 AI
AI
 ChatGPT
ChatGPT
 Gemini
Gemini
 Thư viện Prompt
Thư viện Prompt
 Công nghệ
Công nghệ
 Học IT
Học IT
 Tiện ích
Tiện ích

Ai cũng có ý kiến riêng về chatbot AI tốt nhất. Thật không may, hầu hết các ý kiến đều dựa trên cảm nhận, những tiêu chuẩn do công ty đặt ra, hoặc bất kỳ mô hình nào gây ấn tượng với ai đó vào ngày hôm đó. Mọi người muốn tìm một cách tốt hơn để kiểm tra các chatbot hàng đầu trong công việc thực tế của mình, không bị ảnh hưởng bởi những giả định cá nhân.
Hóa ra công cụ đó đã tồn tại, hoàn toàn miễn phí, và nó sẽ thay đổi chatbot AI mà bạn thực sự sử dụng mỗi ngày.
Tại sao hầu hết các danh sách "chatbot AI tốt nhất" thực sự không giúp ích gì cho bạn?
Nhiệm vụ của bạn khác với các tiêu chuẩn của chúng
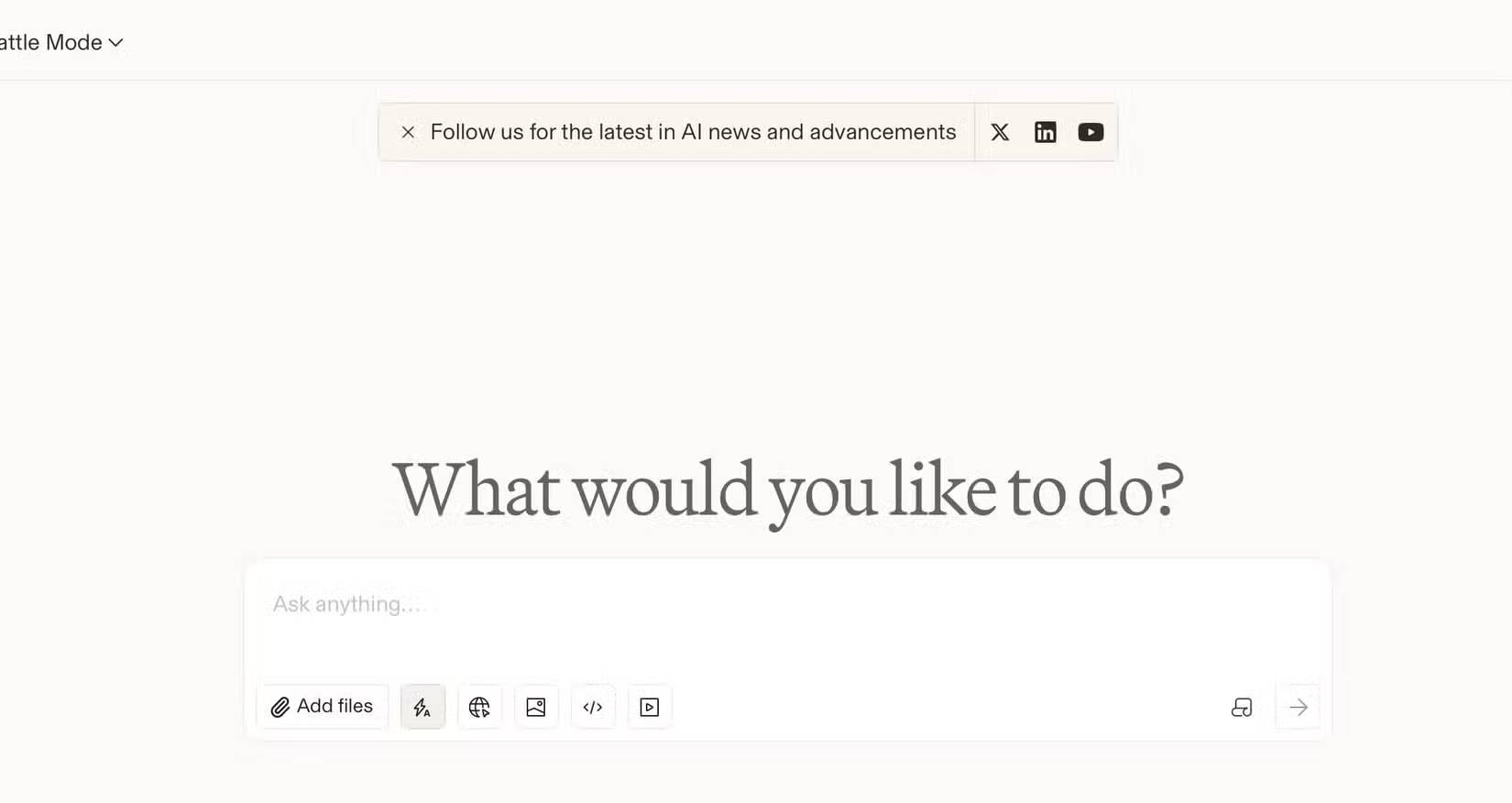
Hầu hết các so sánh chatbot AI đều kiểm tra những điều tương tự: Viết một bài thơ, giải thích vật lý lượng tử hoặc giải một bài toán. Những loại câu hỏi này cho thấy khả năng chung nhưng lại không cho bạn biết nhiều về việc liệu một mô hình có phù hợp với nhu cầu của mình hay không.
Với một người viết về công nghệ, công việc thực sự sẽ là soạn thảo các phần bài viết, tóm tắt nghiên cứu, diễn đạt lại những câu văn khó hiểu và tạo ra các code snippet nhanh. Các bài kiểm tra về viết sáng tạo hay giải tích nâng cao không giúp ích gì.
Cần có một cách để kiểm tra các mô hình hàng đầu cho những nhiệm vụ của bạn, lý tưởng nhất là không biết mô hình nào đang được sử dụng. Sự thiên vị là có thật. Nếu biết đó là Claude hay ChatGPT, bạn có thể vô thức chấm theo thang điểm tương đối.
Cách Chatbot Arena kiểm tra các mô hình AI mà không có sự thiên vị
Điều gì làm cho blind test đáng tin cậy hơn so với các bài đánh giá?
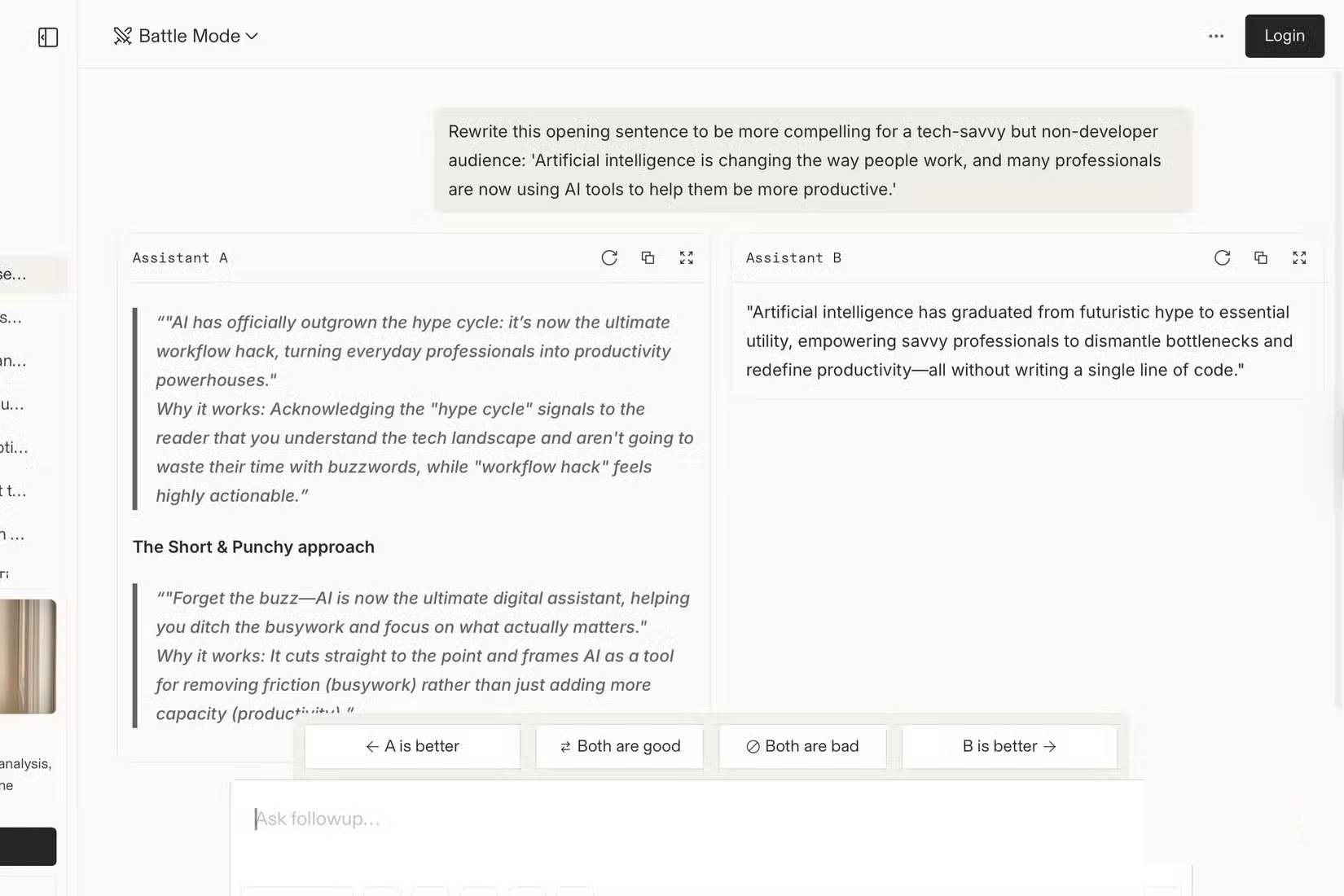
Chatbot Arena của UC Berkeley loại bỏ những phiền toái về tiếp thị. Nhập một prompt và nhận được hai phản hồi AI ẩn danh cạnh nhau. Chọn tùy chọn chiến thắng. Sau khi bỏ phiếu, nền tảng sẽ tiết lộ những mô hình bạn đã so sánh.
Đó chính là blind test. Bạn không thể ưu tiên một thương hiệu mà mình đã trả tiền hoặc một mô hình mà bạn đã quyết định là tốt nhất. Bạn chỉ đang so sánh hai phản hồi với câu hỏi thực tế của mình và chọn phản hồi tốt hơn.
Nền tảng này theo dõi phiếu bầu từ hàng triệu người dùng và xếp hạng các mô hình bằng hệ thống kiểu Elo, giống như cờ vua. Nhưng bảng xếp hạng toàn cầu không phải là điều quan trọng nhất. Hãy chạy các tác vụ của riêng bạn và xem mô hình nào phù hợp nhất với mình.
Nó miễn phí, không cần tài khoản để bắt đầu và chỉ mất khoảng 30 phút để có được đánh giá chính xác về mô hình nào phù hợp với quy trình làm việc của bạn.
Những gì đã xảy ra?
Thực hiện 40 lượt blind test giữa các AI về những nhiệm vụ viết thực tế
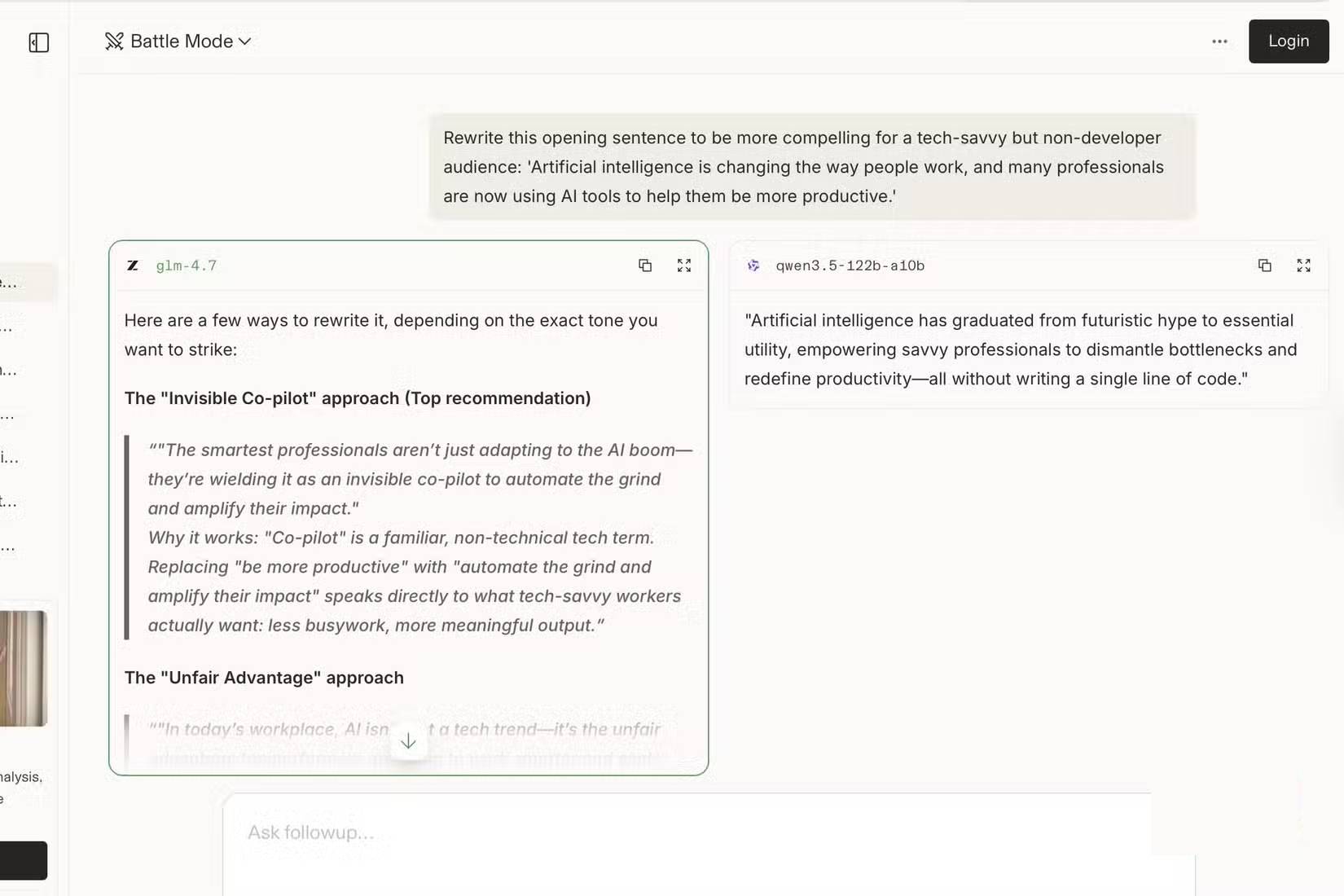
Tác giả đã thực hiện 4 loại nhiệm vụ gặp phải trong công việc thực tế hàng tuần, với 10 lượt so sánh cho mỗi loại:
- Viết và biên tập: Các đoạn văn bản nháp được gửi để chỉnh sửa.
- Tóm tắt nghiên cứu: Các đoạn văn bản kỹ thuật dài được gửi để tóm tắt rõ ràng, dễ đọc.
- Tạo tiêu đề và tựa đề: Với một chủ đề và góc nhìn bài viết, mô hình nào tạo ra các lựa chọn hấp dẫn nhất?
- Giải thích các chủ đề phức tạp một cách đơn giản: Lấy một thứ kỹ thuật và làm cho nó dễ hiểu mà không làm giảm độ phức tạp. Một kỹ năng cốt lõi cho bất kỳ ai viết về công nghệ.
Trên cả 4 nhiệm vụ, Claude đã giành chiến thắng. Với 40 vòng thử nghiệm, đó là kết quả khá chính xác mà loại thử nghiệm này có thể mang lại.
Gemini 3.1 Pro Preview đứng thứ hai. Nhìn chung, nó xếp sau Claude, một mô hình luôn được cải tiến, nhưng lại là mô hình duy nhất thường xuyên cạnh tranh được với Claude. Trong một vài bài kiểm tra viết và tóm tắt, khoảng cách khá hẹp khiến tác giả phải lưỡng lự trước khi bỏ phiếu. Nếu là người dùng Gemini thường xuyên, bạn không đưa ra lựa chọn tồi; chỉ là đó không phải lựa chọn tốt nhất, ít nhất là đối với các tác vụ liên quan đến viết lách.
Với kết quả lập trình, phản hồi của Claude sạch sẽ hơn, có cấu trúc tốt hơn và hoạt động ngay từ lần thử đầu tiên mà không cần sửa lỗi thư viện "ảo" hoặc cú pháp bị hỏng.
Điều bất ngờ lớn nhất là các "tên tuổi lớn" không phải lúc nào cũng giữ vững phong độ. Ngay cả khi bao gồm GPT-4o, chỉ có Claude và Gemini luôn dẫn đầu. Các mô hình khác đôi khi cũng hoạt động tốt, nhưng hai mô hình này đã vượt trội hơn trong những tác vụ chuyên môn.
Cách tìm chatbot AI tốt nhất cho các tác vụ cụ thể của bạn
4 quy tắc giúp kết quả của bạn thực sự có ý nghĩa
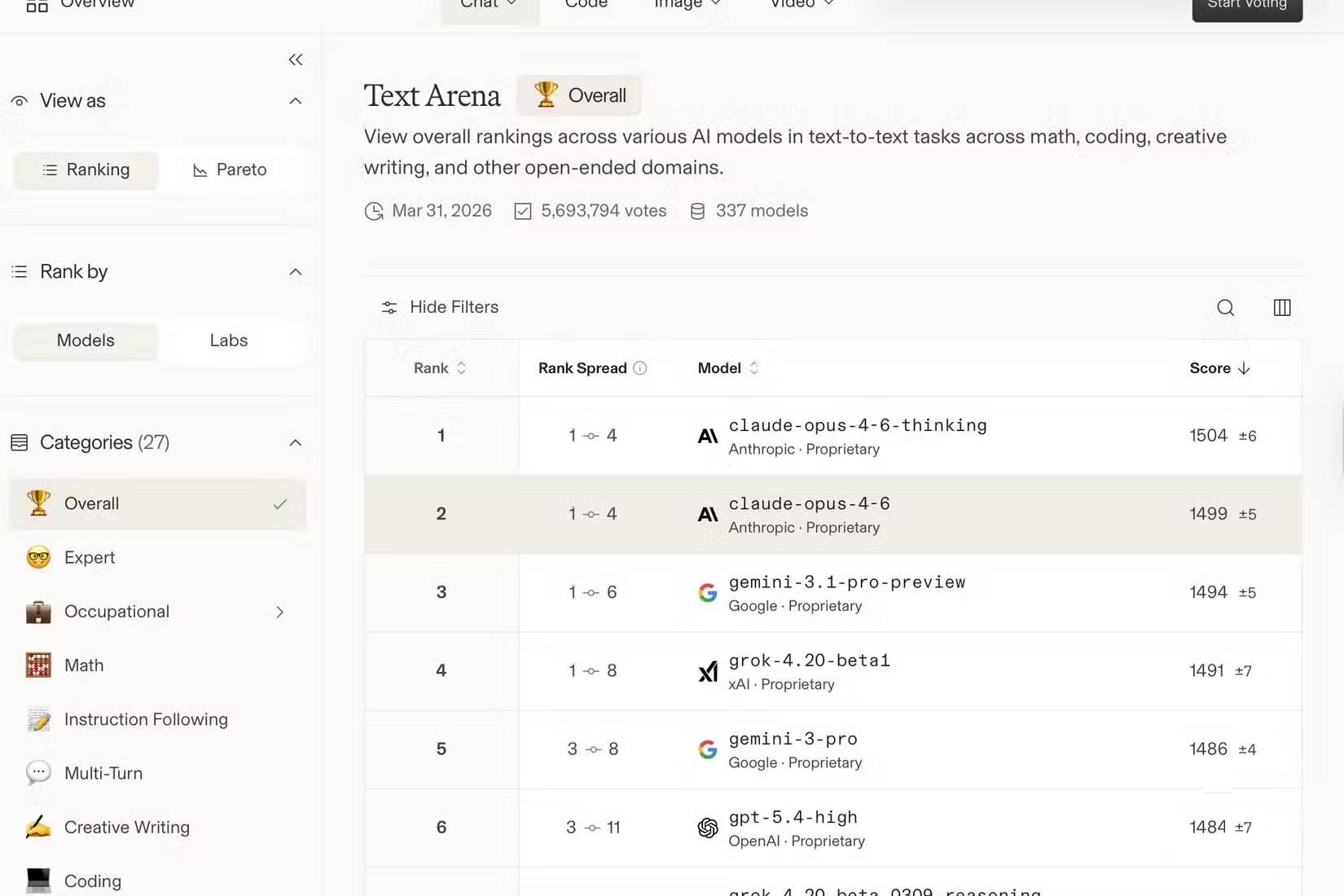
Hãy truy cập arena.ai và sử dụng các prompt từ công việc thực tế. Đừng dựa vào các tình huống giả định. Thay vào đó, hãy dán một email thực tế bạn cần viết lại, một tài liệu thực tế cần tóm tắt hoặc một vấn đề thực tế cần giải quyết.
- Số lượng chạy: Hãy đặt mục tiêu ít nhất 8 - 10 lần ghép cặp cho mỗi loại nhiệm vụ trước khi quyết định. Những lần ghép cặp đơn lẻ sẽ gây nhiễu; các mẫu sẽ xuất hiện khi số lượng chạy nhiều.
- Theo dõi thủ công: Hãy ghi lại kết quả một cách đơn giản bằng cách sử dụng các ứng dụng như Apple Notes, giấy ghi chú, hoặc bất cứ thứ gì tương tự. Chatbot Arena không tạo ra bản tóm tắt kết quả cá nhân, vì vậy việc ghi nhật ký thủ công là cách tốt nhất.
- Hãy tin tưởng vào sự do dự của bạn: Hãy chú ý khi bạn do dự trước khi bỏ phiếu. Điều này thường có nghĩa là các mô hình đang tiến gần đến kết quả tốt nhất cho nhiệm vụ đó, hữu ích ngay cả khi không có tùy chọn chiến thắng rõ ràng.
Việc này có thể mất một chút thời gian, nhưng rất đáng giá.
Phương pháp mới là thứ chiến thắng thực sự
Mặc dù bảng xếp hạng toàn cầu có thể tạo ra tranh luận, nhưng chính việc thử nghiệm cá nhân mới quyết định mô hình AI nào thực sự tối đa hóa năng suất của bạn.
40 lần so sánh blind test với công việc thực tế sẽ cho bạn một câu trả lời rõ ràng: Claude Opus 4.6 hoạt động tốt nhất cho các nhiệm vụ thực tế.
Tuy nhiên, có một lưu ý quan trọng: Tốc độ. Trong thế giới AI, mô hình "tốt nhất" là một mục tiêu luôn thay đổi. Các mô hình này liên tục được cập nhật; những gì dẫn đầu ngày hôm nay có thể trở nên lỗi thời trong 30 ngày hoặc thậm chí 6 tháng sau. Hôm nay, Claude là người chiến thắng, nhưng điều tuyệt vời của Chatbot Arena là bạn có thể chạy lại toàn bộ thí nghiệm này vào tháng tới để xem liệu bản cập nhật Gemini mới hay bản phát hành GPT bất ngờ nào đó có vượt trội hơn không.
Tóm lại, blind test không chỉ đơn thuần là xác nhận. Nó còn là việc luôn sẵn sàng khám phá những sở thích mới khi các mô hình phát triển.








 Hướng dẫn AI
Hướng dẫn AI
 Ứng dụng
Ứng dụng
 Hệ thống
Hệ thống
 Game - Trò chơi
Game - Trò chơi
 iPhone
iPhone
 Android
Android
 Làng Công nghệ
Làng Công nghệ
 Hàm Excel
Hàm Excel
 Cuộc sống
Cuộc sống
 Khoa học
Khoa học