục bộ và đã thêm SSH key public của mình khi tạo máy ảo.
Sau khi phiên bản sẵn sàng, hãy kết nối với nó bằng SSH với chuyển tiếp cổng. Điều này rất quan trọng vì chúng ta muốn truy cập máy chủ suy luận llama.cpp cục bộ thông qua cổng 8080:
ssh -L 8080:localhost:8080 root@129.212.191.53Lần đầu tiên kết nối, hãy nhập yes để xác nhận, sau đó xác thực bằng SSH key của bạn.
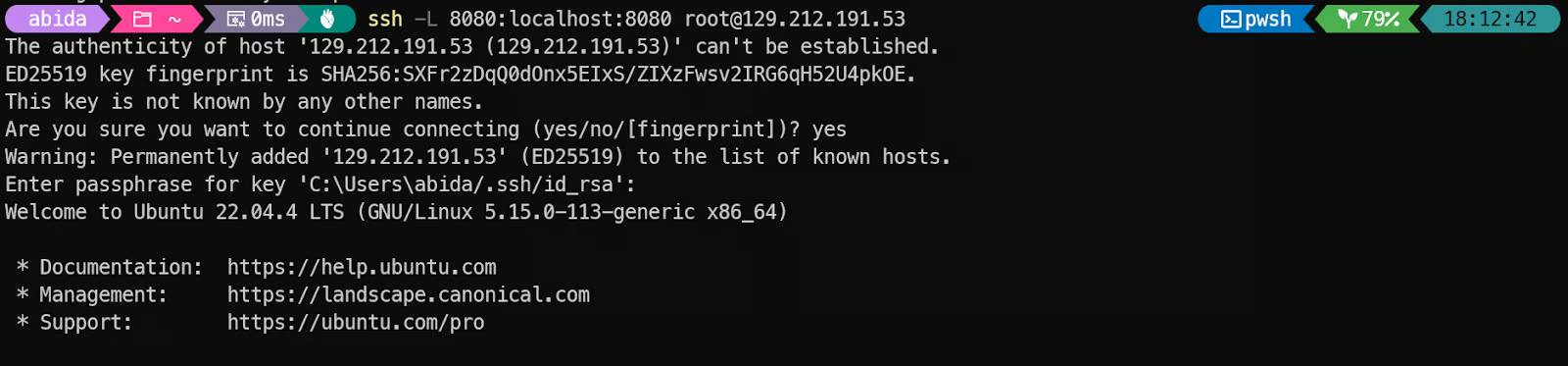
Sau khi đăng nhập, hãy xác minh rằng GPU được nhận diện chính xác:
nvidia-smi Bạn sẽ thấy NVIDIA H200 được liệt kê trong kết quả.
Cuối cùng, hãy cài đặt các gói Linux cần thiết để tải xuống, biên dịch và chạy llama.cpp:
sudo apt update
sudo apt install pciutils build-essential cmake curl libcurl4-openssl-dev -ySau khi hoàn tất, môi trường của bạn đã sẵn sàng để cài đặt llama.cpp và chạy Qwen 3.5 cục bộ.
2. Cài đặt llama.cpp với hỗ trợ CUDA
llama.cpp là một công cụ suy luận C và C++ mã nguồn mở cho phép bạn chạy các mô hình ngôn ngữ lớn cục bộ với thiết lập tối thiểu, hỗ trợ cả tăng tốc CPU và GPU.
Đầu tiên, sao chép kho lưu trữ llama.cpp:
git clone https://github.com/ggml-org/llama.cppTiếp theo, cấu hình bản build hỗ trợ CUDA với CMake. Chúng ta bật CUDA bằng -DGGML_CUDA=ON và đặt kiến trúc CUDA thành 90a vì đang sử dụng NVIDIA H200 (lớp Hopper). Điều này giúp bản build tạo ra code GPU được tối ưu hóa cho các tính năng của Hopper.
cmake llama.cpp -B llama.cpp/build \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES="90a"
Bây giờ biên dịch file nhị phân máy chủ. llama-server là máy chủ REST tích hợp cho phép bạn hiển thị llama.cpp như một API endpoint:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Cuối cùng, sao chép các file nhị phân đã biên dịch vào thư mục chính để dễ dàng chạy:
cp llama.cpp/build/bin/llama-* llama.cpp3. Tải xuống mô hình Qwen 3.5
Giờ đây, sau khi đã cài đặt llama.cpp, bước tiếp theo là tải xuống các trọng số mô hình Qwen 3.5 thực tế ở định dạng GGUF. Các file này có dung lượng lớn, vì vậy sử dụng Hugging Face CLI là cách đáng tin cậy nhất để tải chúng trực tiếp vào máy GPU của bạn.
Cần cài đặt Python trước vì những công cụ tải xuống và tiện ích xác thực của Hugging Face được phân phối dưới dạng các gói Python. Mặc dù bản thân llama.cpp được viết bằng C++, nhưng Python giúp việc quản lý tải xuống và truyền tải mô hình dễ dàng hơn nhiều.
Bắt đầu bằng cách cài đặt pip:
sudo apt install python3-pipTiếp theo, cài đặt Hugging Face Hub client cùng với các công cụ hỗ trợ hiệu suất. hf_transfer và hf-xet giúp tăng tốc độ tải xuống đáng kể, điều này rất quan trọng khi tải xuống hàng trăm gigabyte file mô hình:
pip -q install -U huggingface_hub hf-xet
pip -q install -U hf_transferBây giờ, hãy tải xuống mô hình Qwen 3.5 từ Hugging Face. Trong hướng dẫn này, chúng ta chỉ tải xuống biến thể MXFP4_MOE, được tối ưu hóa cho suy luận MoE hiệu quả:
hf download unsloth/Qwen3.5-397B-A17B-GGUF \
--local-dir models/Qwen3.5 \
--include "*MXFP4_MOE*"
Sau khi quá trình tải xuống hoàn tất, các file mô hình sẽ được lưu trữ trong models/Qwen 3.5, sẵn sàng để được load vào llama.cpp để suy luận cục bộ.
4. Khởi chạy mô hình Qwen 3.5 trên GPU đơn
Bây giờ, chúng ta có thể khởi chạy Qwen 3.5 bằng llama-server. Điều này cung cấp cho chúng ta một API endpoint tương thích với OpenAI có thể gọi từ các công cụ và ứng dụng cục bộ.
Tối ưu hóa máy chủ cho thiết lập GPU đơn bằng cách thực hiện 3 việc chính. Đầu tiên, bật tùy chọn --fit để llama.cpp tự động cân bằng mô hình giữa VRAM của GPU và RAM hệ thống, thay vì báo lỗi khi mô hình không vừa hết trong VRAM.
Thứ hai, chúng ta sử dụng cửa sổ ngữ cảnh lớn hơn với --ctx-size 16384 để máy chủ có thể xử lý các prompt dài hơn. Thứ ba, chúng ta bật tùy chọn --jinja và truyền --chat-template-kwargs để kiểm soát định dạng trò chuyện và tắt chế độ suy nghĩ để nhận phản hồi nhanh và trực tiếp hơn.
Chạy máy chủ với lệnh:
./llama.cpp/llama-server \
--model models/Qwen3.5/MXFP4_MOE/Qwen3.5-397B-A17B-MXFP4_MOE-00001-of-00006.gguf \
--alias "Qwen3.5" \
--host 0.0.0.0 \
--port 8080 \
--fit on \
--jinja \
--ctx-size 16384 \
--temp 0.7 \
--top-p 0.8 \
--top-k 20 \
--min-p 0.00 \
--chat-template-kwargs "{\"enable_thinking\": false}"Trong khi mô hình đang load, bạn sẽ thấy nó sử dụng cả VRAM GPU và bộ nhớ hệ thống, điều này là bình thường đối với một mô hình MoE lớn.

Sau khi quá trình load hoàn tất, máy chủ sẽ có thể truy cập được tại:
- 0.0.0.0:8080 trên máy ảo
- http://127.0.0.1:8080 trên máy cục bộ của bạn sau khi chuyển tiếp cổng SSH
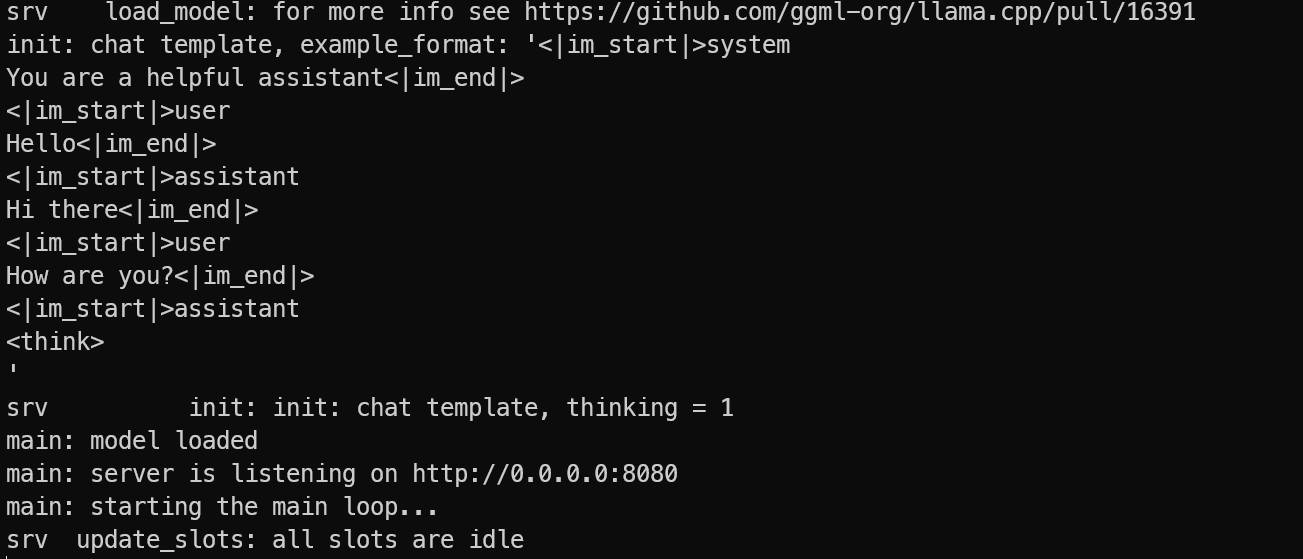
Hãy để máy chủ tiếp tục chạy. Trên máy tính cục bộ của bạn, mở một cửa sổ terminal mới và kết nối lại bằng cách chuyển tiếp cổng SSH:
ssh -L 8080:localhost:8080 root@129.212.191.53Sau đó, kiểm tra máy chủ bằng cách liệt kê các mô hình có sẵn:
curl -s http://127.0.0.1:8080/v1/modelsNếu bạn thấy Qwen 3.5 trong phản hồi, máy chủ của bạn đang chạy chính xác và bạn đã sẵn sàng gọi nó từ OpenAI SDK và các ứng dụng cục bộ của mình.

5. Kiểm tra mô hình Qwen 3.5 bằng cách sử dụng OpenAI SDK
Bây giờ, máy chủ suy luận Qwen 3.5 đang chạy, bước tiếp theo là xác minh rằng nó hoạt động chính xác với các ứng dụng client thực tế. Một trong những lợi thế lớn nhất của llama.cpp là llama-server cung cấp API tương thích với OpenAI, có nghĩa là bạn có thể sử dụng OpenAI SDK chính thức mà không cần thay đổi cấu trúc code của mình.
Đầu tiên, hãy cài đặt gói Python OpenAI trên máy tính cục bộ của bạn (hoặc bên trong máy ảo nếu bạn muốn):
pip install openai Bây giờ, hãy chạy một script kiểm thử đơn giản. Script này kết nối với điểm cuối được chuyển tiếp cục bộ của bạn tại http://127.0.0.1:8080/v1 thay vì máy chủ đám mây của OpenAI.
python3 - <<'PY'
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required"
)
response = client.chat.completions.create(
model="Qwen3.5",
messages=[
{"role": "user", "content": "Write one sentence about AI agents."}
]
)
print(response.choices[0].message.content)
PYMột vài chi tiết quan trọng cần hiểu ở đây:
- base_url trỏ đến máy chủ Qwen 3.5 cục bộ của bạn, không phải API của OpenAI.
- api_key vẫn được yêu cầu bởi SDK, nhưng llama.cpp không bắt buộc xác thực, vì vậy bất kỳ giá trị giữ chỗ nào cũng hoạt động.
- Tên model="Qwen 3.5" khớp với alias được đặt khi khởi động máy chủ.
Nếu mọi thứ được cấu hình chính xác, bạn sẽ nhận được phản hồi nhanh chóng và rõ ràng từ mô hình.
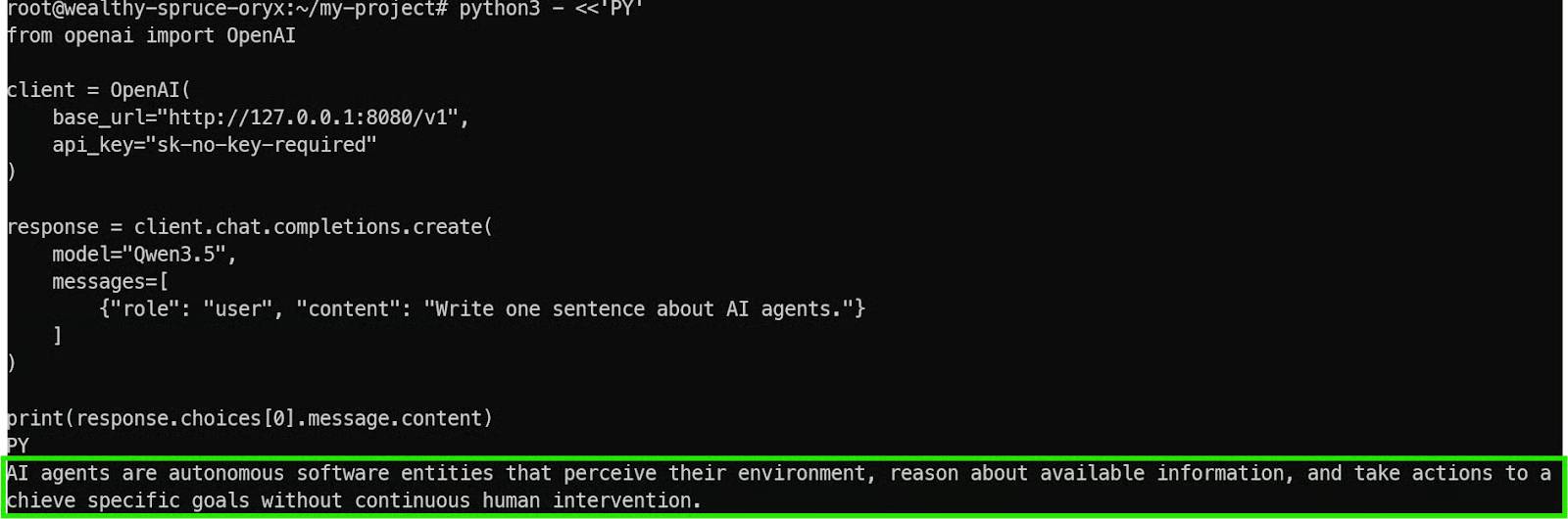
Điều này xác nhận rằng:
- Mô hình Qwen 3.5 đã được load thành công
- Máy chủ llama.cpp đang chạy đúng cách
- Chuyển tiếp cổng SSH của bạn đang hoạt động
- Điểm cuối hoàn toàn tương thích với các ứng dụng kiểu OpenAI
Tại thời điểm này, bạn có thể tích hợp Qwen 3.5 vào bất kỳ công cụ cục bộ, quy trình làm việc của agent hoặc ứng dụng nào đã hỗ trợ định dạng API của OpenAI.
6. Xây dựng giao diện người dùng dựa trên văn bản (TUI) cho giao dịch chứng khoán bằng WebUI của Llama.cpp
Llama.cpp bao gồm một WebUI tích hợp sẵn, theo kiểu ChatGPT, mà bạn có thể sử dụng để trò chuyện trực tiếp với mô hình trong trình duyệt của mình. Điều này hữu ích cho việc kiểm thử nhanh, lặp lại thao tác và tạo code mà không cần phải viết bất kỳ script client nào trước.
Vì đã thiết lập chuyển tiếp cổng SSH, bạn có thể mở WebUI trên máy tính cục bộ của mình và nó sẽ hoạt động như thể máy chủ đang chạy trên laptop.
Theo mặc định, WebUI có sẵn tại:
http://127.0.0.1:8080Nếu trang này load được, nó xác nhận hai điều. SSH tunnel của bạn đang hoạt động chính xác và máy chủ Qwen 3.5 có thể truy cập được cục bộ trong khi vẫn đang chạy riêng tư trên máy ảo GPU.
Sau khi bạn vào WebUI, hãy dán prompt này. Mục tiêu là để mô hình tạo ra cả code Python và hướng dẫn sử dụng ngắn gọn.
Xây dựng một ứng dụng giao diện người dùng văn bản (TUI) đơn giản bằng Python "Stock Screener Trainer" chạy bằng `python app.py` sử dụng thư viện rich (không phải giao diện web). Ứng dụng này cho phép tôi nhập danh sách mã cổ phiếu, chọn chế độ (tăng trưởng/giá trị/cổ tức) và mức độ rủi ro (thấp/trung bình/cao), lấy các chỉ số cơ bản công khai cho mỗi mã cổ phiếu từ một nguồn miễn phí, hiển thị trạng thái load trực tiếp, sau đó tạo một bảng đẹp và phần "Top 5 theo quy tắc chấm điểm của tôi" với lời cảnh báo rõ ràng "chỉ mang tính chất giáo dục, không phải lời khuyên tài chính", và lưu toàn bộ kết quả vào file `results.csv`.Trong vòng vài giây, Qwen 3.5 sẽ tạo ra một file `app.py` và thường là một lời giải thích ngắn gọn về cách chạy nó.
Bây giờ hãy chuyển sang terminal cục bộ của bạn (laptop). Cài đặt các thư viện cần thiết cho ứng dụng được tạo ra:
pip install rich yfinanceThao tác này cài đặt:
- rich cho bố cục giao diện người dùng dựa trên văn bản (TUI), bảng, prompt và chỉ báo tiến độ
- yfinance để lấy các chỉ số chứng khoán công khai, miễn phí
Tạo một file có tên app.py, dán code do mô hình tạo ra và chạy:
python3 app.pySau khi chạy script, bạn sẽ thấy giao diện người dùng dựa trên văn bản (TUI) khởi chạy chính xác trong terminal của mình. Ứng dụng sẽ nhắc bạn nhập mã chứng khoán muốn phân tích, cùng với chế độ sàng lọc và mức độ rủi ro ưa thích của bạn.
Ví dụ, tác giả bài viết đã thử nghiệm với ba cổ phiếu phổ biến.
Sau một giai đoạn load ngắn, công cụ sẽ trả về một bảng đầy đủ các chỉ số chứng khoán, làm nổi bật kết quả dựa trên những quy tắc chấm điểm và lưu mọi thứ vào file results.csv.
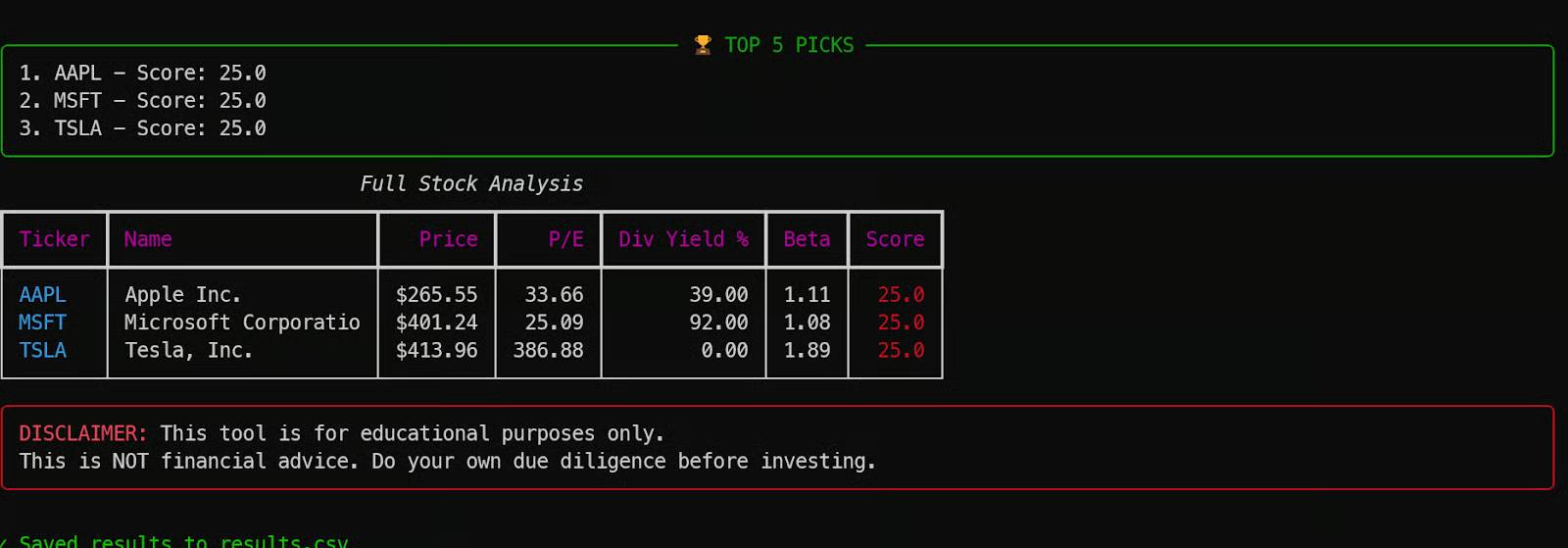
Đây là một ví dụ tuyệt vời về cách Qwen 3.5 có thể tạo ra một ứng dụng hoạt động hoàn chỉnh chỉ trong một lần, chỉ sử dụng một endpoint mô hình lượng tử hóa 4 bit và một prompt đơn giản.
Kết luận
Chạy Qwen3.5 cục bộ là một cách mạnh mẽ để truy cập vào một mô hình quy mô lớn trong khi vẫn giữ mọi thứ riêng tư và hoàn toàn nằm trong tầm kiểm soát của bạn. Trong hướng dẫn này, mô hình được host trên một máy ảo GPU H200 duy nhất, được truy cập an toàn từ máy cục bộ bằng cách sử dụng chuyển tiếp cổng SSH và được phục vụ thông qua một endpoint tương thích với OpenAI được tối ưu hóa (llama.cpp).
Tuy nhiên, có một vài hạn chế thực tế cần lưu ý. Vì mọi thứ phụ thuộc vào một SSH tunnel đang hoạt động, nên kết nối cần phải ổn định. Nếu Internet của bạn bị gián đoạn hoặc phiên bị ngắt kết nối, bạn sẽ mất quyền truy cập vào cổng cục bộ và thường cần phải kết nối lại và khởi động lại một số phần của quy trình làm việc.
Một vấn đề phổ biến khác là xây dựng llama.cpp một cách chính xác. Nếu bạn không chỉ định flag kiến trúc CUDA phù hợp cho GPU của mình, quá trình biên dịch có thể mất nhiều thời gian hơn và có thể không được tối ưu hóa hoàn toàn cho phần cứng. Việc thiết lập kiến trúc chính xác ngay từ đầu sẽ tạo ra sự khác biệt đáng kể về thời gian xây dựng và hiệu suất.
Cuối cùng, mặc dù bộ lượng tử MXFP4_MOE 4-bit rất tuyệt vời để chạy các mô hình lớn một cách hiệu quả, nhưng nó không phải lúc nào cũng lý tưởng cho những quy trình lập trình agentic. Trong quá trình thử nghiệm với các công cụ như Qwen Code CLI, Kilo Code CLI và OpenCode, mô hình gặp khó khăn với những suy luận sâu hơn và thường xuyên thất bại trong các vòng lặp tạo code dài, đôi khi thậm chí còn gây ra sự bất ổn định của GPU.
Các mô hình định lượng có độ chính xác cao hơn hoặc những mô hình nhỏ hơn tập trung vào suy luận có thể hoạt động tốt hơn để lập trình dựa trên agent một cách đáng tin cậy.







 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học